Domain Adaptation for Contrastive Audio-Language Models

0

Sign in to get full access
Overview
- Introduces a method for adapting contrastive audio-language models to new domains
- Evaluates the approach on audio classification and retrieval tasks across diverse datasets
- Demonstrates improved performance compared to existing domain adaptation techniques
Plain English Explanation
Domain Adaptation for Contrastive Audio-Language Models describes a technique for adapting pre-trained contrastive audio-language models to perform well on new datasets or "domains". These models learn to match audio and text inputs that describe the same content, and can be used for tasks like audio classification and retrieval.
The key idea is to fine-tune the pre-trained model on a smaller "target" dataset, while also encouraging it to maintain its performance on the original "source" dataset. This helps the model adapt to the new domain while retaining its general capabilities. The approach is evaluated on several audio classification and retrieval benchmarks, showing improved performance compared to other domain adaptation methods.
Technical Explanation
Contrastive Audio-Language Models are a type of multimodal model that learn to align audio and text inputs representing the same content. They are trained on large datasets to embed audio and text in a shared representation space, allowing them to perform tasks like classifying audio clips or retrieving relevant text given an audio query.
The proposed approach fine-tunes these pre-trained models on a new "target" dataset, while also encouraging the model to maintain its performance on the original "source" dataset. This is achieved through a combination of standard fine-tuning and a novel "domain preservation" objective, which encourages the model to preserve its source-domain representations.
The authors evaluate this approach on several audio classification and retrieval tasks, comparing it to standard fine-tuning and other domain adaptation techniques. The results show that their method outperforms these baselines, demonstrating the effectiveness of the domain preservation objective.
Critical Analysis
The paper provides a thorough evaluation of the proposed domain adaptation approach, testing it across multiple datasets and tasks. The authors acknowledge some limitations, such as the need for labeled target-domain data and the potential for overfitting to the target domain.
One area for further research could be exploring unsupervised or semi-supervised adaptation methods, which could reduce the reliance on labeled target-domain data. Additionally, the authors could investigate the model's ability to adapt to more diverse or challenging domains beyond the evaluated benchmarks.
Overall, the paper presents a promising technique for adapting contrastive audio-language models to new domains, with potential applications in areas like audio-based information retrieval and assistive technology.
Conclusion
Domain Adaptation for Contrastive Audio-Language Models introduces a method for adapting pre-trained contrastive audio-language models to new domains, leveraging a domain preservation objective to maintain performance on the original dataset. The approach demonstrates improved results on audio classification and retrieval tasks compared to existing domain adaptation techniques, highlighting its potential to expand the applicability of these powerful multimodal models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain Adaptation for Contrastive Audio-Language Models
Soham Deshmukh, Rita Singh, Bhiksha Raj
Audio-Language Models (ALM) aim to be general-purpose audio models by providing zero-shot capabilities at test time. The zero-shot performance of ALM improves by using suitable text prompts for each domain. The text prompts are usually hand-crafted through an ad-hoc process and lead to a drop in ALM generalization and out-of-distribution performance. Existing approaches to improve domain performance, like few-shot learning or fine-tuning, require access to annotated data and iterations of training. Therefore, we propose a test-time domain adaptation method for ALMs that does not require access to annotations. Our method learns a domain vector by enforcing consistency across augmented views of the testing audio. We extensively evaluate our approach on 12 downstream tasks across domains. With just one example, our domain adaptation method leads to 3.2% (max 8.4%) average zero-shot performance improvement. After adaptation, the model still retains the generalization property of ALMs.
