$epsilon$-VAE: Denoising as Visual Decoding

3
✅
Sign in to get full access
Overview
- Generative modeling simplifies complex data into compact, structured representations for efficient, learnable models.
- Current visual tokenization methods use an autoencoder framework, where an encoder compresses data into latent representations and a decoder reconstructs the original input.
- This paper proposes a new approach that replaces the decoder with a diffusion process, shifting from single-step reconstruction to iterative refinement.
Plain English Explanation
In the field of generative modeling, researchers aim to create efficient and learnable representations of complex data. One common technique is tokenization, which simplifies high-dimensional visual data by reducing redundancy and emphasizing key features.
Traditionally, this is done using an autoencoder framework. An encoder compresses the data into compact latent representations, and a decoder tries to reconstruct the original input from those latents.
In this paper, the researchers propose a new approach. Instead of a traditional decoder, they use a diffusion process that iteratively refines noise to recover the original image, guided by the latents from the encoder. This shifts the focus from single-step reconstruction to an iterative refinement process.
Technical Explanation
The core idea of this work is to replace the traditional decoder in an autoencoder framework with a diffusion process. Diffusion models work by gradually adding noise to an image and then learning to reverse that process, refining the noisy image back to the original.
The researchers' key innovation is to guide this diffusion process using the latent representations from the encoder. This allows the model to focus the refinement on the most important features, rather than trying to reconstruct the entire image from scratch.
The researchers evaluate their approach by assessing both the quality of reconstructions (rFID) and the quality of generated images (FID), comparing it to state-of-the-art autoencoding methods. Their results show improvements in both metrics, suggesting that this approach of integrating iterative generation with autoencoding can lead to better compression and generation of visual data.
Critical Analysis
The paper presents a novel and promising approach to visual tokenization, but there are a few potential limitations and areas for further research:
- The experiments are conducted on relatively simple datasets like MNIST and CelebA. It would be valuable to see how the model performs on more complex, high-resolution imagery.
- The paper does not deeply explore the interpretability or disentanglement of the learned latent representations. Understanding the properties of these latents could lead to further insights.
- The computational efficiency of the iterative diffusion process is not discussed in detail. Ensuring the model can be deployed efficiently would be an important practical consideration.
Overall, this work offers an intriguing new perspective on integrating iterative generation and autoencoding for improved visual representation learning. Further research to address these areas could yield additional insights and advancements in the field.
Conclusion
This paper proposes a new approach to visual tokenization that replaces the traditional decoder in an autoencoder framework with a diffusion process. By guiding the iterative refinement of noisy images using latent representations, the model is able to achieve better reconstruction and generation quality compared to state-of-the-art autoencoding methods.
The researchers' insights highlight the potential benefits of combining iterative generation and autoencoding for more efficient and effective visual representation learning. As the field of generative modeling continues to advance, this work offers a promising direction for further exploration and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
3
$epsilon$-VAE: Denoising as Visual Decoding
Long Zhao, Sanghyun Woo, Ziyu Wan, Yandong Li, Han Zhang, Boqing Gong, Hartwig Adam, Xuhui Jia, Ting Liu
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
Read more10/8/2024

0
Edge-based Denoising Image Compression
Ryugo Morita, Hitoshi Nishimura, Ko Watanabe, Andreas Dengel, Jinjia Zhou
In recent years, deep learning-based image compression, particularly through generative models, has emerged as a pivotal area of research. Despite significant advancements, challenges such as diminished sharpness and quality in reconstructed images, learning inefficiencies due to mode collapse, and data loss during transmission persist. To address these issues, we propose a novel compression model that incorporates a denoising step with diffusion models, significantly enhancing image reconstruction fidelity by sub-information(e.g., edge and depth) from leveraging latent space. Empirical experiments demonstrate that our model achieves superior or comparable results in terms of image quality and compression efficiency when measured against the existing models. Notably, our model excels in scenarios of partial image loss or excessive noise by introducing an edge estimation network to preserve the integrity of reconstructed images, offering a robust solution to the current limitations of image compression.
