$textit{S}^3$Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
2405.20323
0
0

Abstract
Photorealistic 3D reconstruction of street scenes is a critical technique for developing real-world simulators for autonomous driving. Despite the efficacy of Neural Radiance Fields (NeRF) for driving scenes, 3D Gaussian Splatting (3DGS) emerges as a promising direction due to its faster speed and more explicit representation. However, most existing street 3DGS methods require tracked 3D vehicle bounding boxes to decompose the static and dynamic elements for effective reconstruction, limiting their applications for in-the-wild scenarios. To facilitate efficient 3D scene reconstruction without costly annotations, we propose a self-supervised street Gaussian ($textit{S}^3$Gaussian) method to decompose dynamic and static elements from 4D consistency. We represent each scene with 3D Gaussians to preserve the explicitness and further accompany them with a spatial-temporal field network to compactly model the 4D dynamics. We conduct extensive experiments on the challenging Waymo-Open dataset to evaluate the effectiveness of our method. Our $textit{S}^3$Gaussian demonstrates the ability to decompose static and dynamic scenes and achieves the best performance without using 3D annotations. Code is available at: https://github.com/nnanhuang/S3Gaussian/.
Create account to get full access
Overview
- This paper introduces "S³Gaussian", a self-supervised method for learning street-aware Gaussian representations from unlabeled street-level imagery for autonomous driving applications.
- The key idea is to learn low-dimensional Gaussian representations of the 3D scene geometry that can capture the structured nature of urban environments.
- The authors demonstrate that these learned representations can benefit several downstream tasks, including depth estimation, semantic segmentation, and 3D scene understanding.
Plain English Explanation
The researchers have developed a new way to teach computers to understand street scenes for self-driving cars. They use a technique called "self-supervised learning" to train their system without needing a lot of manually labeled data.
The core of their approach is to learn a special kind of 3D representation called a "Gaussian" that can capture the structure of urban environments. These Gaussian representations are compact and efficient, but still contain a lot of useful information about the 3D geometry of the scene.
By learning these street-aware Gaussian representations in a self-supervised way, the researchers show that their system can then be applied to various other tasks like estimating the depth of objects, identifying different semantic elements (like roads, buildings, etc.), and generally understanding the 3D structure of the environment. This can be very helpful for enabling autonomous vehicles to safely navigate city streets.
The key advantage of this approach is that it can learn these powerful 3D representations without needing a lot of time-consuming manual labeling of training data. Instead, the system can discover the structure of streets and urban scenes on its own by just observing a lot of unlabeled street-level imagery.
Technical Explanation
The core technical contribution of this paper is the "S³Gaussian" framework, which learns low-dimensional Gaussian representations of the 3D scene geometry in a self-supervised manner.
The authors start by capturing a large dataset of street-level images and corresponding 3D point clouds. They then devise a self-supervised pretraining objective that encourages the network to learn Gaussian representations that can accurately reconstruct the observed 3D points.
Specifically, each 3D point is modeled as a Gaussian distribution, with the network predicting the parameters (mean and covariance) of these Gaussians from the input image. The network is trained to minimize the distance between the predicted Gaussians and the ground truth 3D points.
This self-supervised pretraining allows the network to discover the underlying 3D structure of urban environments without any manual labeling. The authors then show that these learned S³Gaussian representations can be effectively fine-tuned and transferred to a variety of downstream tasks, such as depth estimation, semantic segmentation, and 3D scene understanding.
Through extensive experiments, the authors demonstrate that their self-supervised S³Gaussian approach outperforms fully-supervised baselines on these tasks, highlighting the value of learning rich, structured 3D representations from unlabeled street data.
Critical Analysis
The key strength of this work is the ability to learn powerful 3D representations in a self-supervised manner, which can then be leveraged for a variety of downstream tasks relevant to autonomous driving. This is an important advance, as manually annotating 3D data is extremely time-consuming and costly.
That said, the paper does not provide a deep analysis of the limitations of the S³Gaussian representations. For example, it's unclear how well these representations would generalize to significantly different environments beyond the urban scenes used in the training data. Additionally, the computational and memory requirements of the Gaussian representations could be a concern for real-time deployment in self-driving cars.
