Modeling Bilingual Sentence Processing: Evaluating RNN and Transformer Architectures for Cross-Language Structural Priming
2405.09508
0
0

Abstract
This study evaluates the performance of Recurrent Neural Network (RNN) and Transformer in replicating cross-language structural priming: a key indicator of abstract grammatical representations in human language processing. Focusing on Chinese-English priming, which involves two typologically distinct languages, we examine how these models handle the robust phenomenon of structural priming, where exposure to a particular sentence structure increases the likelihood of selecting a similar structure subsequently. Additionally, we utilize large language models (LLM) to measure the cross-lingual structural priming effect. Our findings indicate that Transformer outperform RNN in generating primed sentence structures, challenging the conventional belief that human sentence processing primarily involves recurrent and immediate processing and suggesting a role for cue-based retrieval mechanisms. Overall, this work contributes to our understanding of how computational models may reflect human cognitive processes in multilingual contexts.
Create account to get full access
Overview
- This paper examines how well different neural network architectures, specifically Recurrent Neural Networks (RNNs) and Transformer models, can capture the phenomenon of cross-language structural priming in bilingual sentence processing.
- Structural priming refers to the tendency for people to reuse syntactic structures they have recently encountered, even across languages.
- The researchers compare the ability of RNN and Transformer models to simulate this behavior, which provides insights into the underlying mechanisms of language processing.
Plain English Explanation
When people learn a new language, they often find that the sentence structures they use in their first language can influence how they construct sentences in the second language. This is known as "structural priming." For example, if an English speaker learns a new way to phrase a sentence in German, they may start using that same structure when speaking English again.
This paper looks at how well different types of artificial neural networks can model this cross-language structural priming effect. The researchers trained two main types of models - Recurrent Neural Networks (RNNs) and Transformer models - on bilingual language data and tested their ability to simulate the structural priming phenomenon.
RNNs and Transformers are two common neural network architectures used for language processing tasks. By comparing how well these models captured the structural priming effect, the researchers gained insights into the underlying cognitive mechanisms involved in how people process language, especially when switching between their native and second languages.
Technical Explanation
The paper evaluates the performance of RNN and Transformer architectures in modeling cross-language structural priming during bilingual sentence processing. Structural priming refers to the tendency for speakers to reuse syntactic structures they have recently encountered, even across languages.
The researchers trained RNN and Transformer models on a bilingual corpus, including English and German sentences. They then tested the models' ability to exhibit structural priming by assessing whether the models were more likely to generate target sentences in one language that matched the syntactic structure of previously seen sentences in the other language.
The results showed that both RNN and Transformer models were able to capture the cross-language structural priming effect, but to varying degrees. The Transformer model outperformed the RNN in terms of its ability to accurately simulate the structural priming phenomenon. This suggests that the Transformer architecture may better reflect the underlying cognitive mechanisms involved in bilingual language processing.
The paper provides insights into the relative strengths and limitations of RNN and Transformer models in modeling complex language behaviors, such as the interaction between syntactic processing and cross-language transfer. These findings have implications for the continued development of neural network-based language models and their ability to capture nuanced aspects of human language use.
Critical Analysis
The paper makes a valuable contribution to our understanding of how different neural network architectures can model bilingual language processing, but it also has some limitations that are worth considering.
One potential issue is the use of a relatively small, synthetic dataset for the experiments. While this allowed the researchers to carefully control the experimental conditions, it may not fully capture the complexity and variability of real-world bilingual language use. Expanding the study to include larger, more naturalistic datasets could provide additional insights.
Additionally, the paper focuses solely on structural priming and does not explore other cognitive phenomena that may also be relevant to bilingual language processing, such as lexical or semantic transfer. Investigating a broader range of cross-language effects could further elucidate the strengths and weaknesses of RNN and Transformer models in this domain.
