Revenge of the Fallen? Recurrent Models Match Transformers at Predicting Human Language Comprehension Metrics
2404.19178
0
0
💬
Abstract
Transformers have supplanted Recurrent Neural Networks as the dominant architecture for both natural language processing tasks and, despite criticisms of cognitive implausibility, for modelling the effect of predictability on online human language comprehension. However, two recently developed recurrent neural network architectures, RWKV and Mamba, appear to perform natural language tasks comparably to or better than transformers of equivalent scale. In this paper, we show that contemporary recurrent models are now also able to match - and in some cases, exceed - performance of comparably sized transformers at modeling online human language comprehension. This suggests that transformer language models are not uniquely suited to this task, and opens up new directions for debates about the extent to which architectural features of language models make them better or worse models of human language comprehension.
Create account to get full access
Overview
- Transformers have become the dominant architecture for natural language processing tasks, replacing Recurrent Neural Networks (RNNs).
- However, two recently developed RNN architectures, RWKV and Mamba, are now able to perform natural language tasks comparably to or better than transformers of equivalent scale.
- The paper suggests that contemporary recurrent models can match or exceed the performance of transformers in modeling online human language comprehension, challenging the notion that transformers are uniquely suited for this task.
Plain English Explanation
The paper discusses how a new type of recurrent neural network (RNN) architecture, called RWKV and Mamba, have been able to match or even outperform the performance of transformers - the dominant architecture for natural language processing tasks - on certain tasks.
Transformers have become the go-to model for working with language data, like understanding and generating text. They've largely replaced older RNN models, which were seen as less effective. However, this paper shows that these newer RNN models can now do just as well, or even better, than transformers at some language-related tasks, including modeling how humans understand and process language in real-time.
This is significant because it suggests that transformers may not be the only architecture suited for language modeling and understanding. It opens up new avenues for research into different model architectures and how they relate to the way humans process language.
Technical Explanation
The paper demonstrates that contemporary recurrent neural network (RNN) architectures, specifically RWKV and Mamba, are now able to match or exceed the performance of comparably sized transformers on the task of modeling online human language comprehension.
Transformers have become the dominant architecture for natural language processing tasks, largely displacing older RNN models. However, the authors show that these newer RNN models, which incorporate novel architectural features, are able to perform on par with or better than transformers of similar scale.
The authors conducted experiments to assess the ability of these RNN models to capture the effects of predictability on online human language comprehension, a task that has historically been viewed as a key strength of transformer models. Their results indicate that the RNN models are able to match or even surpass the performance of transformers on this task, challenging the notion that transformer language models are uniquely suited for modeling human language processing.
These findings suggest that the architectural features that have made transformers successful in natural language processing may not be the only path to effective language modeling. The paper opens up new directions for research and debates around the relationship between model architecture and the ability to capture the cognitive mechanisms underlying human language comprehension.
Critical Analysis
The paper presents an intriguing challenge to the prevailing view that transformer language models are uniquely suited for modeling online human language comprehension. By demonstrating the strong performance of contemporary recurrent neural network (RNN) architectures, the authors raise important questions about the extent to which architectural features determine a model's ability to capture the cognitive processes involved in human language processing.
One potential limitation of the research is the specific task and dataset used to assess the models' performance. While the authors argue that this task is a key benchmark for language models, it would be valuable to see how the RNN models perform on a broader range of human language comprehension tasks and datasets.
Additionally, the paper does not delve deeply into the specific architectural features or training regimes that enable the RNN models to match or exceed transformer performance. Further investigation into the underlying mechanisms driving these models' success could yield important insights for the field.
Despite these caveats, the paper's central finding is significant, as it challenges the assumption that transformer models are uniquely suited for language modeling tasks that were previously seen as transformer strongholds. This work encourages researchers to think more critically about the relationship between model architecture and cognitive plausibility, and to explore alternative approaches to language modeling beyond the transformer paradigm.
