Domain Adaptation for Large-Vocabulary Object Detectors

0

Sign in to get full access
Introduction
This paper explores the problem of domain adaptation for large-vocabulary object detectors. Object detectors are AI models that can identify and locate objects in images, but they often struggle when applied to images from a different domain (e.g., a detector trained on indoor scenes may perform poorly on outdoor scenes). The authors propose a novel approach to address this challenge.
Related Works
The paper situates its work within the broader context of domain adaptation research. It notes the challenges of adapting object detectors to new domains, and discusses prior work that has explored techniques like domain adversarial training and knowledge distillation to address this problem.
Method
Language Knowledge Graph Distillation
The key innovation in this paper is a method called "Language Knowledge Graph Distillation". The core idea is to leverage large language models, which have learned rich semantic representations of objects and their relationships, to help adapt object detectors to new domains.
The process works as follows:
- A large language model is used to construct a "knowledge graph" representing the semantic relationships between different object classes.
- This knowledge graph is then "distilled" into the object detector model, encouraging it to learn representations that align with the semantic structure encoded in the language model.
- This helps the detector generalize better to new domains, as it has learned a more robust and transferable set of object representations.
The authors show that this approach outperforms other domain adaptation techniques on a range of challenging benchmarks.
Technical Explanation
The paper first trains a large language model (such as BERT) on a broad corpus of text data. This allows the model to learn rich semantic representations of different object classes and how they are related to each other.
Next, the authors construct a "knowledge graph" from the language model. This graph encodes the semantic relationships between object classes as a set of nodes (representing objects) and edges (representing relationships).
The key innovation is then to "distill" this language-based knowledge graph into the object detector model. This is done by adding an additional loss term that encourages the detector to align its internal representations with the structure of the knowledge graph.
Specifically, the detector is trained to minimize two losses: 1) the standard object detection loss (e.g., bounding box regression and classification), and 2) a "knowledge distillation" loss that measures the discrepancy between the detector's internal representations and the semantic structure of the knowledge graph.
The authors demonstrate the effectiveness of this approach through extensive experiments on large-scale object detection benchmarks. They show that the language-guided adaptation consistently outperforms other domain adaptation techniques, particularly for detecting rare or unseen object classes.
Critical Analysis
The key strength of this work is its principled approach to leveraging rich semantic knowledge from language models to improve the domain adaptation capabilities of object detectors. By distilling this language-based knowledge into the detector, the authors are able to learn more robust and transferable representations.
That said, the approach does rely on the availability of a high-quality language model, which may not always be the case, especially for low-resource domains. Additionally, the authors do not explore how the performance of the language model itself may impact the final object detection results.
Another potential limitation is the computational overhead of the knowledge distillation process, which may make the approach less practical for real-time or resource-constrained applications.
Conclusion
Overall, this paper presents a novel and compelling approach to addressing the challenge of domain adaptation for large-vocabulary object detectors. By incorporating semantic knowledge from language models, the authors have developed a technique that can significantly improve the performance of object detectors when applied to new domains.
While there are some potential practical considerations, this work represents an important step forward in building more robust and generalizable object recognition systems. It also highlights the potential benefits of leveraging cross-modal knowledge transfer, which could have applications in other areas of computer vision and AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain Adaptation for Large-Vocabulary Object Detectors
Kai Jiang, Jiaxing Huang, Weiying Xie, Jie Lei, Yunsong Li, Ling Shao, Shijian Lu
Large-vocabulary object detectors (LVDs) aim to detect objects of many categories, which learn super objectness features and can locate objects accurately while applied to various downstream data. However, LVDs often struggle in recognizing the located objects due to domain discrepancy in data distribution and object vocabulary. At the other end, recent vision-language foundation models such as CLIP demonstrate superior open-vocabulary recognition capability. This paper presents KGD, a Knowledge Graph Distillation technique that exploits the implicit knowledge graphs (KG) in CLIP for effectively adapting LVDs to various downstream domains. KGD consists of two consecutive stages: 1) KG extraction that employs CLIP to encode downstream domain data as nodes and their feature distances as edges, constructing KG that inherits the rich semantic relations in CLIP explicitly; and 2) KG encapsulation that transfers the extracted KG into LVDs to enable accurate cross-domain object classification. In addition, KGD can extract both visual and textual KG independently, providing complementary vision and language knowledge for object localization and object classification in detection tasks over various downstream domains. Experiments over multiple widely adopted detection benchmarks show that KGD outperforms the state-of-the-art consistently by large margins.
Read more5/13/2024

0
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Liang Yao, Fan Liu, Chuanyi Zhang, Zhiquan Ou, Ting Wu
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
Read more8/22/2024

