Context and Geometry Aware Voxel Transformer for Semantic Scene Completion

0
👀
Sign in to get full access
Overview
- Semantic Scene Completion (SSC) is a 3D perception task that has gained significant attention due to its widespread applications.
- Existing sparse-to-dense approaches often use shared context-independent queries across input images, failing to capture distinctions among them, which can lead to undirected feature aggregation.
- The absence of depth information can also result in depth ambiguity, as points projected onto the image plane may share the same 2D position or have similar sampling points in the feature map.
Plain English Explanation
The paper presents a novel context and geometry aware voxel transformer, which addresses the limitations of existing approaches. The key ideas are:
- Context-Aware Query Generation: The model uses a context-aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest.
- Deformable Cross-Attention in 3D: The model extends deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates.
- Multi-Representation Fusion: The model, named CGFormer, leverages multiple 3D representations (voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives.
By incorporating these innovations, the model aims to achieve state-of-the-art performance on semantic scene completion tasks.
Technical Explanation
The proposed CGFormer model utilizes a context-aware query generator to initialize context-dependent queries tailored to individual input images. This allows the model to effectively capture the unique characteristics of each input and aggregate information within the region of interest, addressing the limitations of shared context-independent queries used in existing sparse-to-dense approaches.
Additionally, the model extends deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. This mitigates the depth ambiguity issue that can arise when points projected onto the image plane share the same 2D position or have similar sampling points in the feature map.
To further enhance the model's performance, CGFormer leverages multiple 3D representations (voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. This multi-representation fusion approach draws inspiration from recent innovations in 3D perception models and medical image segmentation.
Critical Analysis
The paper presents a comprehensive approach to addressing the limitations of existing sparse-to-dense methods for semantic scene completion. The proposed CGFormer model incorporates several key innovations, such as context-aware query generation and deformable cross-attention in 3D, which have demonstrated significant performance improvements on benchmark datasets.
However, the paper does not discuss the potential computational and memory-related challenges of the proposed model, particularly when dealing with large-scale 3D inputs. Additionally, the paper could have provided more insights into the model's robustness to variations in input data, such as sensor noise or partial occlusions, which are common in real-world scenarios.
Furthermore, the paper could have explored the potential applications of the CGFormer model beyond semantic scene completion, such as its use in other 3D perception tasks, like 3D object detection or 3D semantic segmentation.
Conclusion
The proposed CGFormer model represents a significant advancement in the field of semantic scene completion, addressing the limitations of existing sparse-to-dense approaches. By incorporating context-aware query generation and deformable cross-attention in 3D, the model is able to effectively capture the unique characteristics of input data and differentiate points with similar image coordinates based on their depth information.
The demonstrated state-of-the-art performance on benchmark datasets highlights the potential of the CGFormer model to contribute to a wide range of 3D perception applications, from autonomous driving to robotic navigation and beyond. As the field of 3D perception continues to evolve, this research provides valuable insights and a foundation for further advancements in the understanding and reconstruction of complex, semantic-rich environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Context and Geometry Aware Voxel Transformer for Semantic Scene Completion
Zhu Yu, Runming Zhang, Jiacheng Ying, Junchen Yu, Xiaohai Hu, Lun Luo, Siyuan Cao, Huiliang Shen
Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks. Code for the proposed method is available at https://github.com/pkqbajng/CGFormer.
Read more5/24/2024

