$alpha$-SSC: Uncertainty-Aware Camera-based 3D Semantic Scene Completion

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "𝛼-SSC" for uncertainty-aware camera-based 3D semantic scene completion.
- 𝛼-SSC leverages a neural network to jointly estimate the 3D geometry, semantics, and uncertainty of a scene from a single RGB image.
- The method aims to address the challenge of 3D scene understanding from limited visual input, while also quantifying the uncertainty in the predictions.
Plain English Explanation
The paper introduces a new technique called "𝛼-SSC" that can take a regular 2D photo and use it to create a 3D model of the scene, complete with information about what objects and materials are present and how certain the system is about its predictions.
This is a valuable capability because many real-world applications, like self-driving cars or robots, need to build detailed 3D maps of their surroundings in order to navigate safely and effectively. However, getting that 3D information from just a 2D camera can be very difficult.
The key idea behind 𝛼-SSC is to train a neural network to analyze the 2D image and infer the missing 3D geometry, semantic labels (e.g. chair, wall, floor), and an estimate of how confident the system is in each of its predictions. By providing this uncertainty information alongside the 3D reconstruction, the system can better convey what it knows and doesn't know about the scene.
This uncertainty-aware approach is important because it allows downstream applications to make more informed decisions. For example, a self-driving car might be extra cautious in areas where the 3D scene understanding has high uncertainty, rather than blindly trusting the predictions.
Overall, 𝛼-SSC represents a step forward in enabling robust 3D scene understanding from limited visual inputs, which could have significant implications for a wide range of computer vision and robotics applications.
Technical Explanation
The 𝛼-SSC method builds on prior work in semantic scene completion and uncertainty-aware 3D reconstruction. It uses a multi-task neural network architecture to jointly predict the 3D geometry, semantic labels, and uncertainty estimates from a single RGB image.
The key technical components include:
- A 2D encoder network that extracts visual features from the input image
- A 3D decoder network that predicts the 3D occupancy grid, semantic labels, and uncertainty values for each voxel
- A novel "uncertainty head" that estimates calibrated aleatoric and epistemic uncertainty for each prediction
The model is trained end-to-end on a dataset of RGB images paired with ground truth 3D scene information. During inference, the network takes a single image as input and outputs the completed 3D scene with semantics and uncertainty, enabling downstream applications to reason about the reliability of the 3D understanding.
Experiments demonstrate that 𝛼-SSC achieves state-of-the-art performance on standard 3D scene completion benchmarks like PASCO and PanoSSC, while also providing valuable uncertainty estimates that can be used to improve decision-making.
Critical Analysis
One key limitation of the 𝛼-SSC approach is that it relies on dense 3D scene annotations for training, which can be expensive and time-consuming to obtain. The authors mention the potential for using weaker forms of supervision, such as scribble annotations, to reduce the annotation burden, but this remains an area for future work.
Additionally, the evaluation of the uncertainty estimates is relatively limited in the paper. While the authors show that the uncertainty predictions are calibrated and can be used to improve performance on downstream tasks, a more thorough analysis of the uncertainty quantification would help build confidence in the robustness of the approach.
Another potential concern is the computational complexity of the 𝛼-SSC network, which must perform dense 3D predictions. This could limit the real-time applicability of the method, especially in resource-constrained settings like mobile robotics. Exploring more efficient network architectures or inference techniques could be a fruitful direction for future research.
Overall, the 𝛼-SSC method represents an interesting and valuable contribution to the field of 3D scene understanding. By jointly reasoning about geometry, semantics, and uncertainty, it takes an important step towards more robust and trustworthy 3D perception capabilities. Further research to address the limitations mentioned above could help unlock the full potential of this approach.
Conclusion
The 𝛼-SSC paper introduces a novel technique for uncertainty-aware 3D semantic scene completion from single RGB images. By training a neural network to jointly predict the 3D geometry, semantic labels, and uncertainty estimates, the method can provide a more comprehensive and reliable understanding of the scene compared to previous approaches.
The key innovation is the incorporation of uncertainty quantification, which allows downstream applications to better reason about the reliability of the 3D scene reconstruction. This could have significant implications for a wide range of computer vision and robotics tasks, such as autonomous navigation, augmented reality, and robotic manipulation.