0
Learning Background Prompts to Discover Implicit Knowledge for Open Vocabulary Object Detection
Jiaming Li, Jiacheng Zhang, Jichang Li, Ge Li, Si Liu, Liang Lin, Guanbin Li
Open vocabulary object detection (OVD) aims at seeking an optimal object detector capable of recognizing objects from both base and novel categories. Recent advances leverage knowledge distillation to transfer insightful knowledge from pre-trained large-scale vision-language models to the task of object detection, significantly generalizing the powerful capabilities of the detector to identify more unknown object categories. However, these methods face significant challenges in background interpretation and model overfitting and thus often result in the loss of crucial background knowledge, giving rise to sub-optimal inference performance of the detector. To mitigate these issues, we present a novel OVD framework termed LBP to propose learning background prompts to harness explored implicit background knowledge, thus enhancing the detection performance w.r.t. base and novel categories. Specifically, we devise three modules: Background Category-specific Prompt, Background Object Discovery, and Inference Probability Rectification, to empower the detector to discover, represent, and leverage implicit object knowledge explored from background proposals. Evaluation on two benchmark datasets, OV-COCO and OV-LVIS, demonstrates the superiority of our proposed method over existing state-of-the-art approaches in handling the OVD tasks.
Read more6/4/2024
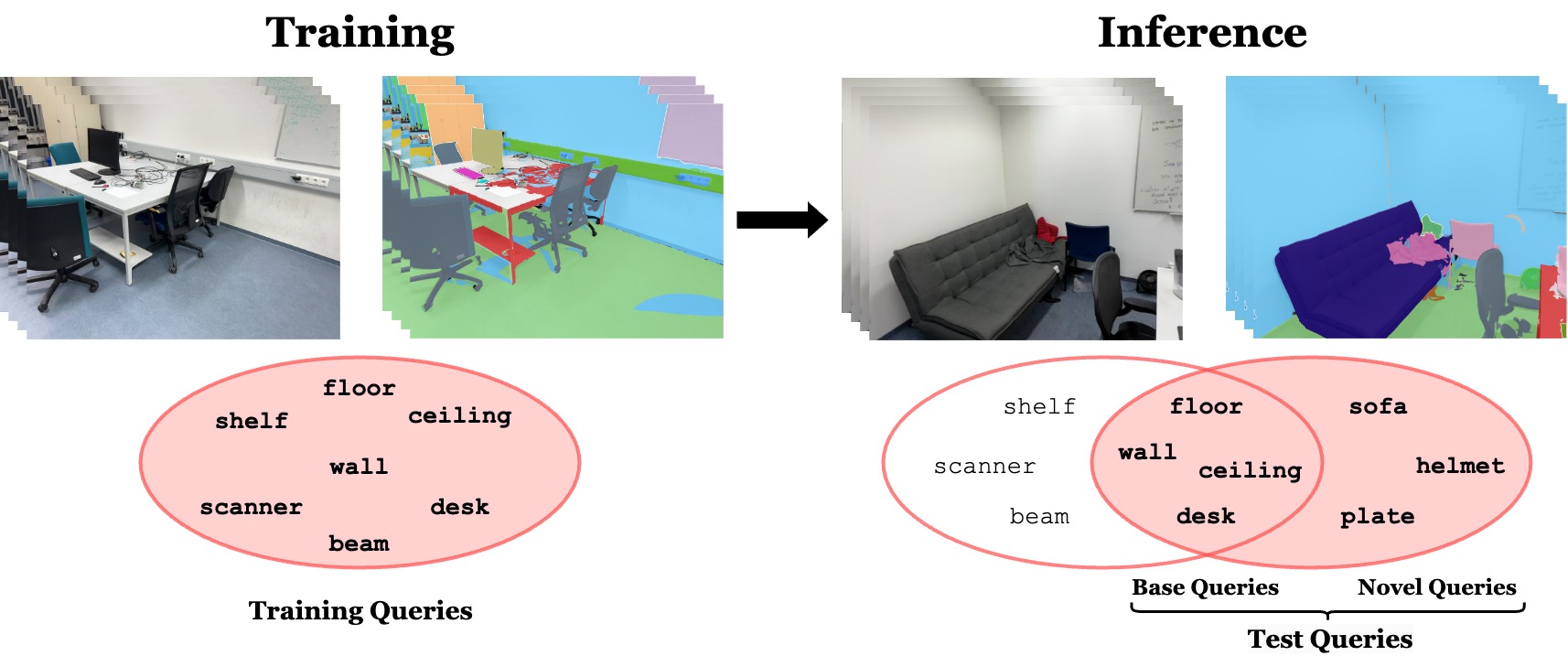
0
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
Read more5/31/2024