SelectLLM: Can LLMs Select Important Instructions to Annotate?
2401.16553
0
0
Abstract
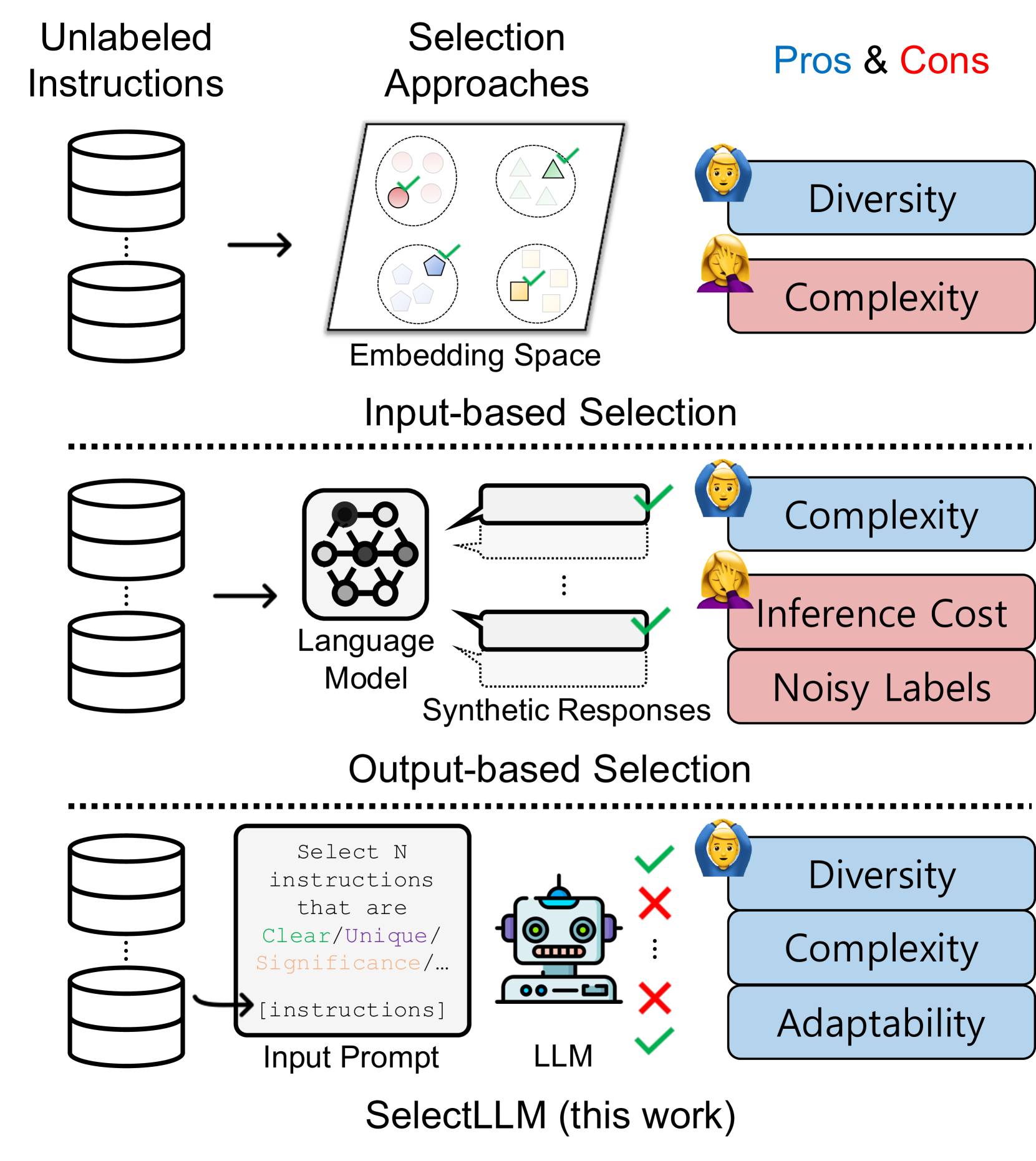
Instruction tuning benefits from large and diverse datasets, however creating such datasets involves a high cost of human labeling. While synthetic datasets generated by large language models (LLMs) have partly solved this issue, they often contain low-quality data. One effective solution is selectively annotating unlabelled instructions, especially given the relative ease of acquiring unlabeled instructions or texts from various sources. However, how to select unlabelled instructions is not well-explored, especially in the context of LLMs. Further, traditional data selection methods, relying on input embedding space density, tend to underestimate instruction sample complexity, whereas those based on model prediction uncertainty often struggle with synthetic label quality. Therefore, we introduce SelectLLM, an alternative framework that leverages the capabilities of LLMs to more effectively select unlabeled instructions. SelectLLM consists of two key steps: Coreset-based clustering of unlabelled instructions for diversity and then prompting a LLM to identify the most beneficial instructions within each cluster. Our experiments demonstrate that SelectLLM matches or outperforms other state-of-the-art methods in instruction tuning benchmarks. It exhibits remarkable consistency across human and synthetic datasets, along with better cross-dataset generalization, as evidenced by a 10% performance improvement on the Cleaned Alpaca test set when trained on Dolly data. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines whether large language models (LLMs) can effectively select and annotate important instructions from unlabeled data
- Proposes a novel approach called SelectLLM that leverages LLMs to identify and label high-value instructions
- Evaluates SelectLLM's performance on two real-world datasets and compares it to human-selected annotations
Plain English Explanation
The paper explores whether large language models (LLMs) can be used to automatically identify and annotate the most important instructions from a collection of unlabeled data. This is an important task, as manually reviewing and labeling large datasets can be time-consuming and expensive.