Further research is needed to better understand the trade-offs and failure modes of this approach, as well as explore ways to make the representations more compact and efficient. Incorporating additional self-supervised objectives or leveraging complementary 3D sensing modalities could also be fruitful avenues for improvement.
Overall, this work represents an exciting step forward in self-supervised 3D representation learning for autonomous driving, but there is still significant room for further refinement and exploration.
Conclusion
The "S³Gaussian" method presented in this paper is a promising approach for learning rich, structured 3D representations of urban environments in a self-supervised manner. By modeling the 3D scene as a collection of Gaussian distributions, the system can capture the underlying geometry and structure of streets and buildings, which can then be effectively leveraged for a variety of downstream perception tasks critical for autonomous driving.
The key advantage of this technique is its ability to learn these powerful 3D representations without requiring extensive manual labeling of training data, which is a major bottleneck in many machine learning applications for self-driving cars. If further developed and refined, the S³Gaussian approach could significantly accelerate progress in building robust and capable autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
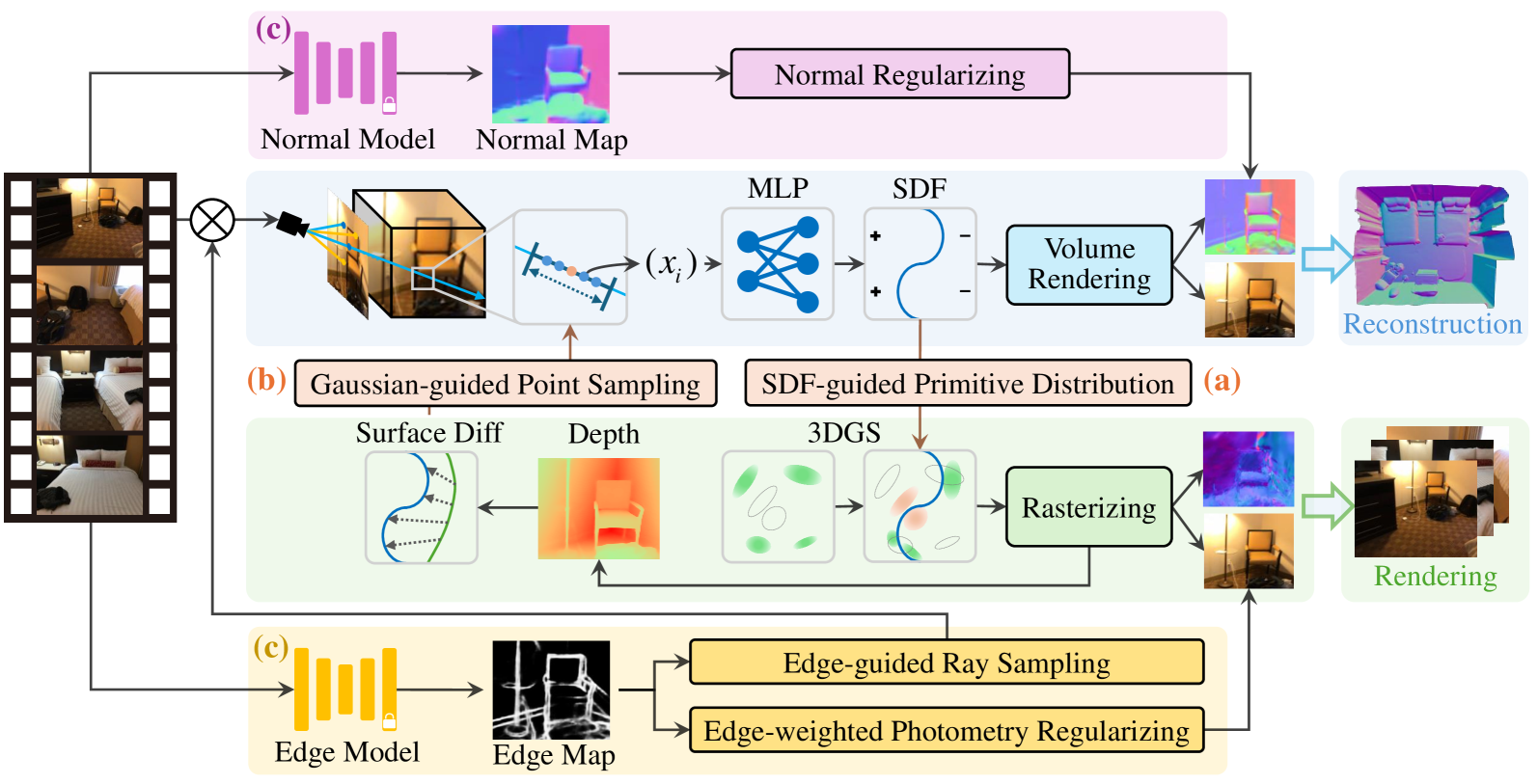
GaussianRoom: Improving 3D Gaussian Splatting with SDF Guidance and Monocular Cues for Indoor Scene Reconstruction
Haodong Xiang, Xinghui Li, Xiansong Lai, Wanting Zhang, Zhichao Liao, Kai Cheng, Xueping Liu
0
0
Recently, 3D Gaussian Splatting(3DGS) has revolutionized neural rendering with its high-quality rendering and real-time speed. However, when it comes to indoor scenes with a significant number of textureless areas, 3DGS yields incomplete and noisy reconstruction results due to the poor initialization of the point cloud and under-constrained optimization. Inspired by the continuity of signed distance field (SDF), which naturally has advantages in modeling surfaces, we present a unified optimizing framework integrating neural SDF with 3DGS. This framework incorporates a learnable neural SDF field to guide the densification and pruning of Gaussians, enabling Gaussians to accurately model scenes even with poor initialized point clouds. At the same time, the geometry represented by Gaussians improves the efficiency of the SDF field by piloting its point sampling. Additionally, we regularize the optimization with normal and edge priors to eliminate geometry ambiguity in textureless areas and improve the details. Extensive experiments in ScanNet and ScanNet++ show that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis.
