From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
2310.00492
0
0
💬
Abstract
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have achieved remarkable success, with instruction tuning being a critical step in aligning them with user intentions.
- This work investigates how instruction tuning adjusts pre-trained models, focusing on intrinsic changes.
- The researchers developed explanation methods to understand the impact of instruction tuning on LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. A key step in making these models useful is "instruction tuning," which trains them to follow specific instructions from users.
In this study, the researchers looked at how instruction tuning changes the inner workings of LLMs. They developed new ways to "look under the hood" and explain what's happening inside the models, both before and after instruction tuning.
The main findings are:
-
Instruction tuning helps LLMs recognize when users are giving them instructions, and generates responses that are constantly focused on following those instructions.
-
Instruction tuning changes the model's "attention" mechanism, making it better at recognizing relationships between instruction words.
-
Instruction tuning also adjusts the model's core knowledge and abilities, rotating them towards being more useful for user-oriented tasks.
These insights help us better understand how instruction tuning shapes LLMs to be more aligned with human intentions. This lays the groundwork for future work on explaining and improving LLMs for real-world applications.
Technical Explanation
The researchers first developed new "explanation methods" to analyze the inner workings of LLMs. This includes a gradient-based technique for tracing the influence of different input parts on the model's outputs, as well as ways to interpret the patterns and concepts captured by the model's attention and core processing layers.
They then used these explanation methods to compare pre-trained LLMs and LLMs that had undergone instruction tuning. This allowed them to see how the instruction tuning process changes the model's behavior and inner representations.
The key findings were:
-
Instruction tuning helps the model recognize when the input contains instructions, and shapes the response generation to be constantly conditioned on following those instructions.
-
Instruction tuning encourages the model's attention mechanism to better capture relationships between instruction-related words.
-
Instruction tuning also encourages the model's core "feed-forward" processing to shift its pre-trained knowledge towards being more useful for user-oriented tasks.
These insights contribute to a deeper understanding of how instruction tuning works to align LLMs with human intentions. The researchers make their code and data publicly available to support further work in this area.
Critical Analysis
The paper provides a thoughtful and rigorous analysis of the impact of instruction tuning on LLMs. The researchers' development of new explanation methods is a valuable contribution, as it allows for a more nuanced and interpretable view of these complex models.
However, the study is limited to a single LLM architecture (GPT-3) and a specific set of tasks. It would be important to see if the findings generalize to other LLM models and a broader range of applications. Additionally, the paper does not delve into potential risks or unintended consequences of instruction tuning, such as backdoor vulnerabilities or misalignment with human feedback.
Further research could explore the psychometric and predictive power of LLMs under different instruction tuning regimes, or investigate more effective instruction tuning techniques that balance capabilities and alignment.
Conclusion
This study provides valuable insights into how instruction tuning shapes the inner workings of large language models. By developing new explanation methods, the researchers were able to uncover several key impacts of the instruction tuning process, including improved recognition of instructions, better attention to instruction-related words, and a shift in the model's core knowledge towards user-oriented tasks.
These findings contribute to a deeper understanding of how to align LLMs with human intentions, which is crucial as these models become increasingly ubiquitous in real-world applications. The publicly available code and data from this work will also support further research in this important area of AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Psychometric Predictive Power of Large Language Models
Tatsuki Kuribayashi, Yohei Oseki, Timothy Baldwin
0
0
Instruction tuning aligns the response of large language models (LLMs) with human preferences. Despite such efforts in human--LLM alignment, we find that instruction tuning does not always make LLMs human-like from a cognitive modeling perspective. More specifically, next-word probabilities estimated by instruction-tuned LLMs are often worse at simulating human reading behavior than those estimated by base LLMs. In addition, we explore prompting methodologies for simulating human reading behavior with LLMs. Our results show that prompts reflecting a particular linguistic hypothesis improve psychometric predictive power, but are still inferior to small base models. These findings highlight that recent advancements in LLMs, i.e., instruction tuning and prompting, do not offer better estimates than direct probability measurements from base LLMs in cognitive modeling. In other words, pure next-word probability remains a strong predictor for human reading behavior, even in the age of LLMs.
