Zero-Shot Audio Captioning Using Soft and Hard Prompts
2406.06295
0
0
Abstract
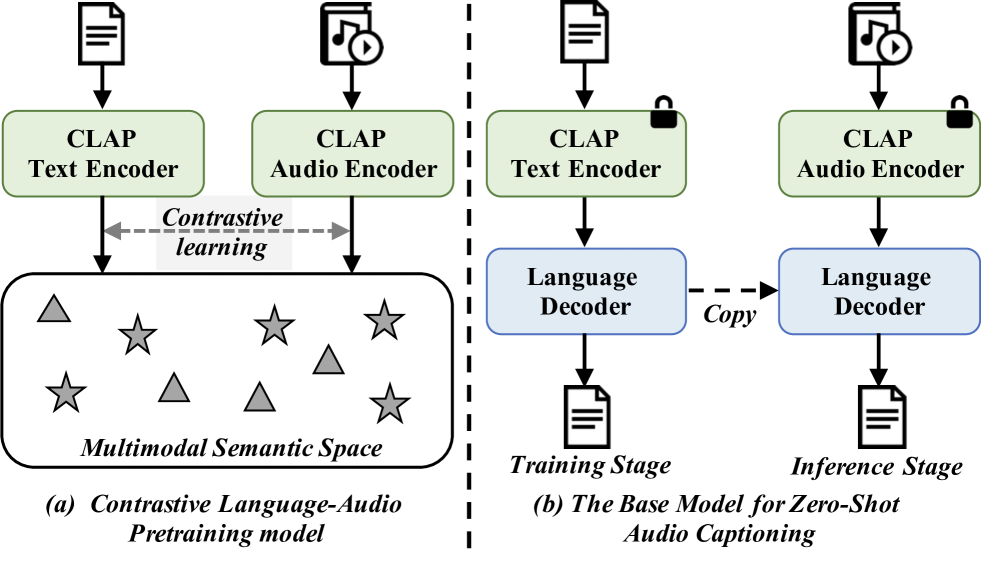
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
Create account to get full access
Overview
- This paper introduces a novel approach for zero-shot audio captioning using soft and hard prompts.
- The method leverages contrastive language-audio pre-training to learn a joint embedding space between audio and text, enabling the generation of captions for unseen audio.
- The authors explore different prompt engineering techniques, including soft prompts that allow for flexible text generation and hard prompts that enforce specific sentence structures.
- Experiments on benchmark datasets demonstrate the effectiveness of the proposed approach in generating high-quality captions without any audio-text paired data during fine-tuning.
Plain English Explanation
The paper presents a new way to automatically generate descriptions for audio recordings, even if the system hasn't seen examples of those specific sounds before. This is called "zero-shot" captioning, meaning the model can produce captions for audio it hasn't been trained on.
The key idea is to first train the system on a large amount of audio-text data, learning how sound and language are related. This allows the model to build a shared "embedding space" where audio and text are represented in a way that captures their underlying connections.
During the zero-shot captioning stage, the researchers experiment with different techniques for guiding the text generation process. "Soft prompts" give the model more flexibility to generate diverse captions, while "hard prompts" enforce a specific sentence structure. By leveraging this pre-training and prompt engineering, the system can produce high-quality captions for audio it's never encountered before.
This advance in zero-shot audio captioning could have applications in areas like audio-visual generalized zero-shot learning, where models need to understand novel audio inputs without seeing labeled examples. It also builds on prior work in retrieval-enhanced zero-shot video captioning and temporal-enhanced contrastive language-audio pre-training.
Technical Explanation
The paper proposes a novel approach for zero-shot audio captioning that leverages contrastive language-audio pre-training and prompt engineering. The key elements of the technical approach are:
-
Contrastive Language-Audio Pre-training: The authors first train a model on a large dataset of audio-text pairs using a contrastive learning objective. This allows the model to learn a joint embedding space where corresponding audio and text are brought closer together, while unrelated pairs are pushed apart. This pre-trained model serves as the foundation for the zero-shot captioning task.