Conclusion
This paper presents a surprising and important finding: contemporary recurrent neural network (RNN) architectures, such as RWKV and Mamba, are now able to match or exceed the performance of transformer language models on the task of modeling online human language comprehension.
This challenges the prevailing view that transformers are uniquely suited for language modeling tasks, and opens up new avenues for research into alternative model architectures and their relationship to the cognitive mechanisms underlying human language processing. The findings suggest that the architectural features that have made transformers successful may not be the only path to effective language modeling, and encourage a more critical examination of the connections between model design and cognitive plausibility.
As the field of natural language processing continues to evolve, this research highlights the importance of exploring diverse approaches and not becoming overly reliant on a single dominant paradigm. By considering a broader range of model architectures, researchers may uncover new insights into the nature of human language and cognition, with potentially far-reaching implications for both the scientific understanding and practical applications of language technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Does Transformer Interpretability Transfer to RNNs?
Gonc{c}alo Paulo, Thomas Marshall, Nora Belrose
0
0
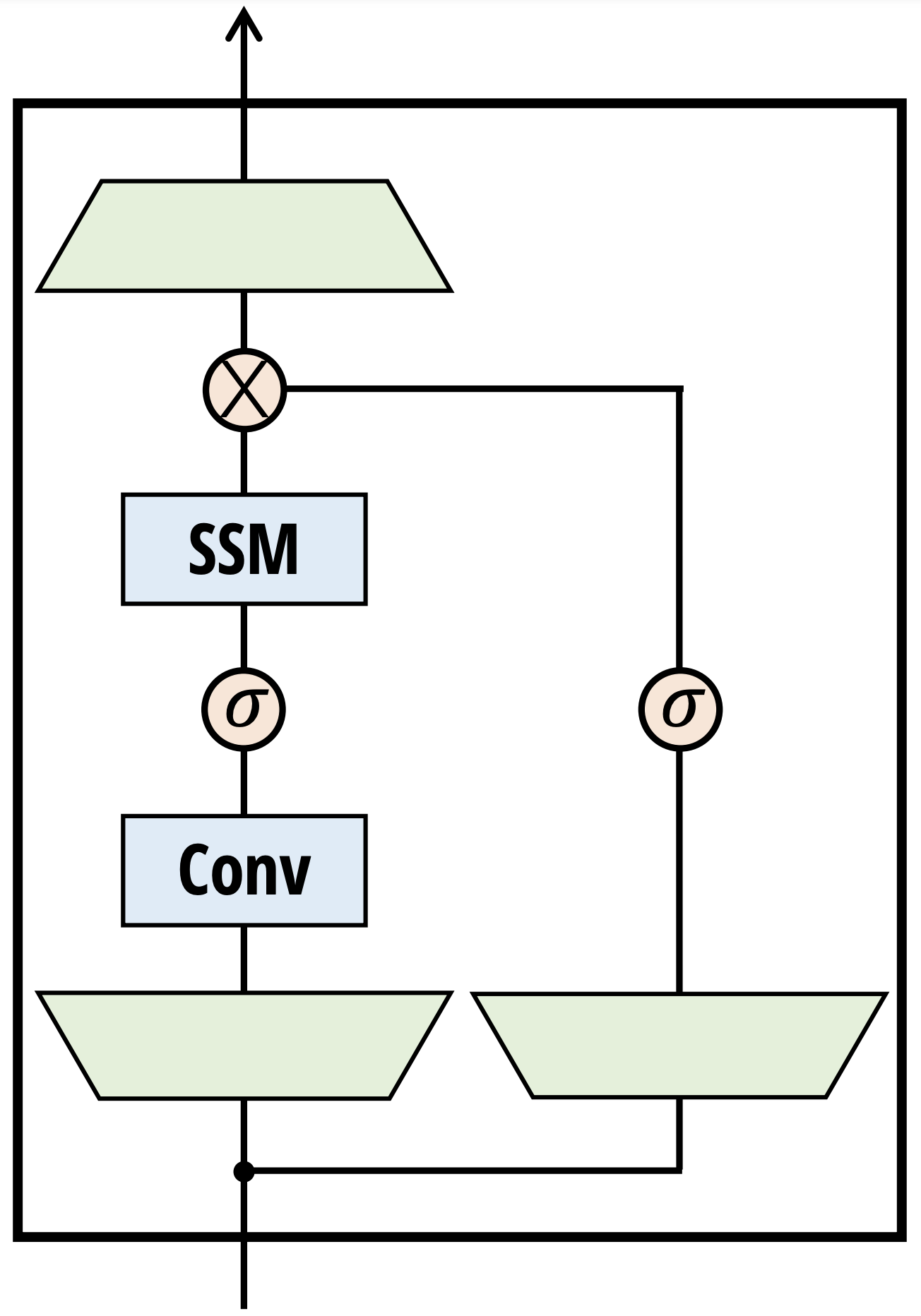
Recent advances in recurrent neural network architectures, such as Mamba and RWKV, have enabled RNNs to match or exceed the performance of equal-size transformers in terms of language modeling perplexity and downstream evaluations, suggesting that future systems may be built on completely new architectures. In this paper, we examine if selected interpretability methods originally