Another area for further research would be to explore the interpretability of the models' internal representations and how they relate to the cognitive processes underlying structural priming. Analyzing the inner workings of Transformer-based language models could shed light on the architectural features that enable the Transformer model's superior performance in this task.
Overall, this paper represents an important step in understanding how transformer and recurrent models compare in language tasks, and how large language models process narrative and syntactic information. Continued research in this area has the potential to improve our models of language learning and processing, with implications for both cognitive science and the development of more sophisticated natural language processing systems.
Conclusion
This paper presents a comparative evaluation of Recurrent Neural Network (RNN) and Transformer architectures in their ability to model cross-language structural priming during bilingual sentence processing. The results suggest that the Transformer model outperforms the RNN in capturing this cognitive phenomenon, providing insights into the underlying mechanisms of language processing.
The findings have important implications for our understanding of how different neural network architectures may reflect the cognitive processes involved in bilingual language use. They also highlight the potential for using these models to gain deeper insights into the complex interplay between syntax, semantics, and cross-language transfer in human language processing.
Overall, this research contributes to the ongoing efforts to understand the strengths and limitations of various language models and their ability to simulate the nuanced aspects of human language behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Do Language Models Exhibit Human-like Structural Priming Effects?
Jaap Jumelet, Willem Zuidema, Arabella Sinclair
0
0
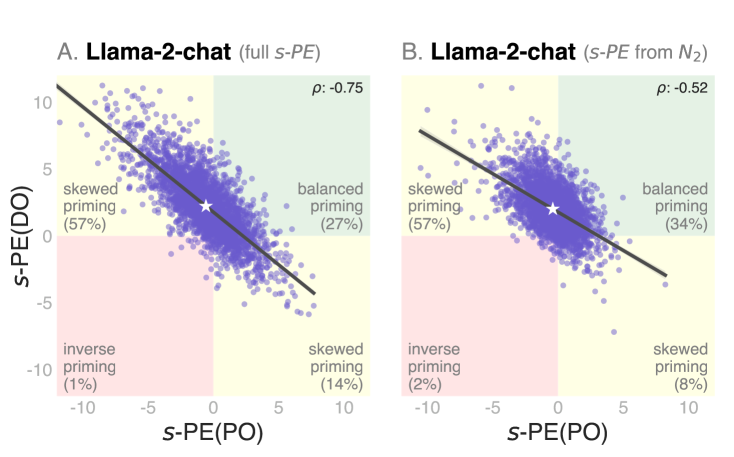
We explore which linguistic factors -- at the sentence and token level -- play an important role in influencing language model predictions, and investigate whether these are reflective of results found in humans and human corpora (Gries and Kootstra, 2017). We make use of the structural priming paradigm, where recent exposure to a structure facilitates processing of the same structure. We don't only investigate whether, but also where priming effects occur, and what factors predict them. We show that these effects can be explained via the inverse frequency effect, known in human priming, where rarer elements within a prime increase priming effects, as well as lexical dependence between prime and target. Our results provide an important piece in the puzzle of understanding how properties within their context affect structural prediction in language models.