The researchers developed a new method called SelectLLM that uses language models trained on instruction-following tasks to select the most valuable instructions for annotation. The key idea is that the LLM can learn to recognize which instructions are most important or useful, even without any prior labeling.
To test this approach, the researchers evaluated SelectLLM on two real-world datasets and compared its performance to human-selected annotations. The results suggest that SelectLLM can effectively identify high-value instructions, potentially boosting the performance of language models trained on these annotated datasets.
This work demonstrates how language models can be leveraged to streamline the annotation process for instruction-following tasks, potentially reducing the time and cost required to build high-quality datasets. The findings have important implications for researchers and practitioners interested in aligning language models with user instructions.
Technical Explanation
The paper proposes a novel approach called SelectLLM that uses large language models (LLMs) to select and annotate important instructions from unlabeled data. The key idea is that the LLM can learn to recognize valuable instructions based on their content and structure, even without any prior labeling.
The SelectLLM system works as follows:
- An LLM is fine-tuned on a set of labeled instructions, teaching it to identify important features of high-value instructions.
- The fine-tuned LLM is then used to score and rank a set of unlabeled instructions, with the top-ranked instructions selected for annotation.
- The annotated instructions are then used to fine-tune the LLM further, iteratively improving its ability to identify important instructions.
The researchers evaluated SelectLLM on two real-world datasets: a set of cooking instructions and a set of software development tutorials. They compared SelectLLM's performance to human-selected annotations, finding that it was able to identify a significant portion of the most valuable instructions.
The results suggest that SelectLLM can effectively leverage LLMs to streamline the annotation process for instruction-following tasks. By automating the selection of high-value instructions, this approach has the potential to reduce the time and cost required to build high-quality datasets for training and evaluating language models.
Critical Analysis
The paper makes a compelling case for the use of LLMs to automate the selection and annotation of important instructions. However, the researchers acknowledge several limitations and areas for future work:
- The evaluation was limited to two specific datasets, and further testing is needed to assess the generalizability of SelectLLM to other types of instructions.
- The paper does not explore the potential biases or blindspots that may be present in the LLM's selection of instructions, which could lead to the exclusion of important but underrepresented content.
- The iterative fine-tuning process used by SelectLLM may be computationally expensive, and alternative approaches for improving the LLM's performance could be investigated.
Additionally, it would be valuable to understand the impact of the selected instructions on the downstream performance of language models trained on the annotated datasets. Further research could explore how the quality and diversity of the selected instructions affect the robustness and capabilities of the resulting models.
Overall, this paper presents a promising approach for leveraging LLMs to streamline the annotation of instruction-following datasets. However, careful consideration of potential limitations and further exploration of the approach's broader implications will be important for ensuring the responsible development and deployment of such systems.
Conclusion
The paper "SelectLLM: Can LLMs Select Important Instructions to Annotate?" explores a novel approach for using large language models (LLMs) to automatically identify and annotate valuable instructions from unlabeled data. The proposed SelectLLM system leverages fine-tuned LLMs to score and rank instructions, with the top-ranked instructions selected for manual annotation.
The evaluation of SelectLLM on two real-world datasets suggests that this approach can effectively identify a significant portion of the most important instructions, potentially reducing the time and cost required to build high-quality datasets for training and evaluating language models.
While the paper highlights the potential benefits of this technique, it also acknowledges several limitations and areas for future research, such as exploring the generalizability of SelectLLM, addressing potential biases in the LLM's selection process, and investigating the impact of the selected instructions on the performance of downstream language models.
Overall, this work demonstrates the power of leveraging LLMs to streamline the annotation of instruction-following datasets, with important implications for aligning language models with user instructions and advancing the field of instruction-following understanding.
