DoG-Instruct: Towards Premium Instruction-Tuning Data via Text-Grounded Instruction Wrapping
2309.05447
0
0
📊
Abstract
The improvement of LLMs' instruction-following capabilities relies heavily on the availability of high-quality instruction-response pairs. Unfortunately, the current methods used to collect the pairs suffer from either unaffordable labor costs or severe hallucinations in the self-generation of LLM. To tackle these challenges, this paper proposes a scalable solution. It involves training LLMs to generate instruction-response pairs based on human-written documents, rather than relying solely on self-generation without context. Our proposed method not only exploits the advantages of human-written documents in reducing hallucinations but also utilizes an LLM to wrap the expression of documents, which enables us to bridge the gap between various document styles and the standard AI response. Experiments demonstrate that our method outperforms existing typical methods on multiple benchmarks. In particular, compared to the best-performing baseline, the LLM trained using our generated dataset exhibits a 10% relative improvement in performance on AlpacaEval, despite utilizing only 1/5 of its training data. Furthermore, a comprehensive manual evaluation validates the quality of the data we generated. Our trained wrapper is publicly available at https://github.com/Bahuia/Dog-Instruct.
Create account to get full access
Overview
- This paper proposes a novel solution to improve the instruction-following capabilities of large language models (LLMs).
- The current methods for collecting high-quality instruction-response pairs suffer from either high labor costs or severe hallucinations (generating false information) during self-generation.
- The paper introduces a scalable approach that trains LLMs to generate instruction-response pairs based on human-written documents, which reduces hallucinations and bridges the gap between document styles and standard AI responses.
Plain English Explanation
Large language models, such as GPT-3, are powerful tools that can understand and generate human-like text. However, their ability to follow complex instructions and provide accurate responses is limited. This is because the training data used to teach these models often lacks high-quality instruction-response pairs, which are essential for developing this skill.
The current methods used to collect these pairs have significant drawbacks. Some approaches rely on human labor, which can be expensive and time-consuming. Other methods, where the models try to generate the instruction-response pairs themselves, often result in the models "hallucinating" or producing inaccurate information.
To address these challenges, the researchers in this paper came up with a new solution. Instead of relying solely on self-generation, they trained the LLMs to generate instruction-response pairs based on human-written documents. This approach has several advantages:
- Reduced hallucinations: By using human-written documents as the source, the models are less likely to generate false or nonsensical information.
- Bridging the gap: The researchers used an additional language model to "wrap" the document content, which helps translate the diverse styles of the documents into the standard format expected by AI systems.
The researchers tested their method on several benchmarks and found that the LLMs trained using their generated dataset outperformed the best-performing baseline by 10% on the AlpacaEval benchmark, despite using only a fifth of the training data. This demonstrates the effectiveness of their approach in improving the instruction-following capabilities of large language models.
Technical Explanation
The key innovation of this paper is a scalable method for generating high-quality instruction-response pairs using human-written documents as a source. The researchers first collected a diverse set of documents from the internet, covering a wide range of topics and styles.
They then trained a language model to "wrap" the content of these documents, transforming them into the standard format expected by AI systems. This helps bridge the gap between the diverse document styles and the typical instruction-response format.
Next, the researchers fine-tuned a separate LLM using the generated instruction-response pairs. This LLM was then evaluated on several benchmarks, including AlpacaEval and a manual evaluation of data quality.
The results showed that the LLM trained using the generated dataset significantly outperformed the best-performing baseline, achieving a 10% relative improvement on AlpacaEval despite using only a fifth of the training data. The manual evaluation also confirmed the high quality of the generated instruction-response pairs.
Critical Analysis
The researchers have presented a novel and promising approach to improving the instruction-following capabilities of large language models. By leveraging human-written documents as a source, they were able to address the limitations of existing methods, such as high labor costs and hallucinations.
However, the paper does not delve into potential limitations or areas for further research. For example, it would be interesting to understand the types of documents that work best for generating high-quality instruction-response pairs, or how the performance of the model might be affected by the quality and diversity of the source documents.
Additionally, while the researchers provide a public release of their trained "wrapper" model, it would be valuable to have more details on the architecture and training process of the core LLM that was fine-tuned using the generated dataset.
Overall, this paper presents a promising step forward in enhancing the instruction-following capabilities of large language models, and the researchers' work could have significant implications for the field of language model instruction-following understanding.
Conclusion
This paper introduces a novel and scalable approach to improving the instruction-following capabilities of large language models. By training LLMs to generate instruction-response pairs based on human-written documents, the researchers were able to address the limitations of existing methods and achieve significant performance improvements on multiple benchmarks.
This work has the potential to unlock new applications for large language models, enabling them to better understand and follow complex instructions, which is crucial for tasks like personal assistants, task automation, and interactive learning. The researchers' public release of their trained "wrapper" model also provides a valuable resource for the broader research community.
