Does SGD really happen in tiny subspaces?

0
🏷️
Sign in to get full access
Overview
- Examines the training dynamics of deep neural networks, which are challenging to understand due to their high-dimensional nature and complex loss landscapes
- Focuses on the observation that the gradient during training aligns with a low-rank top eigenspace of the training loss Hessian, known as the dominant subspace
- Explores whether neural networks can be trained within this dominant subspace, which could lead to more efficient training methods
Plain English Explanation
Deep neural networks are incredibly powerful machine learning models, but understanding how they are trained can be quite complex. Recent research has found that during the training process, the gradient (the direction the model should update its parameters to reduce the loss) tends to align with a specific low-dimensional subspace of the high-dimensional loss landscape, called the dominant subspace.
This paper investigates whether it's possible to train neural networks by only updating the model within this dominant subspace, rather than the full high-dimensional space. The idea is that if the gradient is already aligned with this subspace, then restricting the updates to this space could potentially lead to more efficient training.
However, the key finding is that when the update is projected onto the dominant subspace, the training loss doesn't decrease any further. This suggests that the observed alignment between the gradient and the dominant subspace is not actually helping the training process, and is just a coincidental phenomenon.
Surprisingly, the paper also shows that removing the dominant subspace component from the update is just as effective as the original full update, even though this removes the majority of the original update direction. Similar observations are made for training regimes like large learning rates and Sharpness-Aware Minimization.
The authors discuss possible reasons for this "spurious alignment" and what it reveals about the complex dynamics of how neural networks are trained.
Technical Explanation
The paper begins by noting the challenge of understanding the training dynamics of deep neural networks due to their high-dimensional nature and intricate loss landscapes. Recent studies have observed that during training, the gradient approximately aligns with a low-rank top eigenspace of the training loss Hessian, referred to as the dominant subspace.
To explore whether neural networks can be trained within this dominant subspace, the authors conduct experiments projecting the Stochastic Gradient Descent (SGD) update onto the dominant subspace. Their primary observation is that when the SGD update is projected onto the dominant subspace, the training loss does not decrease further. This suggests that the observed alignment between the gradient and the dominant subspace is "spurious" - it does not actually help the training process.
Surprisingly, the authors find that projecting out the dominant subspace from the SGD update is just as effective as the original full update, despite removing the majority of the original update component. Similar observations are made for the large learning rate regime (also known as Edge of Stability) and Sharpness-Aware Minimization.
The paper discusses possible causes for this spurious alignment, such as the relationship between the dominant subspace and the implicit regularization of neural networks, as well as the fundamental limits of weak learnability in high-dimensional settings. The authors also explore the implications of these findings, shedding light on the intricate dynamics of neural network training.
Critical Analysis
The paper presents a thoughtful and rigorous investigation into the observed alignment between the gradient and the dominant subspace of the training loss Hessian. The authors are careful to qualify their findings, acknowledging that the reasons for this "spurious alignment" are not fully understood and require further research.
One potential limitation of the study is that it focuses primarily on the training loss, rather than the generalization performance of the models. It's possible that the dominant subspace could still play a role in shaping the learned representations or the final model performance, even if it doesn't directly influence the training dynamics.
Additionally, the paper's findings raise questions about the broader interpretability and understanding of neural network training. If the alignment between the gradient and the dominant subspace is not fundamental to the training process, it suggests that our current theoretical frameworks may be missing important aspects of how these models learn.
Overall, this paper makes a valuable contribution to the ongoing efforts to visualize and rethink the loss landscape of deep neural networks. By challenging a commonly observed phenomenon, the authors encourage the community to think more critically about the complex dynamics underlying neural network training.
Conclusion
This paper challenges the prevailing view that the alignment between the gradient and the dominant subspace of the training loss Hessian is a key factor in the training dynamics of deep neural networks. The authors' primary finding is that restricting the updates to the dominant subspace does not lead to further reduction in the training loss, suggesting that this alignment is "spurious" and not fundamentally tied to the training process.
These surprising results shed light on the intricate and often counterintuitive nature of how neural networks learn. The paper's critical analysis of this phenomenon encourages the research community to continue exploring the complex loss landscapes and training dynamics of deep models, with the goal of developing a more comprehensive understanding of these powerful machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Does SGD really happen in tiny subspaces?
Minhak Song, Kwangjun Ahn, Chulhee Yun
Understanding the training dynamics of deep neural networks is challenging due to their high-dimensional nature and intricate loss landscapes. Recent studies have revealed that, along the training trajectory, the gradient approximately aligns with a low-rank top eigenspace of the training loss Hessian, referred to as the dominant subspace. Given this alignment, this paper explores whether neural networks can be trained within the dominant subspace, which, if feasible, could lead to more efficient training methods. Our primary observation is that when the SGD update is projected onto the dominant subspace, the training loss does not decrease further. This suggests that the observed alignment between the gradient and the dominant subspace is spurious. Surprisingly, projecting out the dominant subspace proves to be just as effective as the original update, despite removing the majority of the original update component. Similar observations are made for the large learning rate regime (also known as Edge of Stability) and Sharpness-Aware Minimization. We discuss the main causes and implications of this spurious alignment, shedding light on the intricate dynamics of neural network training.
Read more5/28/2024
🗣️
0
There is a Singularity in the Loss Landscape
Mark Lowell
Despite the widespread adoption of neural networks, their training dynamics remain poorly understood. We show experimentally that as the size of the dataset increases, a point forms where the magnitude of the gradient of the loss becomes unbounded. Gradient descent rapidly brings the network close to this singularity in parameter space, and further training takes place near it. This singularity explains a variety of phenomena recently observed in the Hessian of neural network loss functions, such as training on the edge of stability and the concentration of the gradient in a top subspace. Once the network approaches the singularity, the top subspace contributes little to learning, even though it constitutes the majority of the gradient.
Read more7/23/2024
🔗
0
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Feng Chen, Daniel Kunin, Atsushi Yamamura, Surya Ganguli
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
Read more5/30/2024
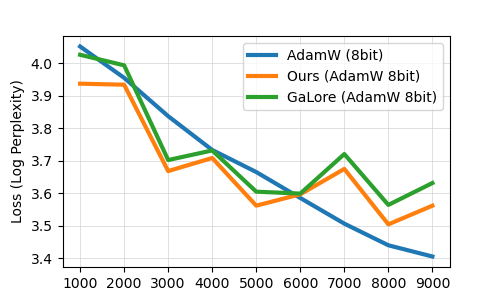
0
Memory-Efficient LLM Training with Online Subspace Descent
Kaizhao Liang, Bo Liu, Lizhang Chen, Qiang Liu
Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream tasks performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
Read more8/26/2024