Unmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
2307.05360
0
0
📊
Abstract
The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
Create account to get full access
Overview
- The paper explores the coding capabilities of the large language model ChatGPT, which has demonstrated remarkable performance in multi-turn conversations and exhibited proficiency in various programming languages.
- The researchers conducted a comprehensive evaluation of ChatGPT's abilities in the Python programming language, focusing on data structures and algorithms, which are fundamental topics in Computer Science.
- The evaluation assessed ChatGPT's ability to generate correct solutions, the quality of its code, and the nature of runtime errors encountered.
- The researchers also investigated whether ChatGPT might have directly memorized some of the training data used to develop it.
- Comparisons were made with human performance whenever feasible, considering both the GPT-3.5 and GPT-4 underlying models, across a wide range of sub-topics and difficulty levels.
Plain English Explanation
Large language models (LLMs), such as ChatGPT, are transforming the field of Artificial Intelligence (AI) by demonstrating remarkable capabilities in various tasks, including natural language processing and code generation. In this research paper, the authors focused on evaluating the coding abilities of ChatGPT, specifically in the Python programming language and topics related to data structures and algorithms.
The researchers conducted a comprehensive assessment of ChatGPT's performance, looking at its ability to generate correct solutions to coding challenges, the quality of the code it produced, and the types of runtime errors it encountered. They also investigated whether ChatGPT might have simply memorized some of the training data used to develop it, rather than genuinely understanding and applying the underlying concepts.
To make the comparisons more meaningful, the researchers looked at ChatGPT's performance across a wide range of sub-topics and difficulty levels, and made comparisons with human performance whenever possible. This allowed them to gain insights into the strengths and limitations of ChatGPT's coding abilities, as well as how they might differ between the GPT-3.5 and GPT-4 underlying models.
Technical Explanation
The researchers conducted a comprehensive evaluation of ChatGPT's coding capabilities, focusing on the Python programming language and topics related to data structures and algorithms. They assessed ChatGPT's ability to generate correct solutions to coding challenges, the quality of the code it produced, and the types of runtime errors it encountered.
To investigate whether ChatGPT might have directly memorized some of the training data used to develop it, the researchers designed a systematic experiment to explore this phenomenon. They also conducted comparisons with human performance whenever feasible, considering both the GPT-3.5 and GPT-4 underlying models, across a wide range of sub-topics and difficulty levels.
The researchers used a large catalog of coding challenges to evaluate ChatGPT's performance, allowing them to gain insights into the strengths and limitations of its coding abilities. They also looked at patterns in the test cases passed to understand how ChatGPT's code might fail to solve the problems correctly, even when it successfully executed.
Critical Analysis
The researchers acknowledged several caveats and limitations in their study. For instance, they noted that their evaluation was limited to the Python programming language and topics related to data structures and algorithms, and that further research would be needed to investigate ChatGPT's capabilities in other programming languages and domains.
Additionally, the researchers highlighted the need for more research to understand the underlying mechanisms and decision-making processes of large language models like ChatGPT, as this could provide valuable insights into their strengths, weaknesses, and potential biases.
While the researchers conducted a thorough evaluation, there may be other factors or experimental designs that could have provided additional insights into ChatGPT's coding abilities. For example, the researchers did not explore the potential impact of task formulation or prompting on ChatGPT's performance, which could be an interesting area for future research.
Conclusion
This comprehensive study on the coding capabilities of ChatGPT provides valuable insights into the current state of large language models and their potential applications in the field of computer science. The researchers' findings suggest that ChatGPT has remarkable abilities in generating code and solving coding challenges, but also highlight areas where it may struggle or exhibit limitations.
