Domain Generalizable Knowledge Tracing via Concept Aggregation and Relation-Based Attention

0

Sign in to get full access
Overview
- This paper proposes a novel method for knowledge tracing that can generalize across different domains.
- The key ideas are concept aggregation and relation-based attention.
- The method aims to capture the underlying knowledge concepts and their relationships, enabling better performance on unseen domains.
Plain English Explanation
The paper introduces a new way to track student knowledge that can work well across different subjects or "domains." Traditional knowledge tracing models often struggle when applied to new domains, but this approach tries to overcome that challenge.
The core idea is to focus on the underlying knowledge concepts that students are learning, rather than just the specific questions or exercises. By understanding how these concepts relate to each other, the model can better generalize its knowledge tracing to new scenarios.
This is done through a couple key techniques. First, the model aggregates the knowledge concepts that are involved in each learning activity. This allows the model to build a more holistic understanding of the student's knowledge.
Secondly, the model uses relation-based attention to capture the relationships between these different knowledge concepts. This helps the model understand how the concepts connect and build on each other, which is crucial for effective knowledge tracing.
By taking this conceptual, relational approach, the model is able to generalize its knowledge tracing capabilities to new domains that it wasn't trained on originally. This could be very valuable for intelligent tutoring systems that need to work across a wide range of subject areas.
Technical Explanation
The proposed model, called CARATA, consists of two key components: concept aggregation and relation-based attention.
The concept aggregation module takes the student's response history and the associated knowledge concepts, and aggregates the concepts into a unified representation. This allows the model to build a more holistic understanding of the student's knowledge state, rather than just focusing on individual skills or questions.
The relation-based attention module then models the relationships between these aggregated knowledge concepts. It learns to attend to the relevant concepts and their connections when predicting the student's future performance. This relational understanding is crucial for generalizing the model's knowledge tracing ability to new domains.
The authors evaluate CARATA on several knowledge tracing benchmarks, including a dataset with multiple domains. They show that CARATA outperforms a range of baseline models, including those that use domain adaptation techniques. This demonstrates the effectiveness of the concept aggregation and relation-based attention components for enabling cross-domain knowledge tracing.
Critical Analysis
The paper presents a compelling approach to the challenge of domain generalization in knowledge tracing. By shifting the focus to the underlying knowledge concepts and their relationships, the model is able to more effectively transfer its learning to new scenarios.
However, one potential limitation is the reliance on having accurate knowledge concept annotations for the training data. In real-world educational settings, it may be difficult or costly to obtain such detailed concept mappings for all learning activities. The authors acknowledge this as an area for future work, suggesting the incorporation of unsupervised concept discovery.
Additionally, while the authors demonstrate the model's performance on cross-domain benchmarks, it would be valuable to see evaluations in more naturalistic educational settings. The ability to generalize across different courses, curricula, or tutoring systems within the same institution could be an important real-world test of the model's capabilities.
Overall, the CARATA approach represents an interesting and promising direction for advancing the state of the art in knowledge tracing. Further research and development in this area could lead to significant improvements in the effectiveness and scalability of intelligent tutoring systems.
Conclusion
This paper introduces a novel knowledge tracing model called CARATA that can generalize its performance across different domains. By focusing on the underlying knowledge concepts and their relationships, rather than just specific questions or skills, CARATA is able to more effectively transfer its learning to new scenarios.
The key innovations are the concept aggregation and relation-based attention components, which allow the model to build a more holistic and relational understanding of student knowledge. This conceptual, cross-domain approach represents an important advancement in the field of knowledge tracing, with potential benefits for the development of intelligent tutoring systems that can adapt to a wide range of educational contexts.
While the paper demonstrates promising results, further research is needed to address challenges like the reliance on annotated knowledge concepts and evaluations in real-world educational settings. Nonetheless, the CARATA model presents an exciting step forward in the quest to create personalized, adaptive learning experiences that can truly meet the needs of diverse learners.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain Generalizable Knowledge Tracing via Concept Aggregation and Relation-Based Attention
Yuquan Xie, Wanqi Yang, Jinyu Wei, Ming Yang, Yang Gao
Knowledge Tracing (KT) is a critical task in online education systems, aiming to monitor students' knowledge states throughout a learning period. Common KT approaches involve predicting the probability of a student correctly answering the next question based on their exercise history. However, these methods often suffer from performance degradation when faced with the scarcity of student interactions in new education systems. To address this, we leverage student interactions from existing education systems to mitigate performance degradation caused by limited training data. Nevertheless, these interactions exhibit significant differences since they are derived from different education systems. To address this issue, we propose a domain generalization approach for knowledge tracing, where existing education systems are considered source domains, and new education systems with limited data are considered target domains. Additionally, we design a domain-generalizable knowledge tracing framework (DGKT) that can be applied to any KT model. Specifically, we present a concept aggregation approach designed to reduce conceptual disparities within sequences of student interactions from diverse domains. To further mitigate domain discrepancies, we introduce a novel normalization module called Sequence Instance Normalization (SeqIN). Moreover, to fully leverage exercise information, we propose a new knowledge tracing model tailored for the domain generalization KT task, named Domain-Generalizable Relation-based Knowledge Tracing (DGRKT). Extensive experiments across five benchmark datasets demonstrate that the proposed method performs well despite limited training data.
Read more7/4/2024