5/31/2024
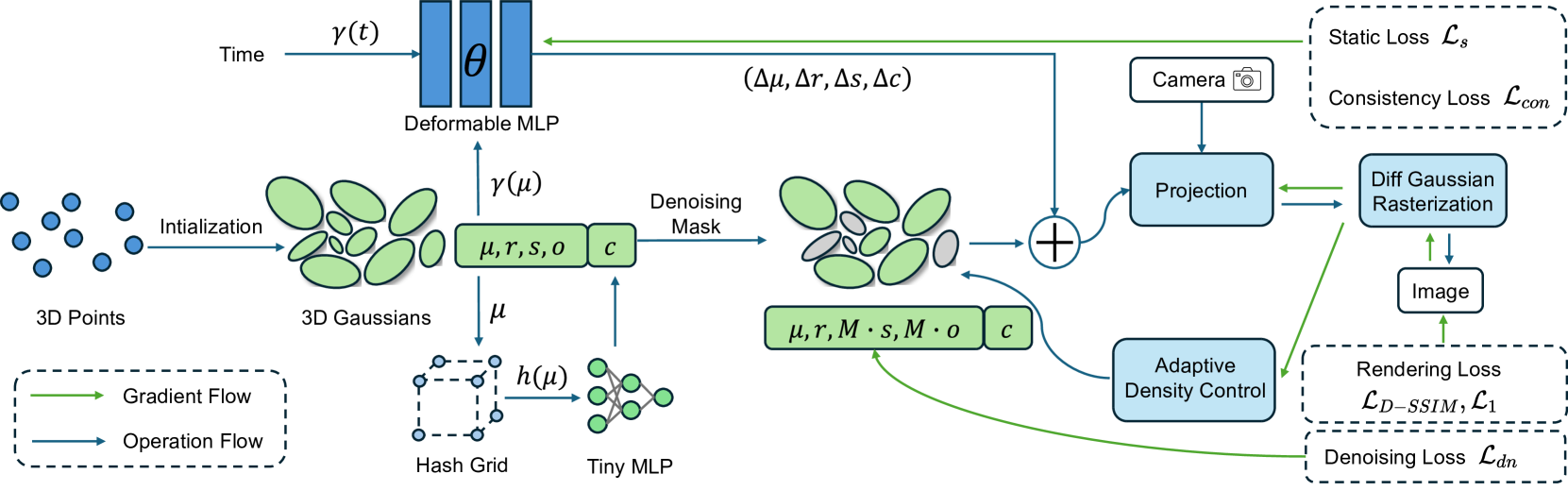
A Refined 3D Gaussian Representation for High-Quality Dynamic Scene Reconstruction
Bin Zhang, Bi Zeng, Zexin Peng
0
0
In recent years, Neural Radiance Fields (NeRF) has revolutionized three-dimensional (3D) reconstruction with its implicit representation. Building upon NeRF, 3D Gaussian Splatting (3D-GS) has departed from the implicit representation of neural networks and instead directly represents scenes as point clouds with Gaussian-shaped distributions. While this shift has notably elevated the rendering quality and speed of radiance fields but inevitably led to a significant increase in memory usage. Additionally, effectively rendering dynamic scenes in 3D-GS has emerged as a pressing challenge. To address these concerns, this paper purposes a refined 3D Gaussian representation for high-quality dynamic scene reconstruction. Firstly, we use a deformable multi-layer perceptron (MLP) network to capture the dynamic offset of Gaussian points and express the color features of points through hash encoding and a tiny MLP to reduce storage requirements. Subsequently, we introduce a learnable denoising mask coupled with denoising loss to eliminate noise points from the scene, thereby further compressing 3D Gaussian model. Finally, motion noise of points is mitigated through static constraints and motion consistency constraints. Experimental results demonstrate that our method surpasses existing approaches in rendering quality and speed, while significantly reducing the memory usage associated with 3D-GS, making it highly suitable for various tasks such as novel view synthesis, and dynamic mapping.
5/29/2024

Compact 3D Scene Representation via Self-Organizing Gaussian Grids
Wieland Morgenstern, Florian Barthel, Anna Hilsmann, Peter Eisert
0
0