While the paper demonstrates promising results, there are still opportunities for further research to address limitations around annotation requirements, uncertainty analysis, and computational efficiency. Nonetheless, the 𝛼-SSC approach represents an important step forward in enabling robust and trustworthy 3D scene understanding from limited visual inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
$alpha$-SSC: Uncertainty-Aware Camera-based 3D Semantic Scene Completion
Sanbao Su, Nuo Chen, Felix Juefei-Xu, Chen Feng, Fei Miao
In the realm of autonomous vehicle (AV) perception, comprehending 3D scenes is paramount for tasks such as planning and mapping. Semantic scene completion (SSC) aims to infer scene geometry and semantics from limited observations. While camera-based SSC has gained popularity due to affordability and rich visual cues, existing methods often neglect the inherent uncertainty in models. To address this, we propose an uncertainty-aware camera-based 3D semantic scene completion method ($alpha$-SSC). Our approach includes an uncertainty propagation framework from depth models (Depth-UP) to enhance geometry completion (up to 11.58% improvement) and semantic segmentation (up to 14.61% improvement). Additionally, we propose a hierarchical conformal prediction (HCP) method to quantify SSC uncertainty, effectively addressing high-level class imbalance in SSC datasets. On the geometry level, we present a novel KL divergence-based score function that significantly improves the occupied recall of safety-critical classes (45% improvement) with minimal performance overhead (3.4% reduction). For uncertainty quantification, we demonstrate the ability to achieve smaller prediction set sizes while maintaining a defined coverage guarantee. Compared with baselines, it achieves up to 85% reduction in set sizes. Our contributions collectively signify significant advancements in SSC accuracy and robustness, marking a noteworthy step forward in autonomous perception systems.
Read more6/24/2024
🌐
0
PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
Anh-Quan Cao, Angela Dai, Raoul de Charette
We propose the task of Panoptic Scene Completion (PSC) which extends the recently popular Semantic Scene Completion (SSC) task with instance-level information to produce a richer understanding of the 3D scene. Our PSC proposal utilizes a hybrid mask-based technique on the non-empty voxels from sparse multi-scale completions. Whereas the SSC literature overlooks uncertainty which is critical for robotics applications, we instead propose an efficient ensembling to estimate both voxel-wise and instance-wise uncertainties along PSC. This is achieved by building on a multi-input multi-output (MIMO) strategy, while improving performance and yielding better uncertainty for little additional compute. Additionally, we introduce a technique to aggregate permutation-invariant mask predictions. Our experiments demonstrate that our method surpasses all baselines in both Panoptic Scene Completion and uncertainty estimation on three large-scale autonomous driving datasets. Our code and data are available at https://astra-vision.github.io/PaSCo .
Read more5/28/2024

0
Hierarchical Temporal Context Learning for Camera-based Semantic Scene Completion
Bohan Li, Jiajun Deng, Wenyao Zhang, Zhujin Liang, Dalong Du, Xin Jin, Wenjun Zeng
Camera-based 3D semantic scene completion (SSC) is pivotal for predicting complicated 3D layouts with limited 2D image observations. The existing mainstream solutions generally leverage temporal information by roughly stacking history frames to supplement the current frame, such straightforward temporal modeling inevitably diminishes valid clues and increases learning difficulty. To address this problem, we present HTCL, a novel Hierarchical Temporal Context Learning paradigm for improving camera-based semantic scene completion. The primary innovation of this work involves decomposing temporal context learning into two hierarchical steps: (a) cross-frame affinity measurement and (b) affinity-based dynamic refinement. Firstly, to separate critical relevant context from redundant information, we introduce the pattern affinity with scale-aware isolation and multiple independent learners for fine-grained contextual correspondence modeling. Subsequently, to dynamically compensate for incomplete observations, we adaptively refine the feature sampling locations based on initially identified locations with high affinity and their neighboring relevant regions. Our method ranks $1^{st}$ on the SemanticKITTI benchmark and even surpasses LiDAR-based methods in terms of mIoU on the OpenOccupancy benchmark. Our code is available on https://github.com/Arlo0o/HTCL.