Read more7/23/2024
🤖
0
Enhancing Audio-Language Models through Self-Supervised Post-Training with Text-Audio Pairs
Anshuman Sinha, Camille Migozzi, Aubin Rey, Chao Zhang
Research on multi-modal contrastive learning strategies for audio and text has rapidly gained interest. Contrastively trained Audio-Language Models (ALMs), such as CLAP, which establish a unified representation across audio and language modalities, have enhanced the efficacy in various subsequent tasks by providing good text aligned audio encoders and vice versa. These improvements are evident in areas like zero-shot audio classification and audio retrieval, among others. However, the ability of these models to understand natural language and temporal relations is still a largely unexplored and open field for research. In this paper, we propose to equip the multi-modal ALMs with temporal understanding without loosing their inherent prior capabilities of audio-language tasks with a temporal instillation method TeminAL. We implement a two-stage training scheme TeminAL A $&$ B, where the model first learns to differentiate between multiple sounds in TeminAL A, followed by a phase that instills a sense of time, thereby enhancing its temporal understanding in TeminAL B. This approach results in an average performance gain of $5.28%$ in temporal understanding on the ESC-50 dataset, while the model remains competitive in zero-shot retrieval and classification tasks on the AudioCap/Clotho datasets. We also note the lack of proper evaluation techniques for contrastive ALMs and propose a strategy for evaluating ALMs in zero-shot settings. The general-purpose zero-shot model evaluation strategy ZSTE, is used to evaluate various prior models. ZSTE demonstrates a general strategy to evaluate all ZS contrastive models. The model trained with TeminAL successfully outperforms current models on most downstream tasks.