0
SGIFormer: Semantic-guided and Geometric-enhanced Interleaving Transformer for 3D Instance Segmentation
Lei Yao, Yi Wang, Moyun Liu, Lap-Pui Chau
In recent years, transformer-based models have exhibited considerable potential in point cloud instance segmentation. Despite the promising performance achieved by existing methods, they encounter challenges such as instance query initialization problems and excessive reliance on stacked layers, rendering them incompatible with large-scale 3D scenes. This paper introduces a novel method, named SGIFormer, for 3D instance segmentation, which is composed of the Semantic-guided Mix Query (SMQ) initialization and the Geometric-enhanced Interleaving Transformer (GIT) decoder. Specifically, the principle of our SMQ initialization scheme is to leverage the predicted voxel-wise semantic information to implicitly generate the scene-aware query, yielding adequate scene prior and compensating for the learnable query set. Subsequently, we feed the formed overall query into our GIT decoder to alternately refine instance query and global scene features for further capturing fine-grained information and reducing complex design intricacies simultaneously. To emphasize geometric property, we consider bias estimation as an auxiliary task and progressively integrate shifted point coordinates embedding to reinforce instance localization. SGIFormer attains state-of-the-art performance on ScanNet V2, ScanNet200 datasets, and the challenging high-fidelity ScanNet++ benchmark, striking a balance between accuracy and efficiency. The code, weights, and demo videos are publicly available at https://rayyoh.github.io/sgiformer.
Read more7/17/2024
0
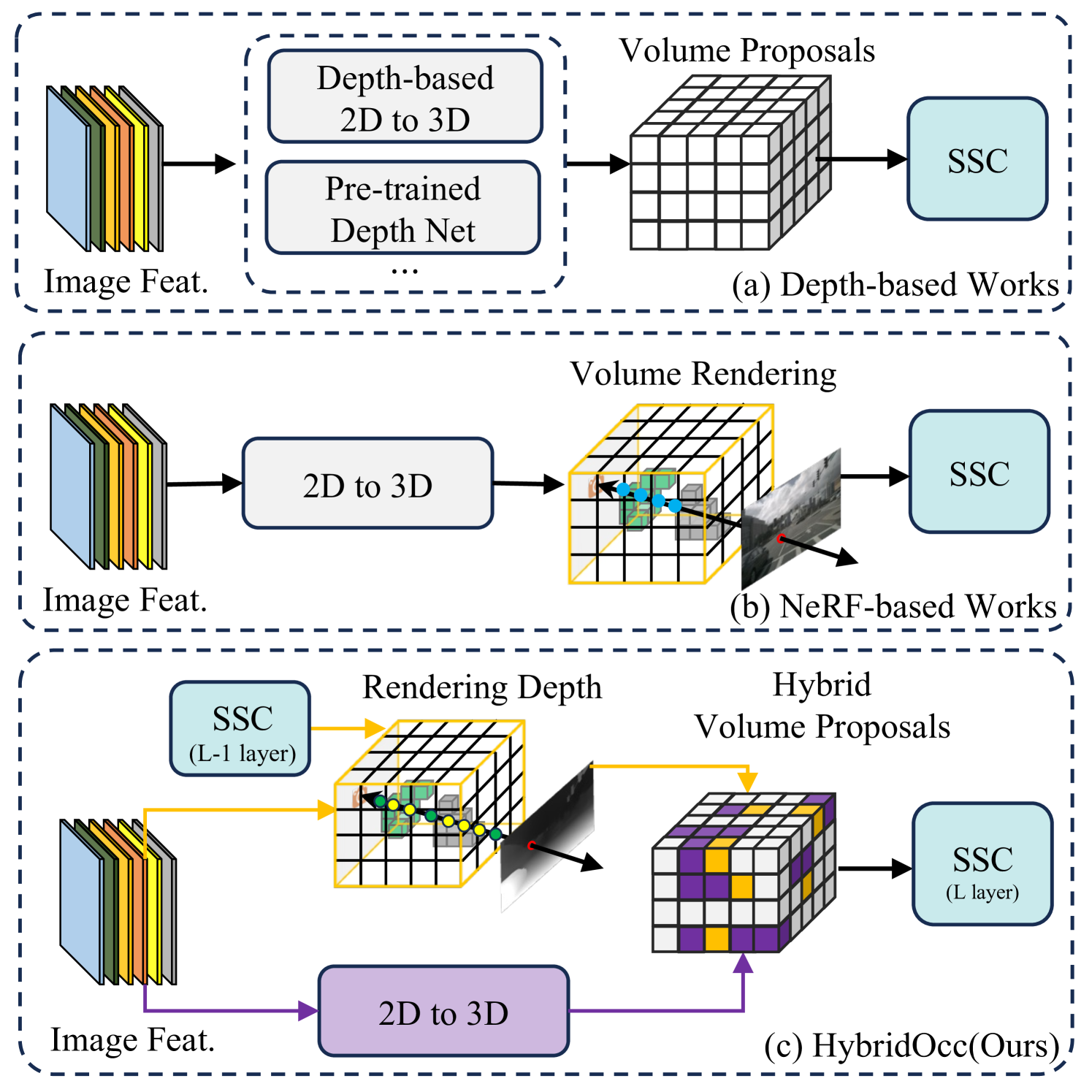
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Xiao Zhao, Bo Chen, Mingyang Sun, Dingkang Yang, Youxing Wang, Xukun Zhang, Mingcheng Li, Dongliang Kou, Xiaoyi Wei, Lihua Zhang
Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
Read more8/20/2024

0
GaussianFormer: Scene as Gaussians for Vision-Based 3D Semantic Occupancy Prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, Jiwen Lu
3D semantic occupancy prediction aims to obtain 3D fine-grained geometry and semantics of the surrounding scene and is an important task for the robustness of vision-centric autonomous driving. Most existing methods employ dense grids such as voxels as scene representations, which ignore the sparsity of occupancy and the diversity of object scales and thus lead to unbalanced allocation of resources. To address this, we propose an object-centric representation to describe 3D scenes with sparse 3D semantic Gaussians where each Gaussian represents a flexible region of interest and its semantic features. We aggregate information from images through the attention mechanism and iteratively refine the properties of 3D Gaussians including position, covariance, and semantics. We then propose an efficient Gaussian-to-voxel splatting method to generate 3D occupancy predictions, which only aggregates the neighboring Gaussians for a certain position. We conduct extensive experiments on the widely adopted nuScenes and KITTI-360 datasets. Experimental results demonstrate that GaussianFormer achieves comparable performance with state-of-the-art methods with only 17.8% - 24.8% of their memory consumption. Code is available at: https://github.com/huang-yh/GaussianFormer.
Read more5/28/2024