Overall, this paper represents an important step forward in enhancing the instruction-following abilities of large language models, and the insights and techniques presented could have far-reaching implications for the field of natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-following LLM
Ruohong Zhang, Yau-Shian Wang, Yiming Yang
0
0
The remarkable performance of large language models (LLMs) in zero-shot language understanding has garnered significant attention. However, employing LLMs for large-scale inference or domain-specific fine-tuning requires immense computational resources due to their substantial model size. To overcome these limitations, we introduce a novel method, namely GenCo, which leverages the strong generative power of LLMs to assist in training a smaller and more adaptable language model. In our method, an LLM plays an important role in the self-training loop of a smaller model in two important ways. Firstly, the LLM is used to augment each input instance with a variety of possible continuations, enriching its semantic context for better understanding. Secondly, it helps crafting additional high-quality training pairs, by rewriting input texts conditioned on predicted labels. This ensures the generated texts are highly relevant to the predicted labels, alleviating the prediction error during pseudo-labeling, while reducing the dependency on large volumes of unlabeled text. In our experiments, GenCo outperforms previous state-of-the-art methods when only limited ($<5%$ of original) in-domain text data is available. Notably, our approach surpasses the performance of Alpaca-7B with human prompts, highlighting the potential of leveraging LLM for self-training.
4/16/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024