Read more8/20/2024
0
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Yiming Zhang, Xuenan Xu, Ruoyi Du, Haohe Liu, Yuan Dong, Zheng-Hua Tan, Wenwu Wang, Zhanyu Ma
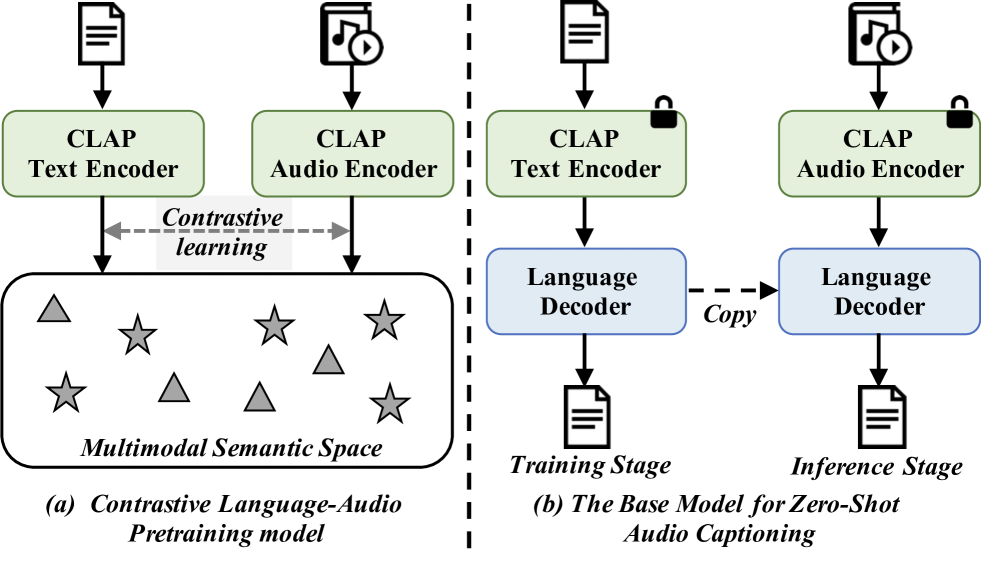
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
Read more6/11/2024
0
Unified Language-driven Zero-shot Domain Adaptation
Senqiao Yang, Zhuotao Tian, Li Jiang, Jiaya Jia
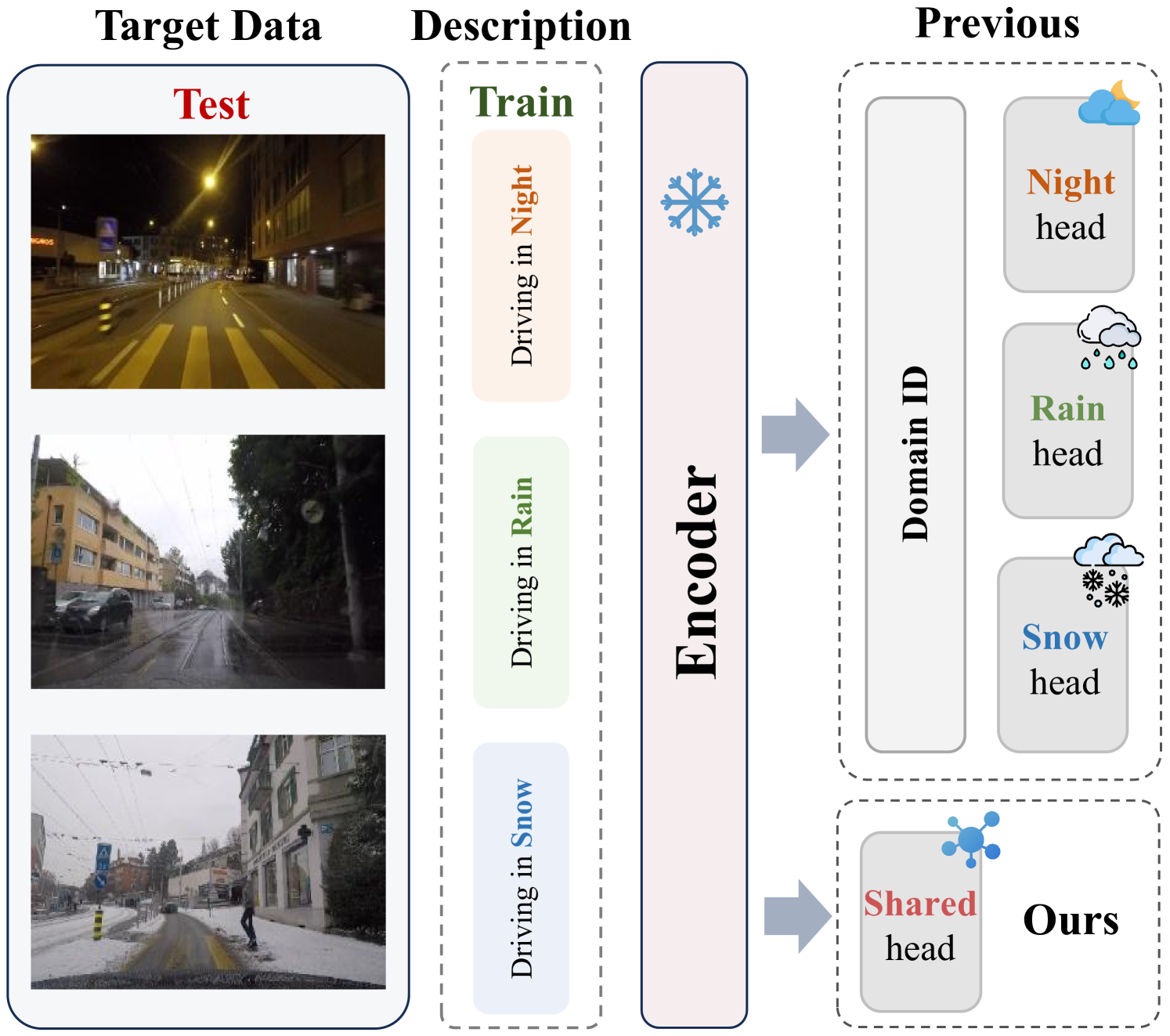
This paper introduces Unified Language-driven Zero-shot Domain Adaptation (ULDA), a novel task setting that enables a single model to adapt to diverse target domains without explicit domain-ID knowledge. We identify the constraints in the existing language-driven zero-shot domain adaptation task, particularly the requirement for domain IDs and domain-specific models, which may restrict flexibility and scalability. To overcome these issues, we propose a new framework for ULDA, consisting of Hierarchical Context Alignment (HCA), Domain Consistent Representation Learning (DCRL), and Text-Driven Rectifier (TDR). These components work synergistically to align simulated features with target text across multiple visual levels, retain semantic correlations between different regional representations, and rectify biases between simulated and real target visual features, respectively. Our extensive empirical evaluations demonstrate that this framework achieves competitive performance in both settings, surpassing even the model that requires domain-ID, showcasing its superiority and generalization ability. The proposed method is not only effective but also maintains practicality and efficiency, as it does not introduce additional computational costs during inference. Our project page is https://senqiaoyang.com/project/ULDA .
Read more4/11/2024