A Minimalist Prompt for Zero-Shot Policy Learning

0
Sign in to get full access
Overview
- Presents a minimalist prompt for zero-shot policy learning, where an agent can learn a new task without any task-specific training data or reward function
- Leverages language models and simple prompts to enable agents to quickly learn and execute diverse tasks in new environments
- Experimental results demonstrate the effectiveness of this approach on a range of simulated and real-world tasks
Plain English Explanation
This paper introduces a new approach for training AI agents to quickly learn and perform a wide variety of tasks, even if they've never seen that specific task before. The key idea is to use language models - powerful AI systems that can understand and generate human-like text.
By providing the agent with a simple prompt - a short description of the task in natural language - the agent can leverage the knowledge stored in the language model to figure out how to solve the task, without needing any prior training on that specific task. This is called "zero-shot" learning, because the agent learns to do something new without any examples or practice.
The researchers show that this minimalist prompt-based approach allows agents to successfully complete many different simulated and real-world tasks, from navigation to manipulation to problem-solving. This is an exciting step towards more flexible and capable AI systems that can quickly adapt to new situations, just like humans can.
The visual prompting and transitive vision-language prompt learning techniques are related approaches that also leverage prompts and language models for flexible task learning. The soft prompt generation and plug-and-play prompts papers explore ways to customize and optimize prompts for different applications.
Technical Explanation
The paper proposes a minimalist approach for zero-shot policy learning, where an agent can learn to solve a new task from a simple natural language prompt, without any task-specific training data or reward function.
The key components are:
- Language Model: The agent leverages a large, pre-trained language model to understand the semantics of the task prompt and map it to the appropriate actions.
- Prompt Engineering: The researchers carefully design the structure and content of the task prompts to provide the necessary information for the agent to infer the desired behavior.
- Policy Optimization: The agent then uses reinforcement learning to optimize its policy based on the prompt and the environmental feedback, enabling it to efficiently execute the task.
Experimental results on a range of simulated and real-world tasks demonstrate the effectiveness of this minimalist prompt-based approach. Compared to standard reinforcement learning methods, the zero-shot agents are able to quickly learn and execute diverse tasks with limited training.
This work builds upon recent advancements in vision-language prompt learning and prompt tuning for flexible task adaptation. The soft prompt generation approach is also relevant, as it explores ways to automatically optimize prompt representations.
Critical Analysis
The paper presents a promising approach for enabling zero-shot task learning, but there are several important limitations and areas for further research:
- Task Complexity: While the method works well for the tasks considered, it's unclear how well it would scale to more complex, open-ended tasks that require deeper reasoning and planning.
- Prompt Engineering: The success of the approach relies heavily on carefully crafting the task prompts. Automating this process or making it more robust to prompt variation is an important challenge.
- Safety and Reliability: Deploying these zero-shot agents in the real world raises concerns about safety, robustness, and reliable task execution. Addressing these issues is crucial for practical applications.
- Interpretability: The inner workings of the language model-based policy are not fully transparent, making it difficult to understand and debug the agent's behavior.
Overall, this work represents an exciting step towards more flexible and capable AI systems. However, further research is needed to improve the scalability, robustness, and interpretability of zero-shot policy learning approaches.
Conclusion
This paper introduces a minimalist prompt-based approach for zero-shot policy learning, where an agent can quickly learn and execute a wide variety of tasks in new environments, without any task-specific training. By leveraging the semantic understanding of language models, the agent can infer the appropriate actions from simple natural language prompts, enabling rapid adaptation to novel tasks.
The experimental results demonstrate the effectiveness of this approach on simulated and real-world tasks, suggesting that it could be a promising direction for developing more flexible and capable AI systems. However, there are still important challenges to address, such as scaling to more complex tasks, improving prompt engineering, ensuring safety and reliability, and enhancing the interpretability of the learned policies.
As the field of AI continues to advance, techniques like zero-shot policy learning may play a crucial role in enabling AI agents to seamlessly adapt to new situations and tasks, just as humans can. This could lead to significant breakthroughs in areas like robotics, decision-making, and problem-solving, with far-reaching implications for both research and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Minimalist Prompt for Zero-Shot Policy Learning
Meng Song, Xuezhi Wang, Tanay Biradar, Yao Qin, Manmohan Chandraker
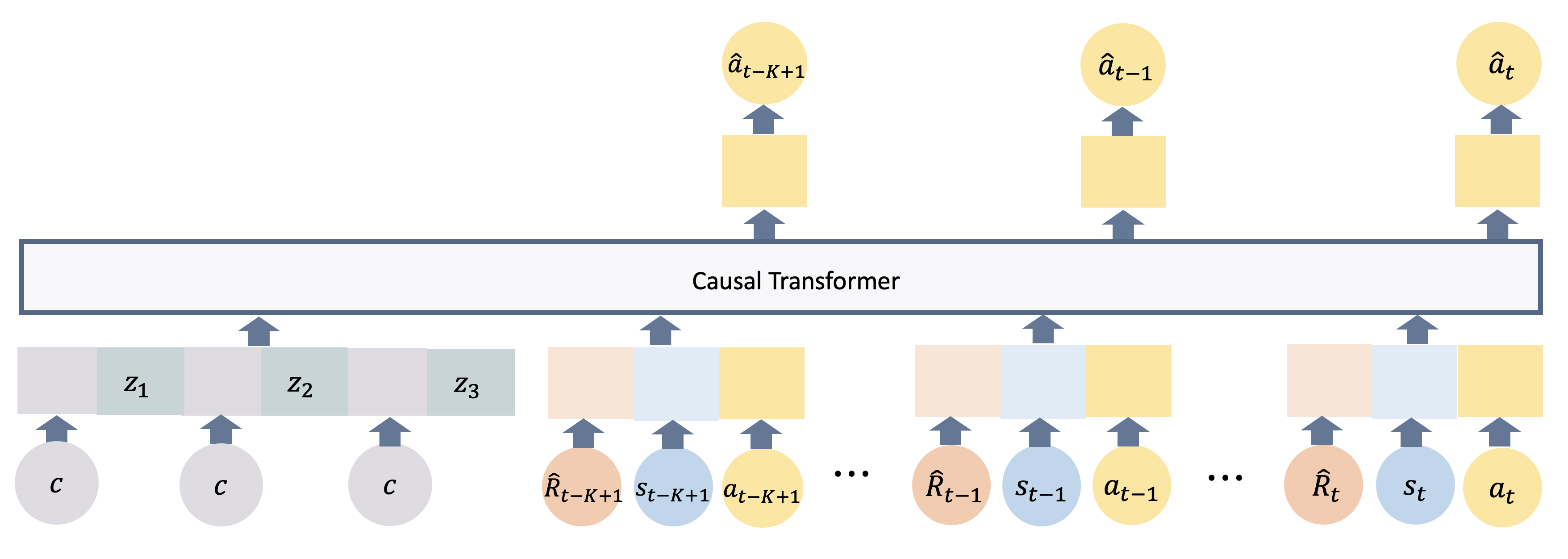
Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.
Read more5/13/2024