Related Papers
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
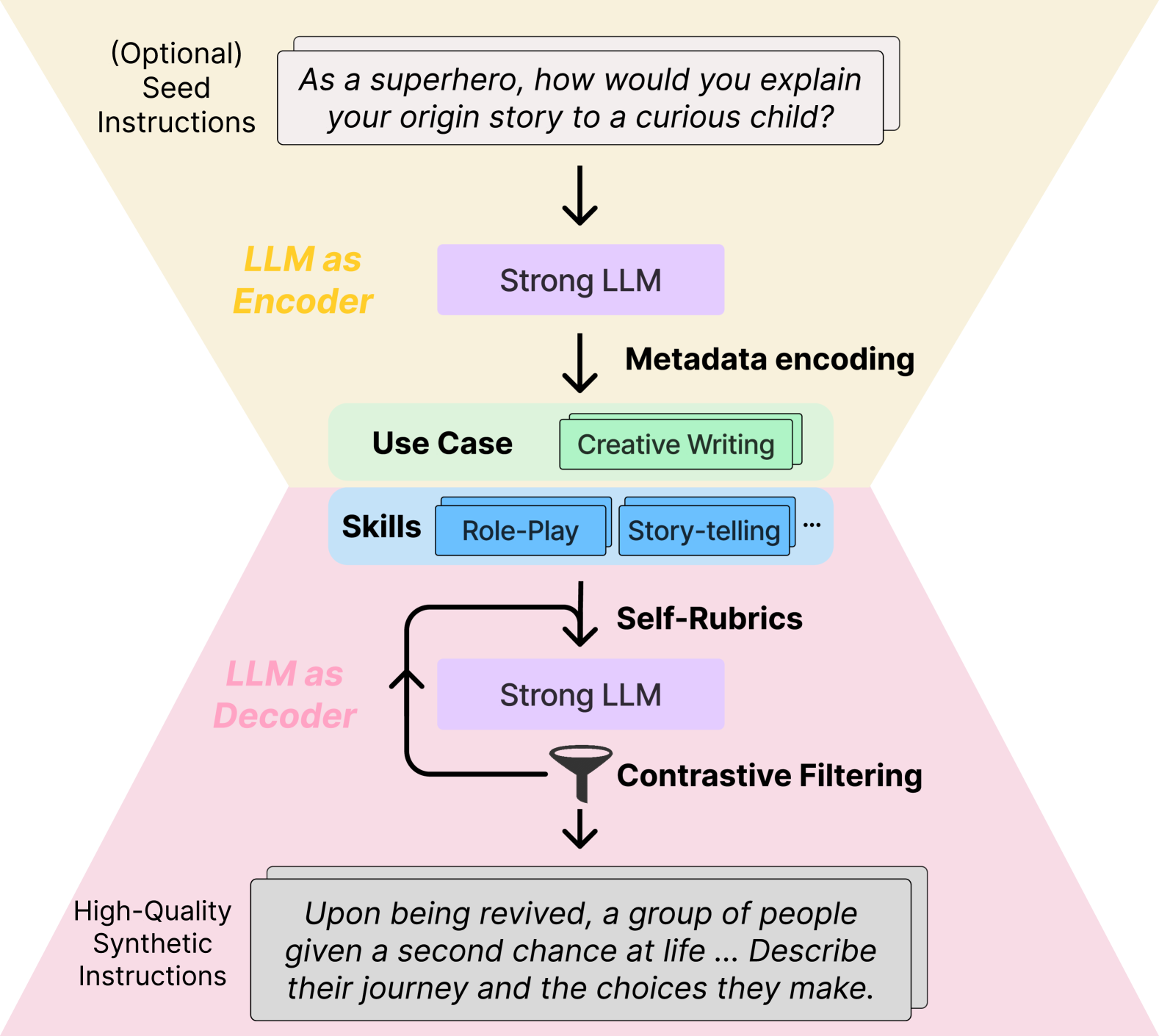
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024
💬
Wisdom of Instruction-Tuned Language Model Crowds. Exploring Model Label Variation
Flor Miriam Plaza-del-Arco, Debora Nozza, Dirk Hovy
0
0
Large Language Models (LLMs) exhibit remarkable text classification capabilities, excelling in zero- and few-shot learning (ZSL and FSL) scenarios. However, since they are trained on different datasets, performance varies widely across tasks between those models. Recent studies emphasize the importance of considering human label variation in data annotation. However, how this human label variation also applies to LLMs remains unexplored. Given this likely model specialization, we ask: Do aggregate LLM labels improve over individual models (as for human annotators)? We evaluate four recent instruction-tuned LLMs as annotators on five subjective tasks across four languages. We use ZSL and FSL setups and label aggregation from human annotation. Aggregations are indeed substantially better than any individual model, benefiting from specialization in diverse tasks or languages. Surprisingly, FSL does not surpass ZSL, as it depends on the quality of the selected examples. However, there seems to be no good information-theoretical strategy to select those. We find that no LLM method rivals even simple supervised models. We also discuss the tradeoffs in accuracy, cost, and moral/ethical considerations between LLM and human annotation.
4/16/2024
🚀
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, Jing Xiao
0
0
In the realm of Large Language Models (LLMs), the balance between instruction data quality and quantity is a focal point. Recognizing this, we introduce a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, effectively minimizing manual curation and potential cost for instruction tuning an LLM. Our key innovation, the Instruction-Following Difficulty (IFD) metric, emerges as a pivotal metric to identify discrepancies between a model's expected responses and its intrinsic generation capability. Through the application of IFD, cherry samples can be pinpointed, leading to a marked uptick in model training efficiency. Empirical validations on datasets like Alpaca and WizardLM underpin our findings; with a mere $10%$ of original data input, our strategy showcases improved results. This synthesis of self-guided cherry-picking and the IFD metric signifies a transformative leap in the instruction tuning of LLMs, promising both efficiency and resource-conscious advancements. Codes, data, and models are available: https://github.com/tianyi-lab/Cherry_LLM
4/9/2024
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024