Read more9/18/2024
🔗
0
LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, Romann M. Weber
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
Read more5/24/2024
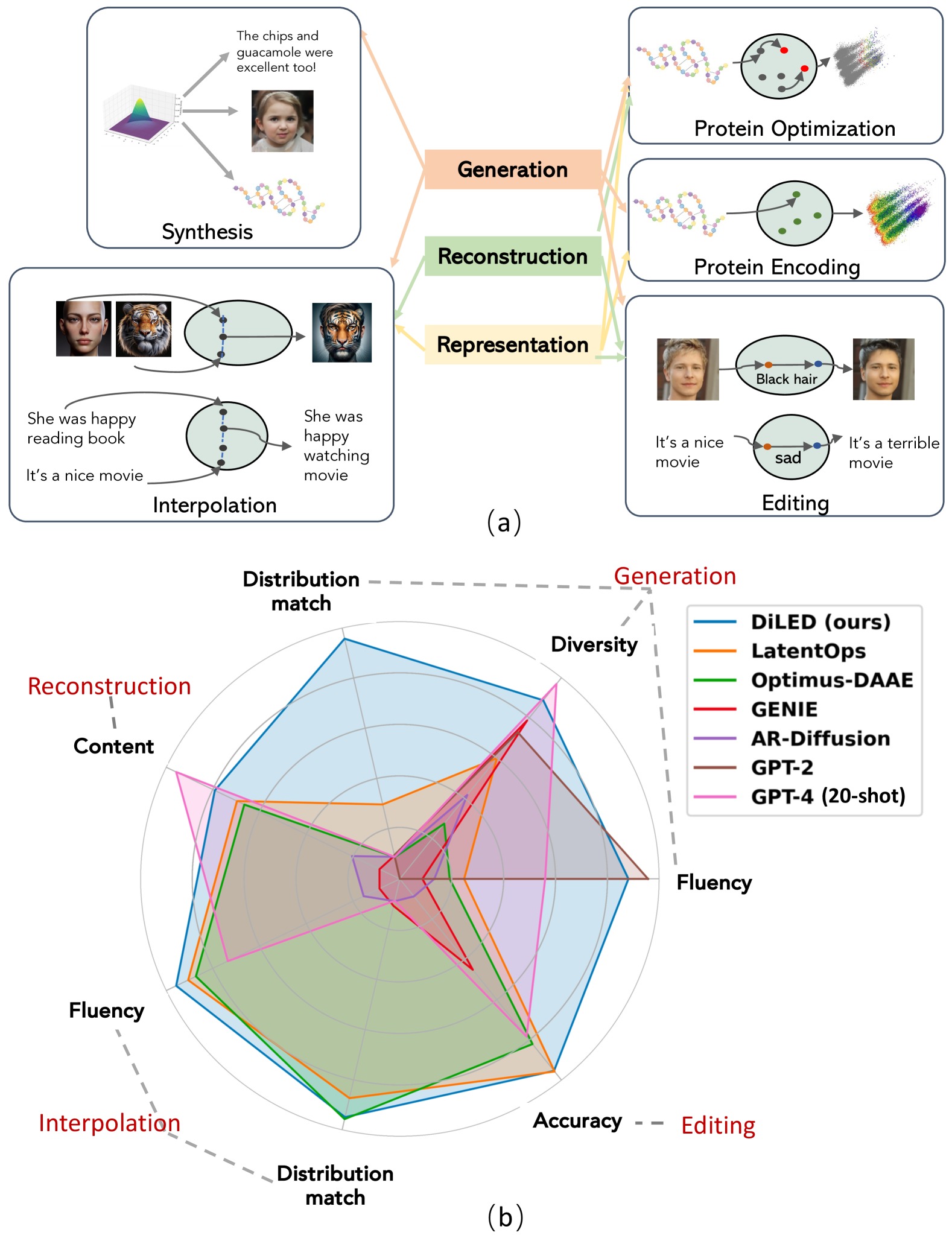
0
Unified Generation, Reconstruction, and Representation: Generalized Diffusion with Adaptive Latent Encoding-Decoding
Guangyi Liu, Yu Wang, Zeyu Feng, Qiyu Wu, Liping Tang, Yuan Gao, Zhen Li, Shuguang Cui, Julian McAuley, Zichao Yang, Eric P. Xing, Zhiting Hu
The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like variational autoencoders (VAEs), generative adversarial networks (GANs), autoregressive models, and (latent) diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce Generalized Encoding-Decoding Diffusion Probabilistic Models (EDDPMs) which integrate the core capabilities for broad applicability and enhanced performance. EDDPMs generalize the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, EDDPMs are compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), EDDPMs naturally apply to different data types. Extensive experiments on text, proteins, and images demonstrate the flexibility to handle diverse data and tasks and the strong improvement over various existing models.
Read more6/6/2024