Read more7/17/2024
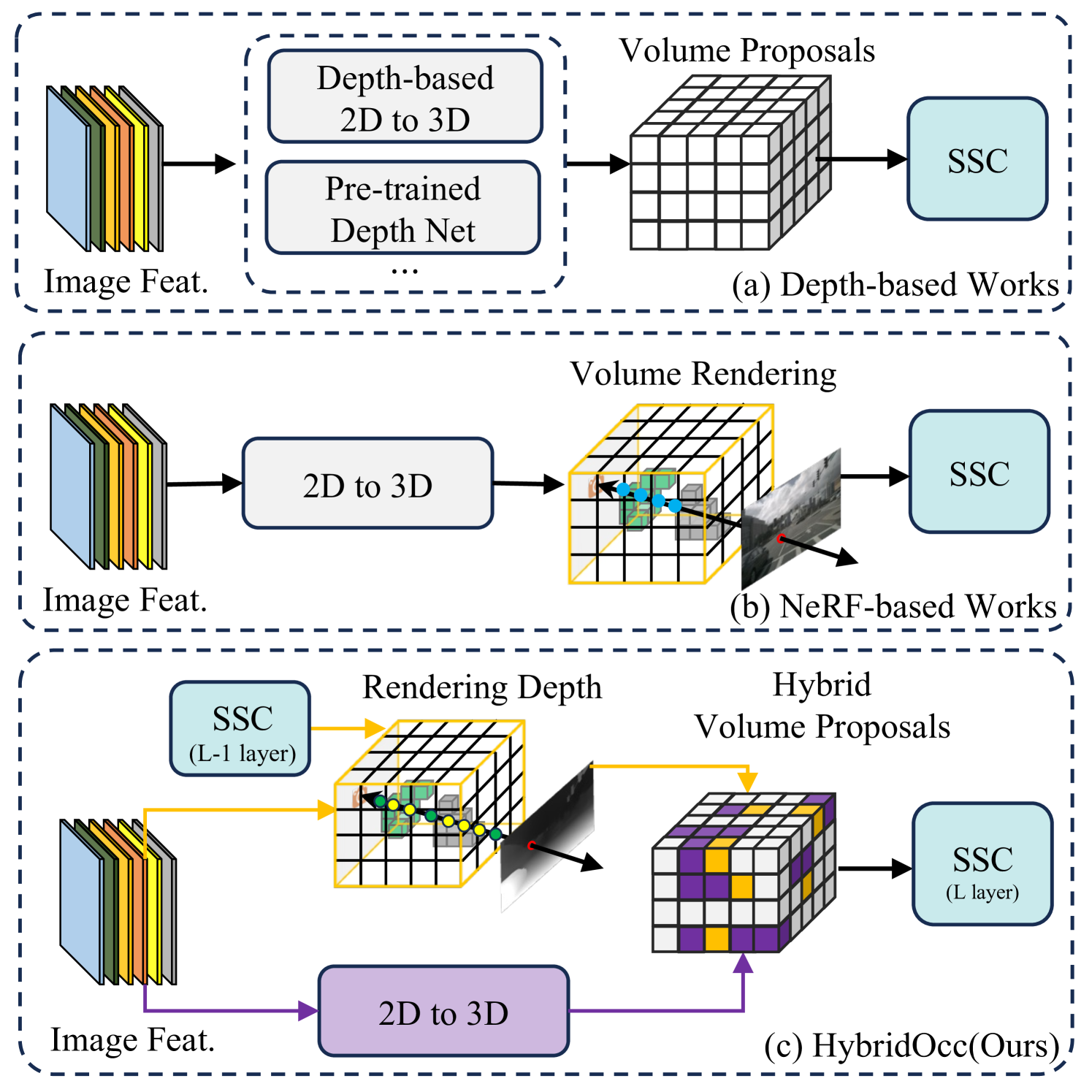
0
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Xiao Zhao, Bo Chen, Mingyang Sun, Dingkang Yang, Youxing Wang, Xukun Zhang, Mingcheng Li, Dongliang Kou, Xiaoyi Wei, Lihua Zhang
Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
Read more8/20/2024