3D Gaussian Splatting has recently emerged as a highly promising technique for modeling of static 3D scenes. In contrast to Neural Radiance Fields, it utilizes efficient rasterization allowing for very fast rendering at high-quality. However, the storage size is significantly higher, which hinders practical deployment, e.g. on resource constrained devices. In this paper, we introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering. Central to our idea is the explicit exploitation of perceptual redundancies present in natural scenes. In essence, the inherent nature of a scene allows for numerous permutations of Gaussian parameters to equivalently represent it. To this end, we propose a novel highly parallel algorithm that regularly arranges the high-dimensional Gaussian parameters into a 2D grid while preserving their neighborhood structure. During training, we further enforce local smoothness between the sorted parameters in the grid. The uncompressed Gaussians use the same structure as 3DGS, ensuring a seamless integration with established renderers. Our method achieves a reduction factor of 17x to 42x in size for complex scenes with no increase in training time, marking a substantial leap forward in the domain of 3D scene distribution and consumption. Additional information can be found on our project page: https://fraunhoferhhi.github.io/Self-Organizing-Gaussians/
5/3/2024

Dynamic 3D Gaussian Fields for Urban Areas
Tobias Fischer, Jonas Kulhanek, Samuel Rota Bul`o, Lorenzo Porzi, Marc Pollefeys, Peter Kontschieder
0
0
We present an efficient neural 3D scene representation for novel-view synthesis (NVS) in large-scale, dynamic urban areas. Existing works are not well suited for applications like mixed-reality or closed-loop simulation due to their limited visual quality and non-interactive rendering speeds. Recently, rasterization-based approaches have achieved high-quality NVS at impressive speeds. However, these methods are limited to small-scale, homogeneous data, i.e. they cannot handle severe appearance and geometry variations due to weather, season, and lighting and do not scale to larger, dynamic areas with thousands of images. We propose 4DGF, a neural scene representation that scales to large-scale dynamic urban areas, handles heterogeneous input data, and substantially improves rendering speeds. We use 3D Gaussians as an efficient geometry scaffold while relying on neural fields as a compact and flexible appearance model. We integrate scene dynamics via a scene graph at global scale while modeling articulated motions on a local level via deformations. This decomposed approach enables flexible scene composition suitable for real-world applications. In experiments, we surpass the state-of-the-art by over 3 dB in PSNR and more than 200 times in rendering speed.
6/6/2024