The implications of this research extend beyond the technical realm, as it raises questions about the role of AI in programming and the potential impact on the software development industry. As large language models continue to evolve, it will be crucial for researchers, developers, and the broader community to engage in ongoing evaluation and critical analysis to ensure these technologies are leveraged responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Analyzing Chat Protocols of Novice Programmers Solving Introductory Programming Tasks with ChatGPT
Andreas Scholl, Daniel Schiffner, Natalie Kiesler
0
0
Large Language Models (LLMs) have taken the world by storm, and students are assumed to use related tools at a great scale. In this research paper we aim to gain an understanding of how introductory programming students chat with LLMs and related tools, e.g., ChatGPT-3.5. To address this goal, computing students at a large German university were motivated to solve programming exercises with the assistance of ChatGPT as part of their weekly introductory course exercises. Then students (n=213) submitted their chat protocols (with 2335 prompts in sum) as data basis for this analysis. The data was analyzed w.r.t. the prompts, frequencies, the chats' progress, contents, and other use pattern, which revealed a great variety of interactions, both potentially supportive and concerning. Learning about students' interactions with ChatGPT will help inform and align teaching practices and instructions for future introductory programming courses in higher education.
5/30/2024
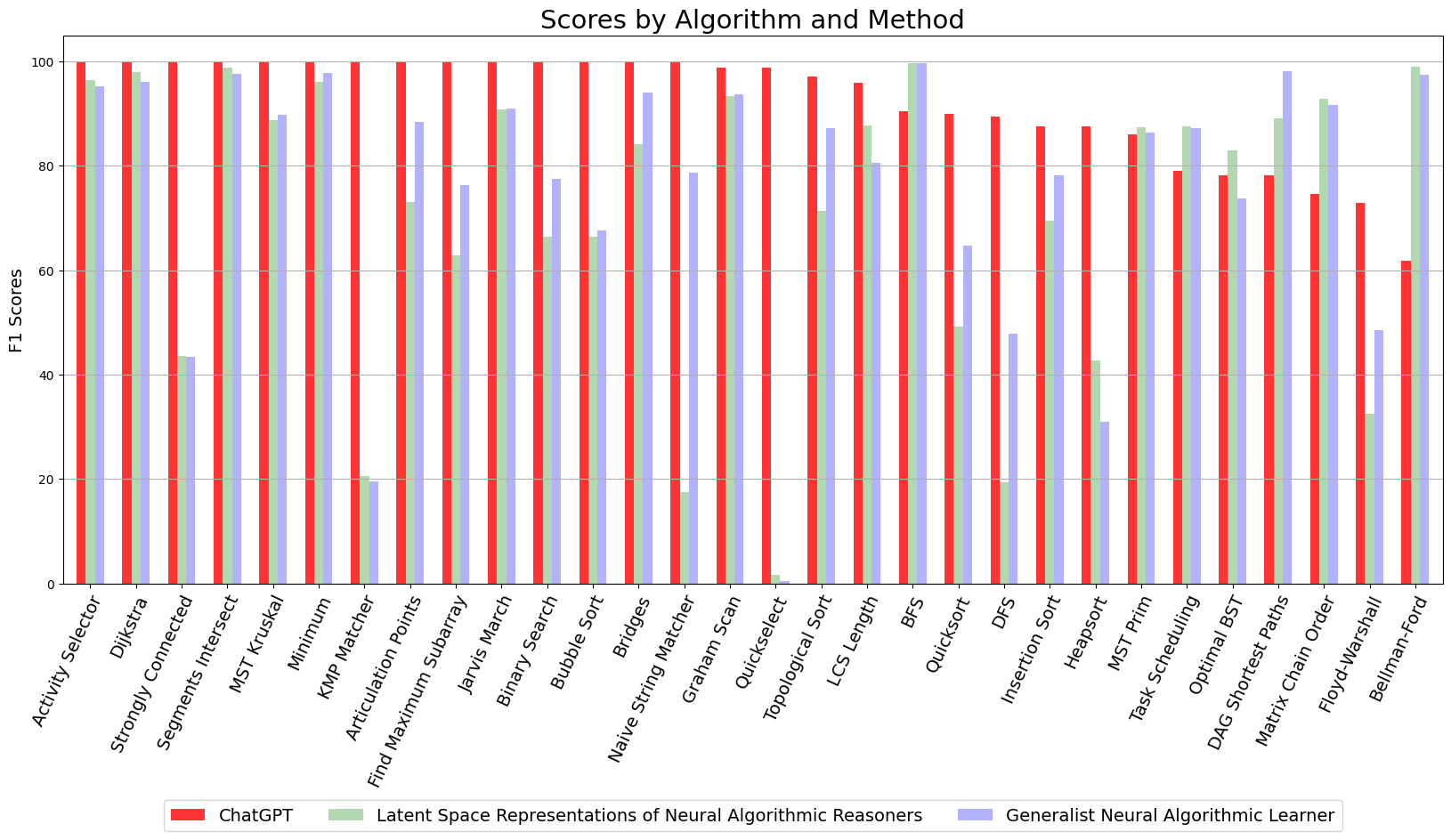
Benchmarking ChatGPT on Algorithmic Reasoning
Sean McLeish, Avi Schwarzschild, Tom Goldstein
0
0
We evaluate ChatGPT's ability to solve algorithm problems from the CLRS benchmark suite that is designed for GNNs. The benchmark requires the use of a specified classical algorithm to solve a given problem. We find that ChatGPT outperforms specialist GNN models, using Python to successfully solve these problems. This raises new points in the discussion about learning algorithms with neural networks.
4/5/2024
💬
ChatGPT as an inventor: Eliciting the strengths and weaknesses of current large language models against humans in engineering design
Daniel Nyg{aa}rd Ege, Henrik H. {O}vreb{o}, Vegar Stubberud, Martin Francis Berg, Christer Elverum, Martin Steinert, H{aa}vard Vestad
0
0