designed for transformer language models will transfer to these up-and-coming recurrent architectures. Specifically, we focus on steering model outputs via contrastive activation addition, on eliciting latent predictions via the tuned lens, and eliciting latent knowledge from models fine-tuned to produce false outputs under certain conditions. Our results show that most of these techniques are effective when applied to RNNs, and we show that it is possible to improve some of them by taking advantage of RNNs' compressed state.
4/10/2024
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
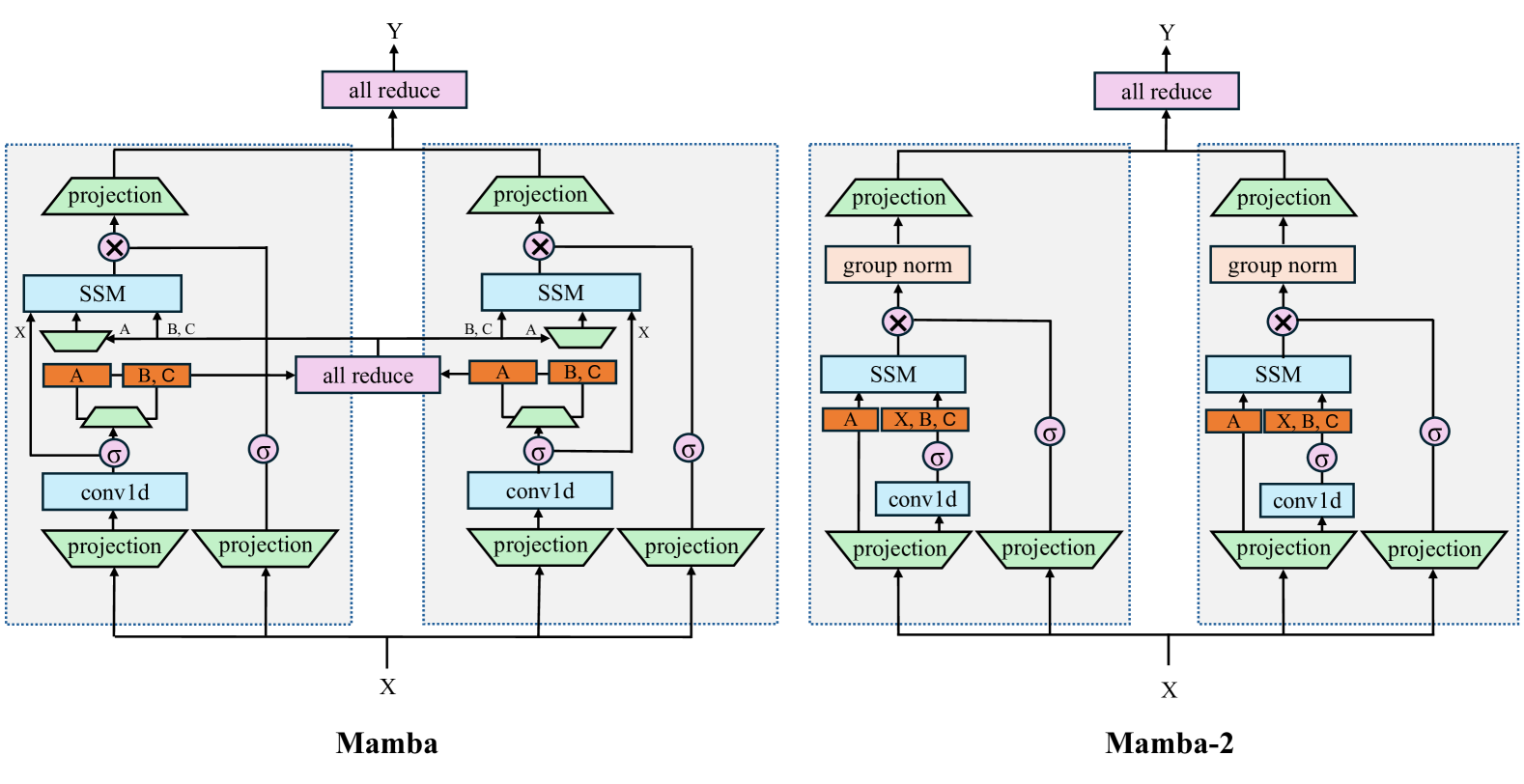
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024

Modeling Bilingual Sentence Processing: Evaluating RNN and Transformer Architectures for Cross-Language Structural Priming
Bushi Xiao, Chao Gao, Demi Zhang
0
0
This study evaluates the performance of Recurrent Neural Network (RNN) and Transformer in replicating cross-language structural priming: a key indicator of abstract grammatical representations in human language processing. Focusing on Chinese-English priming, which involves two typologically distinct languages, we examine how these models handle the robust phenomenon of structural priming, where exposure to a particular sentence structure increases the likelihood of selecting a similar structure subsequently. Additionally, we utilize large language models (LLM) to measure the cross-lingual structural priming effect. Our findings indicate that Transformer outperform RNN in generating primed sentence structures, challenging the conventional belief that human sentence processing primarily involves recurrent and immediate processing and suggesting a role for cue-based retrieval mechanisms. Overall, this work contributes to our understanding of how computational models may reflect human cognitive processes in multilingual contexts.