-
Soft and Hard Prompts: During the zero-shot captioning stage, the authors experiment with different prompt engineering techniques. "Soft prompts" are open-ended text sequences that provide high-level guidance to the language model, allowing for more flexible and diverse caption generation. In contrast, "hard prompts" enforce a specific sentence structure, giving the model less freedom but potentially producing captions that better match the audio input.
-
Evaluation on Benchmark Datasets: The proposed approach is evaluated on several audio captioning datasets, including CLOTHO and AudioCaps. The results demonstrate the effectiveness of the zero-shot captioning method, as it is able to generate high-quality captions without any audio-text paired data during fine-tuning.
Critical Analysis
The paper presents a promising approach for zero-shot audio captioning, leveraging contrastive pre-training and prompt engineering to achieve impressive results. However, there are a few potential areas for further research and improvement:
-
Prompt Engineering Exploration: While the paper explores soft and hard prompts, there may be additional prompt engineering techniques that could further enhance the caption quality and diversity. An in-depth analysis of different prompt strategies and their impact on the model's performance could lead to additional insights.
-
Generalization to Longer Audio Inputs: The current evaluation focuses on short audio clips, but it would be interesting to see how the zero-shot captioning approach scales to longer, more complex audio samples. This could involve additional architectural or training modifications to handle variable-length inputs.
-
Multimodal Synergies: Given the paper's focus on audio-text relationships, exploring ways to integrate visual information could lead to even more powerful multimodal zero-shot captioning models. Leveraging visual contexts alongside the audio could further improve the generated captions.
-
Interpretability and Explainability: As the model learns to map audio to text, it would be valuable to gain insights into the internal representations and decision-making processes. Developing techniques to interpret and explain the model's reasoning could lead to a better understanding of its strengths and limitations.
Overall, the paper presents an innovative approach to zero-shot audio captioning that demonstrates the potential of contrastive pre-training and prompt engineering. Further research building on these ideas could lead to even more robust and versatile audio captioning systems.
Conclusion
This paper introduces a novel zero-shot audio captioning method that leverages contrastive language-audio pre-training and prompt engineering. By learning a joint embedding space between audio and text, the model is able to generate high-quality captions for audio samples it has not encountered before. The exploration of soft and hard prompts provides flexible yet structured ways to guide the text generation process.
The proposed approach represents an important advance in the field of audio understanding, with potential applications in areas like audio-visual generalized zero-shot learning. While the results are promising, the authors also identify opportunities for further research, such as exploring additional prompt engineering techniques, scaling to longer audio inputs, and integrating multimodal information. Continued progress in zero-shot audio captioning could lead to more accessible and intelligent audio-based systems that can understand and describe the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024
🔍
RECAP: Retrieval-Augmented Audio Captioning
Sreyan Ghosh, Sonal Kumar, Chandra Kiran Reddy Evuru, Ramani Duraiswami, Dinesh Manocha
0
0
We present RECAP (REtrieval-Augmented Audio CAPtioning), a novel and effective audio captioning system that generates captions conditioned on an input audio and other captions similar to the audio retrieved from a datastore. Additionally, our proposed method can transfer to any domain without the need for any additional fine-tuning. To generate a caption for an audio sample, we leverage an audio-text model CLAP to retrieve captions similar to it from a replaceable datastore, which are then used to construct a prompt. Next, we feed this prompt to a GPT-2 decoder and introduce cross-attention layers between the CLAP encoder and GPT-2 to condition the audio for caption generation. Experiments on two benchmark datasets, Clotho and AudioCaps, show that RECAP achieves competitive performance in in-domain settings and significant improvements in out-of-domain settings. Additionally, due to its capability to exploit a large text-captions-only datastore in a training-free fashion, RECAP shows unique capabilities of captioning novel audio events never seen during training and compositional audios with multiple events. To promote research in this space, we also release 150,000+ new weakly labeled captions for AudioSet, AudioCaps, and Clotho.
6/7/2024
T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
Yi Yuan, Zhuo Chen, Xubo Liu, Haohe Liu, Xuenan Xu, Dongya Jia, Yuanzhe Chen, Mark D. Plumbley, Wenwu Wang
0
0
Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.
4/30/2024
🤯
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
0
0
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
6/26/2024