0
Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models
Zijun Wu, Yongkang Wu, Lili Mou
Prompt tuning in natural language processing (NLP) has become an increasingly popular method for adapting large language models to specific tasks. However, the transferability of these prompts, especially continuous prompts, between different models remains a challenge. In this work, we propose a zero-shot continuous prompt transfer method, where source prompts are encoded into relative space and the corresponding target prompts are searched for transferring to target models. Experimental results confirm the effectiveness of our method, showing that 'task semantics' in continuous prompts can be generalized across various language models. Moreover, we find that combining 'task semantics' from multiple source models can further enhance the generalizability of transfer.
Read more7/15/2024

0
Improving Zero-shot Generalization of Learned Prompts via Unsupervised Knowledge Distillation
Marco Mistretta, Alberto Baldrati, Marco Bertini, Andrew D. Bagdanov
Vision-Language Models (VLMs) demonstrate remarkable zero-shot generalization to unseen tasks, but fall short of the performance of supervised methods in generalizing to downstream tasks with limited data. Prompt learning is emerging as a parameter-efficient method for adapting VLMs, but state-of-the-art approaches require annotated samples. In this paper we propose a novel approach to prompt learning based on unsupervised knowledge distillation from more powerful models. Our approach, which we call Knowledge Distillation Prompt Learning (KDPL), can be integrated into existing prompt learning techniques and eliminates the need for labeled examples during adaptation. Our experiments on more than ten standard benchmark datasets demonstrate that KDPL is very effective at improving generalization of learned prompts for zero-shot domain generalization, zero-shot cross-dataset generalization, and zero-shot base-to-novel class generalization problems. KDPL requires no ground-truth labels for adaptation, and moreover we show that even in the absence of any knowledge of training class names it can be used to effectively transfer knowledge. The code is publicly available at https://github.com/miccunifi/KDPL.
Read more7/31/2024

0
Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer
Yu Yang, Pan Xu
Decision Transformer (DT) has emerged as a promising class of algorithms in offline reinforcement learning (RL) tasks, leveraging pre-collected datasets and Transformer's capability to model long sequences. Recent works have demonstrated that using parts of trajectories from training tasks as prompts in DT enhances its performance on unseen tasks, giving rise to Prompt-DT methods. However, collecting data from specific environments can be both costly and unsafe in many scenarios, leading to suboptimal performance and limited few-shot prompt abilities due to the data-hungry nature of Transformer-based models. Additionally, the limited datasets used in pre-training make it challenging for Prompt-DT type of methods to distinguish between various RL tasks through prompts alone. To address these challenges, we introduce the Language model-initialized Prompt Decision Transformer (LPDT), which leverages pre-trained language models for meta-RL tasks and fine-tunes the model using Low-rank Adaptation (LoRA). We further incorporate prompt regularization to effectively differentiate between tasks based on prompt feature representations. Our approach integrates pre-trained language model and RL tasks seamlessly. Extensive empirical studies demonstrate that initializing with a pre-trained language model significantly enhances the performance of Prompt-DT on unseen tasks compared to baseline methods.
Read more8/6/2024