5/16/2024

Separations in the Representational Capabilities of Transformers and Recurrent Architectures
Satwik Bhattamishra, Michael Hahn, Phil Blunsom, Varun Kanade
0
0
Transformer architectures have been widely adopted in foundation models. Due to their high inference costs, there is renewed interest in exploring the potential of efficient recurrent architectures (RNNs). In this paper, we analyze the differences in the representational capabilities of Transformers and RNNs across several tasks of practical relevance, including index lookup, nearest neighbor, recognizing bounded Dyck languages, and string equality. For the tasks considered, our results show separations based on the size of the model required for different architectures. For example, we show that a one-layer Transformer of logarithmic width can perform index lookup, whereas an RNN requires a hidden state of linear size. Conversely, while constant-size RNNs can recognize bounded Dyck languages, we show that one-layer Transformers require a linear size for this task. Furthermore, we show that two-layer Transformers of logarithmic size can perform decision tasks such as string equality or disjointness, whereas both one-layer Transformers and recurrent models require linear size for these tasks. We also show that a log-size two-layer Transformer can implement the nearest neighbor algorithm in its forward pass; on the other hand recurrent models require linear size. Our constructions are based on the existence of $N$ nearly orthogonal vectors in $O(log N)$ dimensional space and our lower bounds are based on reductions from communication complexity problems. We supplement our theoretical results with experiments that highlight the differences in the performance of these architectures on practical-size sequences.
6/14/2024