6/10/2024
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
0
0
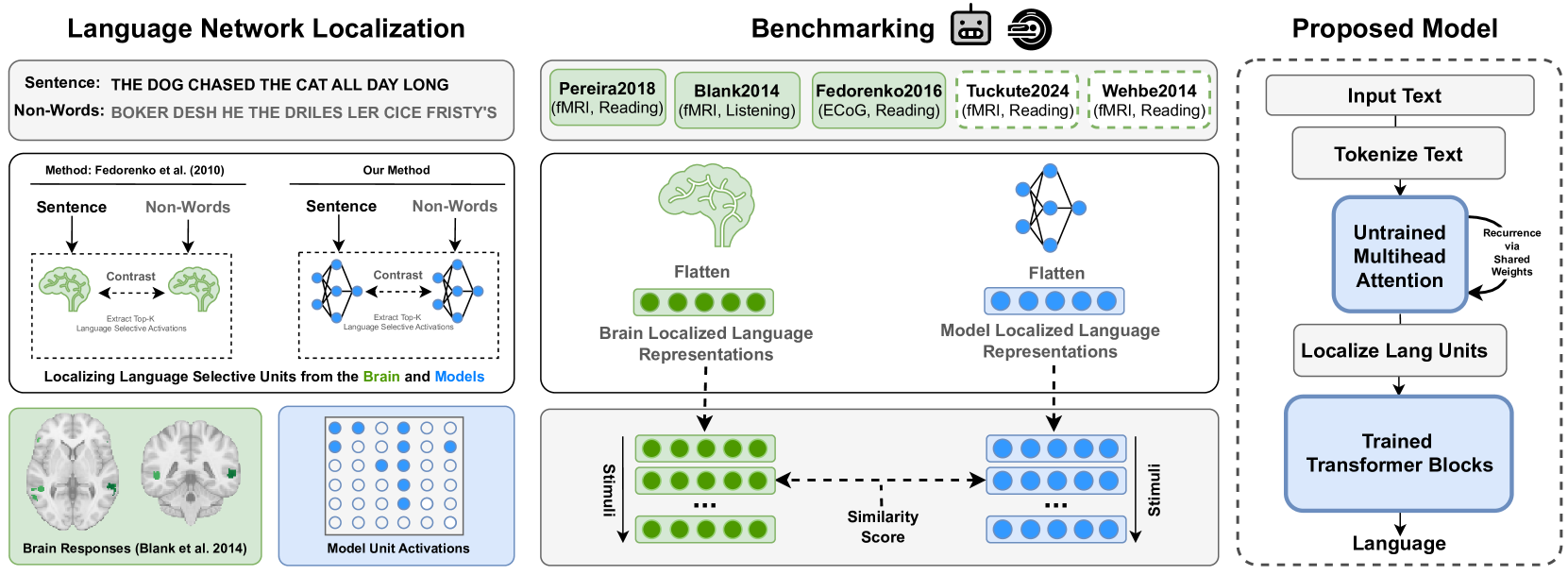
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
6/24/2024
Does Transformer Interpretability Transfer to RNNs?
Gonc{c}alo Paulo, Thomas Marshall, Nora Belrose
0
0
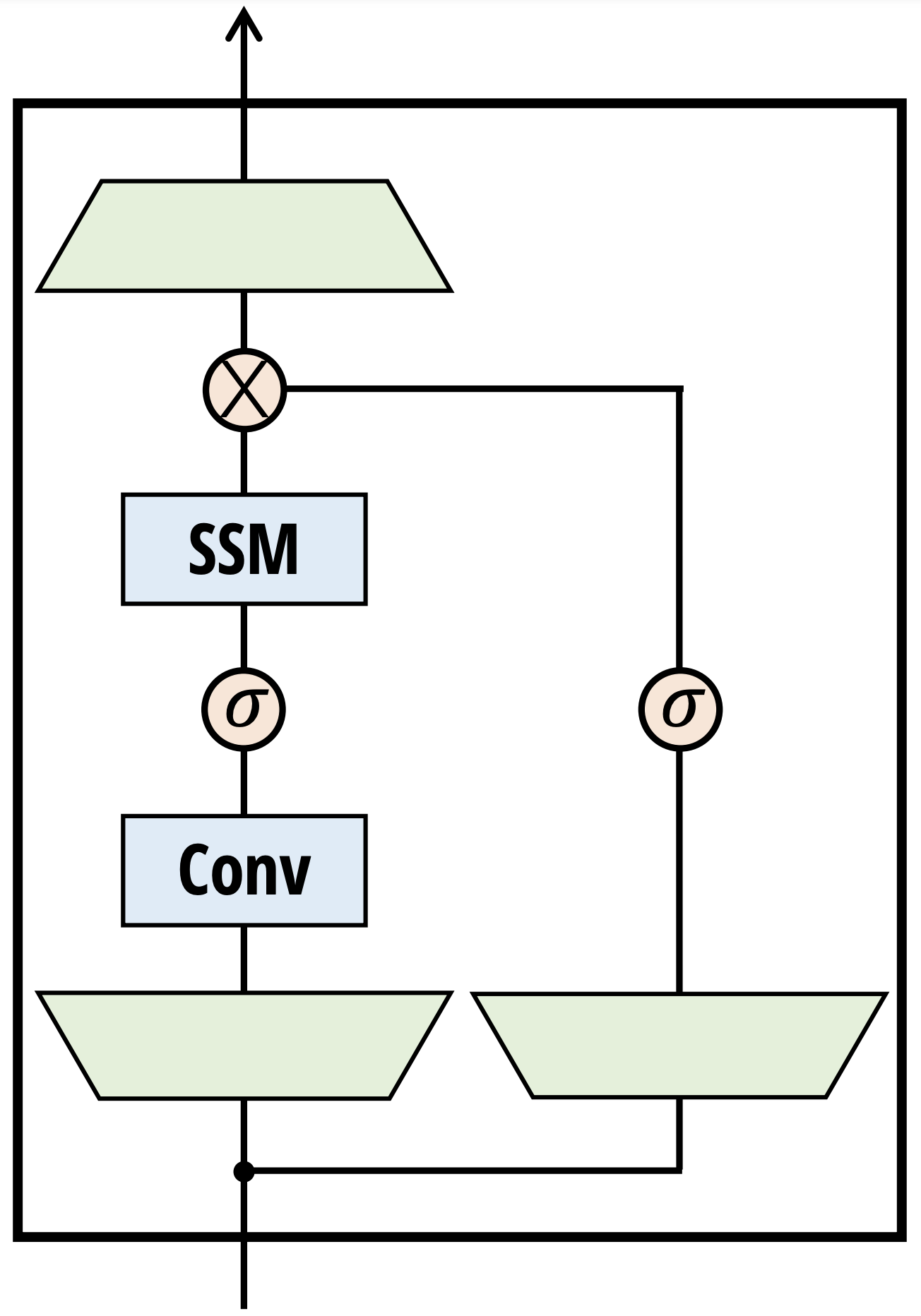
Recent advances in recurrent neural network architectures, such as Mamba and RWKV, have enabled RNNs to match or exceed the performance of equal-size transformers in terms of language modeling perplexity and downstream evaluations, suggesting that future systems may be built on completely new architectures. In this paper, we examine if selected interpretability methods originally designed for transformer language models will transfer to these up-and-coming recurrent architectures. Specifically, we focus on steering model outputs via contrastive activation addition, on eliciting latent predictions via the tuned lens, and eliciting latent knowledge from models fine-tuned to produce false outputs under certain conditions. Our results show that most of these techniques are effective when applied to RNNs, and we show that it is possible to improve some of them by taking advantage of RNNs' compressed state.
4/10/2024
💬
Revenge of the Fallen? Recurrent Models Match Transformers at Predicting Human Language Comprehension Metrics
James A. Michaelov, Catherine Arnett, Benjamin K. Bergen
0
0
Transformers have supplanted Recurrent Neural Networks as the dominant architecture for both natural language processing tasks and, despite criticisms of cognitive implausibility, for modelling the effect of predictability on online human language comprehension. However, two recently developed recurrent neural network architectures, RWKV and Mamba, appear to perform natural language tasks comparably to or better than transformers of equivalent scale. In this paper, we show that contemporary recurrent models are now also able to match - and in some cases, exceed - performance of comparably sized transformers at modeling online human language comprehension. This suggests that transformer language models are not uniquely suited to this task, and opens up new directions for debates about the extent to which architectural features of language models make them better or worse models of human language comprehension.
5/1/2024