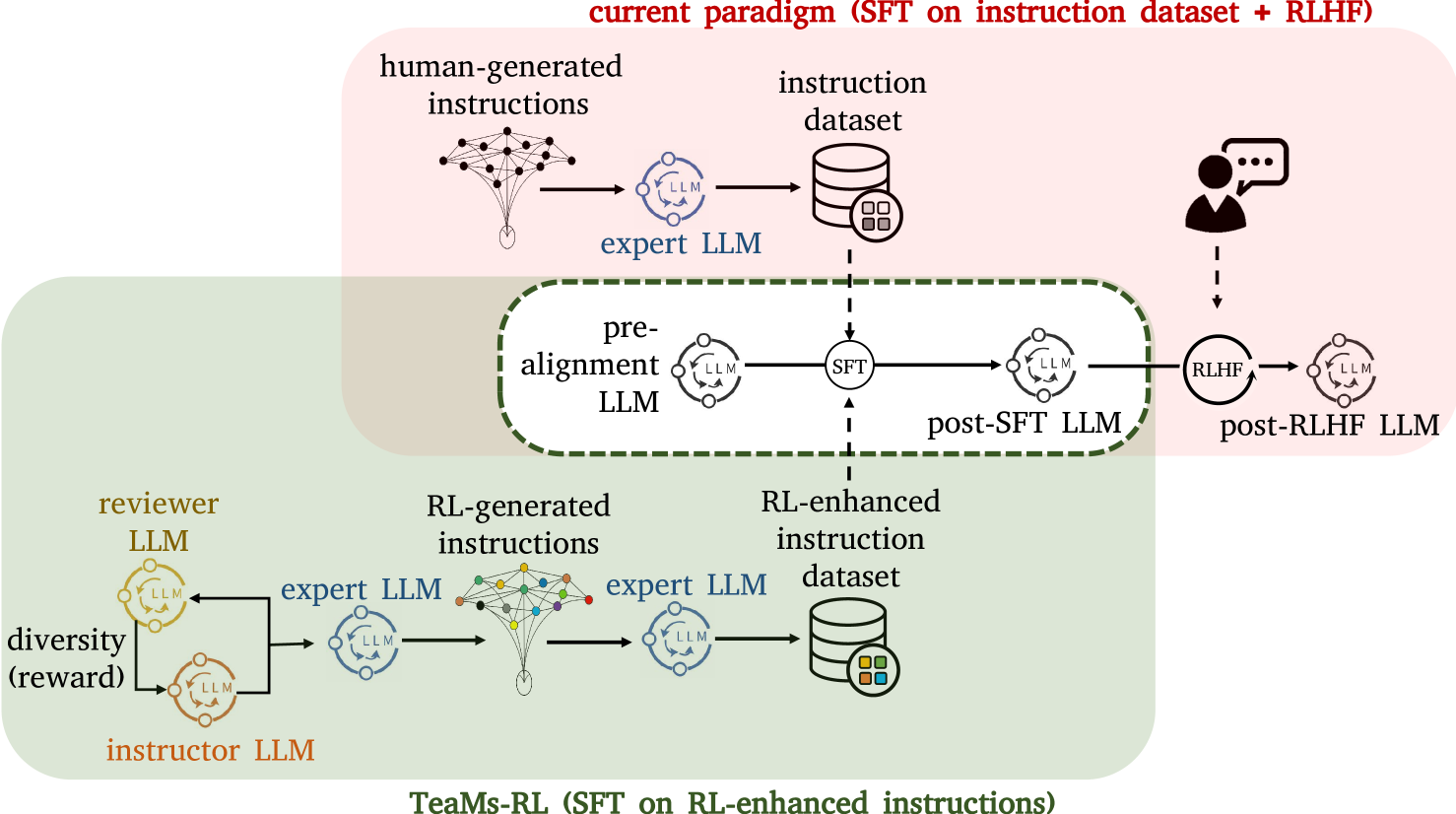
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024
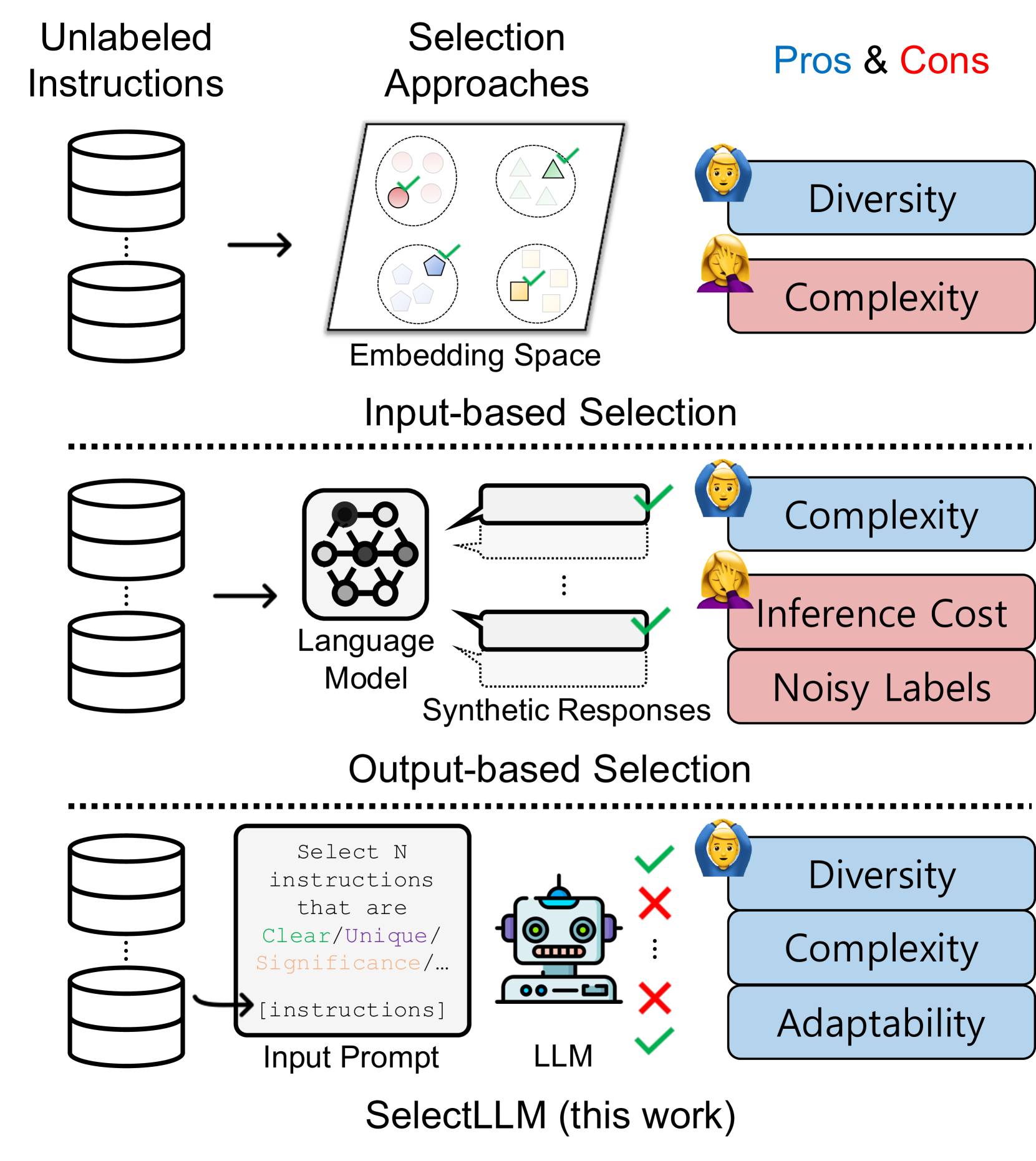
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, Dongyeop Kang
0
0
Instruction tuning benefits from large and diverse datasets, however creating such datasets involves a high cost of human labeling. While synthetic datasets generated by large language models (LLMs) have partly solved this issue, they often contain low-quality data. One effective solution is selectively annotating unlabelled instructions, especially given the relative ease of acquiring unlabeled instructions or texts from various sources. However, how to select unlabelled instructions is not well-explored, especially in the context of LLMs. Further, traditional data selection methods, relying on input embedding space density, tend to underestimate instruction sample complexity, whereas those based on model prediction uncertainty often struggle with synthetic label quality. Therefore, we introduce SelectLLM, an alternative framework that leverages the capabilities of LLMs to more effectively select unlabeled instructions. SelectLLM consists of two key steps: Coreset-based clustering of unlabelled instructions for diversity and then prompting a LLM to identify the most beneficial instructions within each cluster. Our experiments demonstrate that SelectLLM matches or outperforms other state-of-the-art methods in instruction tuning benchmarks. It exhibits remarkable consistency across human and synthetic datasets, along with better cross-dataset generalization, as evidenced by a 10% performance improvement on the Cleaned Alpaca test set when trained on Dolly data. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
4/19/2024