Memory-Efficient LLM Training with Online Subspace Descent

0
Sign in to get full access
Overview
- This paper presents a memory-efficient training method for large language models (LLMs) called Online Subspace Descent (OSD).
- OSD leverages the low-rank structure of LLM parameters to significantly reduce the memory footprint during training.
- The method outperforms standard training approaches in terms of memory usage while maintaining comparable model performance.
Plain English Explanation
The task of training large language models (LLMs) is extremely memory-intensive, often requiring massive amounts of GPU memory. This paper introduces a new training method called Online Subspace Descent (OSD) that can greatly reduce the memory requirements.
The key insight is that the parameters of LLMs often have a low-rank structure, meaning they can be well-approximated using a small number of underlying "directions" or basis vectors. OSD exploits this by representing the model parameters as a sum of these low-rank components, rather than storing the full, high-dimensional parameter tensors.
This low-rank representation allows OSD to perform training updates efficiently in a memory-friendly way. Instead of updating the full parameter tensors, OSD only needs to update the much smaller set of basis vectors. This results in a significant reduction in memory usage compared to standard training approaches, while still maintaining the model's performance.
Technical Explanation
The paper introduces the Online Subspace Descent (OSD) algorithm for memory-efficient training of large language models (LLMs). The key insight is that the parameters of LLMs often exhibit a low-rank structure, meaning they can be well-approximated using a small number of underlying "directions" or basis vectors.
OSD leverages this low-rank structure by representing the model parameters as a sum of these low-rank components. During training, OSD performs updates to the basis vectors instead of the full high-dimensional parameter tensors. This allows for a significant reduction in memory usage compared to standard training approaches, such as stochastic gradient descent (SGD).
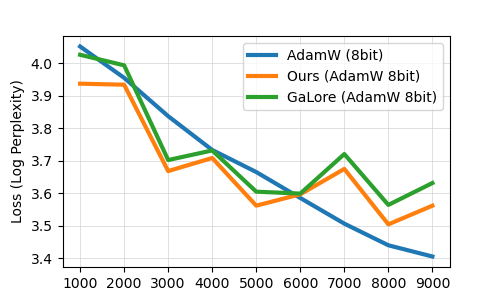
The paper demonstrates that OSD can achieve comparable model performance to SGD while using much less memory. Experiments on language modeling and machine translation tasks show that OSD can reduce the memory footprint by up to 5x without sacrificing model quality.
The authors also provide theoretical analysis to show that the low-rank structure of LLM parameters can be effectively captured by the OSD method. They prove that OSD can converge to an approximate solution that is close to the optimal full-rank solution, justifying the practical efficacy of the approach.
Critical Analysis
The paper presents a compelling approach to reducing the memory requirements of LLM training, which is a crucial challenge in the field. The use of low-rank matrix approximations is a well-established technique in machine learning, and the authors show how it can be effectively applied to the training of large language models.
One potential limitation of the OSD method is that it may not capture the full complexity of the model parameters, as the low-rank representation could introduce some information loss. The authors address this by providing theoretical guarantees on the quality of the approximate solution, but it would be valuable to further investigate the practical implications of this trade-off in different application scenarios.
Additionally, the paper focuses on the memory efficiency of the training process, but does not explicitly explore the computational efficiency. It would be interesting to understand the impact of the low-rank updates on the overall training time and convergence speed compared to standard SGD methods.
Overall, the OSD approach presented in this paper is a promising step towards more memory-efficient training of large language models, and the ideas could potentially be extended to other types of deep neural networks as well.
Conclusion
This paper introduces a memory-efficient training method called Online Subspace Descent (OSD) for large language models (LLMs). By exploiting the low-rank structure of LLM parameters, OSD can significantly reduce the memory footprint of the training process while maintaining comparable model performance to standard approaches.
The key innovation of OSD is the representation of model parameters as a sum of low-rank components, which allows for efficient updates to the basis vectors instead of the full high-dimensional tensors. This leads to substantial memory savings, as demonstrated in the paper's experiments on language modeling and machine translation tasks.
The OSD method has the potential to enable the training of larger and more complex LLMs by addressing the critical challenge of memory constraints. As the field of natural language processing continues to push the boundaries of model size and capability, techniques like OSD will become increasingly important for making this progress sustainable and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Memory-Efficient LLM Training with Online Subspace Descent
Kaizhao Liang, Bo Liu, Lizhang Chen, Qiang Liu
Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream tasks performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
Read more8/26/2024
0
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
Roy Miles, Pradyumna Reddy, Ismail Elezi, Jiankang Deng
Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
Read more5/29/2024
🤿
0
Subspace Representation Learning for Sparse Linear Arrays to Localize More Sources than Sensors: A Deep Learning Methodology
Kuan-Lin Chen, Bhaskar D. Rao
Localizing more sources than sensors with a sparse linear array (SLA) has long relied on minimizing a distance between two covariance matrices and recent algorithms often utilize semidefinite programming (SDP). Although deep neural network (DNN)-based methods offer new alternatives, they still depend on covariance matrix fitting. In this paper, we develop a novel methodology that estimates the co-array subspaces from a sample covariance for SLAs. Our methodology trains a DNN to learn signal and noise subspace representations that are invariant to the selection of bases. To learn such representations, we propose loss functions that gauge the separation between the desired and the estimated subspace. In particular, we propose losses that measure the length of the shortest path between subspaces viewed on a union of Grassmannians, and prove that it is possible for a DNN to approximate signal subspaces. The computation of learning subspaces of different dimensions is accelerated by a new batch sampling strategy called consistent rank sampling. The methodology is robust to array imperfections due to its geometry-agnostic and data-driven nature. In addition, we propose a fully end-to-end gridless approach that directly learns angles to study the possibility of bypassing subspace methods. Numerical results show that learning such subspace representations is more beneficial than learning covariances or angles. It outperforms conventional SDP-based methods such as the sparse and parametric approach (SPA) and existing DNN-based covariance reconstruction methods for a wide range of signal-to-noise ratios (SNRs), snapshots, and source numbers for both perfect and imperfect arrays.
Read more8/30/2024
🏷️
0
Does SGD really happen in tiny subspaces?
Minhak Song, Kwangjun Ahn, Chulhee Yun
Understanding the training dynamics of deep neural networks is challenging due to their high-dimensional nature and intricate loss landscapes. Recent studies have revealed that, along the training trajectory, the gradient approximately aligns with a low-rank top eigenspace of the training loss Hessian, referred to as the dominant subspace. Given this alignment, this paper explores whether neural networks can be trained within the dominant subspace, which, if feasible, could lead to more efficient training methods. Our primary observation is that when the SGD update is projected onto the dominant subspace, the training loss does not decrease further. This suggests that the observed alignment between the gradient and the dominant subspace is spurious. Surprisingly, projecting out the dominant subspace proves to be just as effective as the original update, despite removing the majority of the original update component. Similar observations are made for the large learning rate regime (also known as Edge of Stability) and Sharpness-Aware Minimization. We discuss the main causes and implications of this spurious alignment, shedding light on the intricate dynamics of neural network training.
Read more5/28/2024