This study compares the design practices and performance of ChatGPT 4.0, a large language model (LLM), against graduate engineering students in a 48-hour prototyping hackathon, based on a dataset comprising more than 100 prototypes. The LLM participated by instructing two participants who executed its instructions and provided objective feedback, generated ideas autonomously and made all design decisions without human intervention. The LLM exhibited similar prototyping practices to human participants and finished second among six teams, successfully designing and providing building instructions for functional prototypes. The LLM's concept generation capabilities were particularly strong. However, the LLM prematurely abandoned promising concepts when facing minor difficulties, added unnecessary complexity to designs, and experienced design fixation. Communication between the LLM and participants was challenging due to vague or unclear descriptions, and the LLM had difficulty maintaining continuity and relevance in answers. Based on these findings, six recommendations for implementing an LLM like ChatGPT in the design process are proposed, including leveraging it for ideation, ensuring human oversight for key decisions, implementing iterative feedback loops, prompting it to consider alternatives, and assigning specific and manageable tasks at a subsystem level.
4/30/2024

The Battle of LLMs: A Comparative Study in Conversational QA Tasks
Aryan Rangapur, Aman Rangapur
0
0
Large language models have gained considerable interest for their impressive performance on various tasks. Within this domain, ChatGPT and GPT-4, developed by OpenAI, and the Gemini, developed by Google, have emerged as particularly popular among early adopters. Additionally, Mixtral by Mistral AI and Claude by Anthropic are newly released, further expanding the landscape of advanced language models. These models are viewed as disruptive technologies with applications spanning customer service, education, healthcare, and finance. More recently, Mistral has entered the scene, captivating users with its unique ability to generate creative content. Understanding the perspectives of these users is crucial, as they can offer valuable insights into the potential strengths, weaknesses, and overall success or failure of these technologies in various domains. This research delves into the responses generated by ChatGPT, GPT-4, Gemini, Mixtral and Claude across different Conversational QA corpora. Evaluation scores were meticulously computed and subsequently compared to ascertain the overall performance of these models. Our study pinpointed instances where these models provided inaccurate answers to questions, offering insights into potential areas where they might be susceptible to errors. In essence, this research provides a comprehensive comparison and evaluation of these state of-the-art language models, shedding light on their capabilities while also highlighting potential areas for improvement
5/29/2024