4/16/2024

Does Instruction Tuning Make LLMs More Consistent?
Constanza Fierro, Jiaang Li, Anders S{o}gaard
0
0
The purpose of instruction tuning is enabling zero-shot performance, but instruction tuning has also been shown to improve chain-of-thought reasoning and value alignment (Si et al., 2023). Here we consider the impact on $textit{consistency}$, i.e., the sensitivity of language models to small perturbations in the input. We compare 10 instruction-tuned LLaMA models to the original LLaMA-7b model and show that almost across-the-board they become more consistent, both in terms of their representations and their predictions in zero-shot and downstream tasks. We explain these improvements through mechanistic analyses of factual recall.
5/1/2024
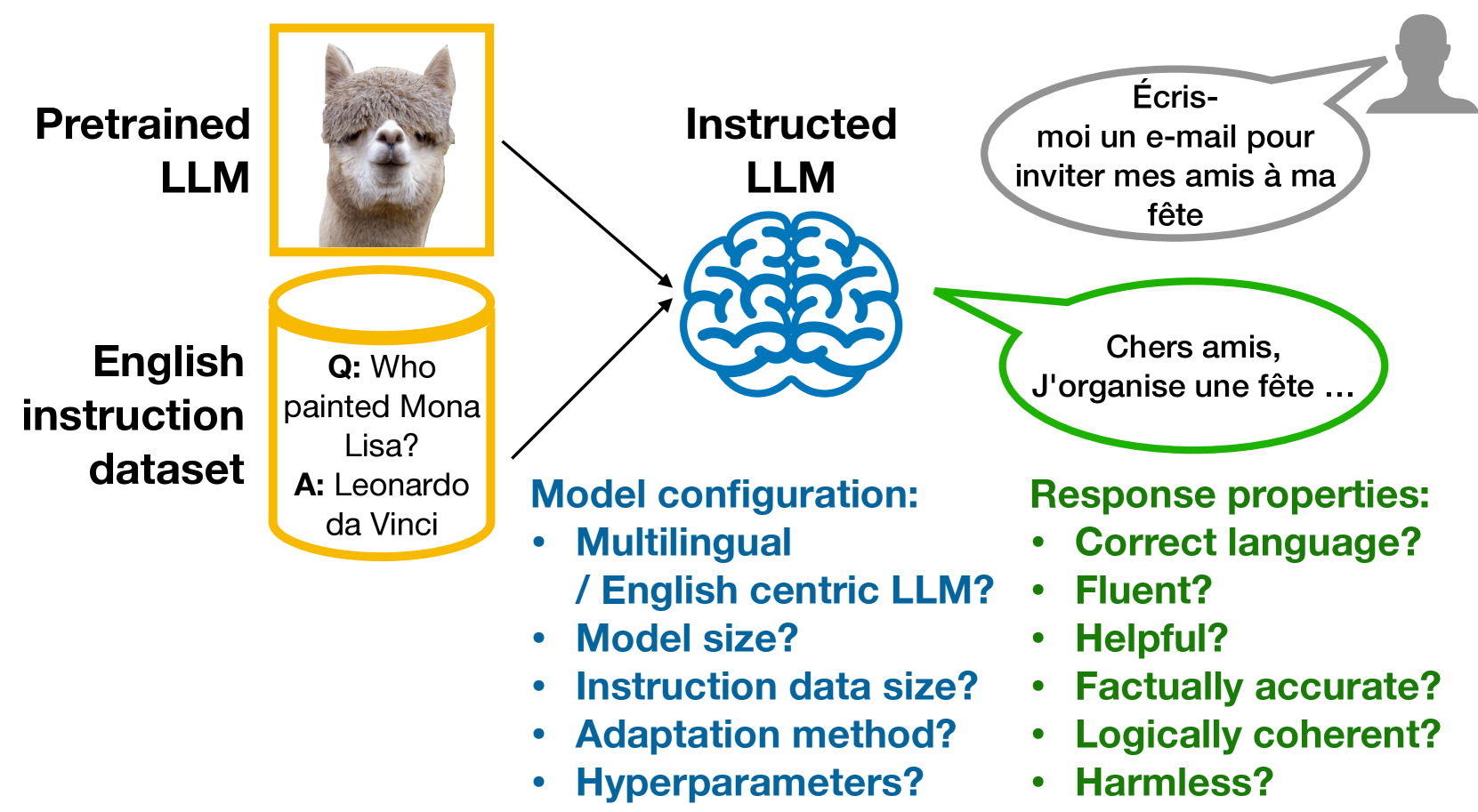
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024
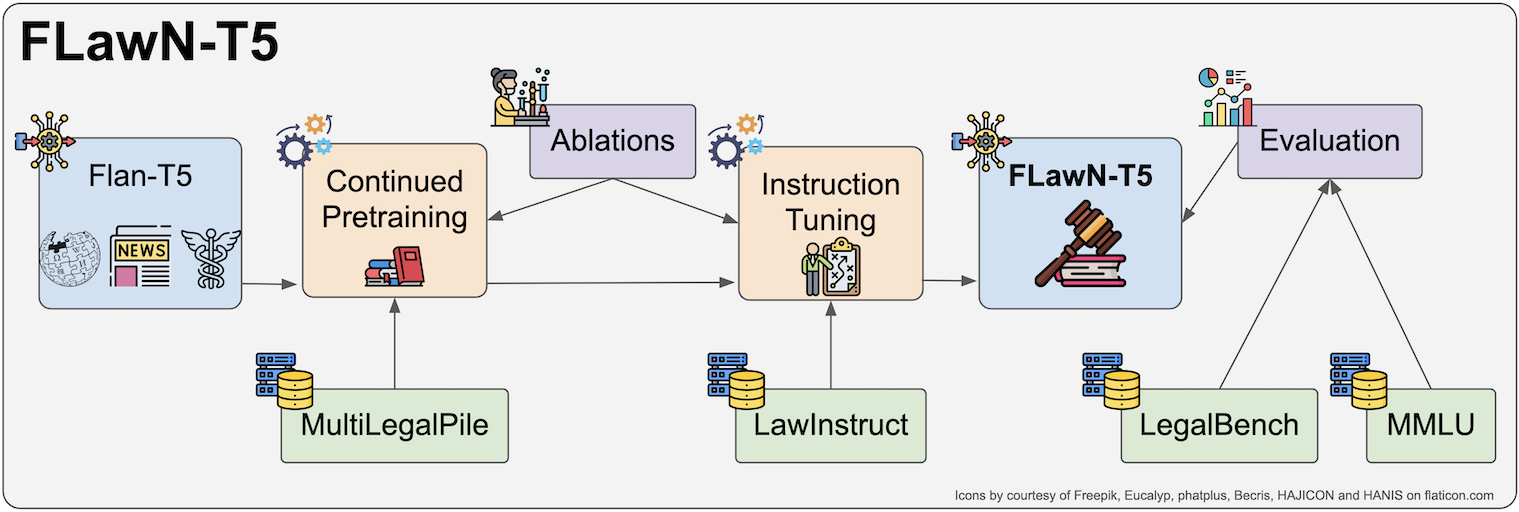
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Joel Niklaus, Lucia Zheng, Arya D. McCarthy, Christopher Hahn, Brian M. Rosen, Peter Henderson, Daniel E. Ho, Garrett Honke, Percy Liang, Christopher Manning
0
0
Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
4/3/2024