0
Leveraging Pedagogical Theories to Understand Student Learning Process with Graph-based Reasonable Knowledge Tracing
Jiajun Cui, Hong Qian, Bo Jiang, Wei Zhang
Knowledge tracing (KT) is a crucial task in intelligent education, focusing on predicting students' performance on given questions to trace their evolving knowledge. The advancement of deep learning in this field has led to deep-learning knowledge tracing (DLKT) models that prioritize high predictive accuracy. However, many existing DLKT methods overlook the fundamental goal of tracking students' dynamical knowledge mastery. These models do not explicitly model knowledge mastery tracing processes or yield unreasonable results that educators find difficulty to comprehend and apply in real teaching scenarios. In response, our research conducts a preliminary analysis of mainstream KT approaches to highlight and explain such unreasonableness. We introduce GRKT, a graph-based reasonable knowledge tracing method to address these issues. By leveraging graph neural networks, our approach delves into the mutual influences of knowledge concepts, offering a more accurate representation of how the knowledge mastery evolves throughout the learning process. Additionally, we propose a fine-grained and psychological three-stage modeling process as knowledge retrieval, memory strengthening, and knowledge learning/forgetting, to conduct a more reasonable knowledge tracing process. Comprehensive experiments demonstrate that GRKT outperforms eleven baselines across three datasets, not only enhancing predictive accuracy but also generating more reasonable knowledge tracing results. This makes our model a promising advancement for practical implementation in educational settings. The source code is available at https://github.com/JJCui96/GRKT.
Read more6/21/2024
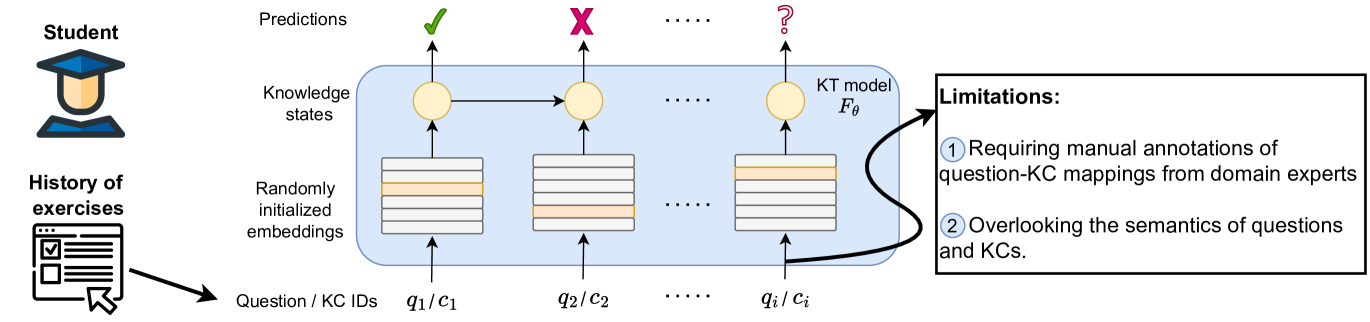
0
New!Automated Knowledge Concept Annotation and Question Representation Learning for Knowledge Tracing
Yilmazcan Ozyurt, Stefan Feuerriegel, Mrinmaya Sachan
Knowledge tracing (KT) is a popular approach for modeling students' learning progress over time, which can enable more personalized and adaptive learning. However, existing KT approaches face two major limitations: (1) they rely heavily on expert-defined knowledge concepts (KCs) in questions, which is time-consuming and prone to errors; and (2) KT methods tend to overlook the semantics of both questions and the given KCs. In this work, we address these challenges and present KCQRL, a framework for automated knowledge concept annotation and question representation learning that can improve the effectiveness of any existing KT model. First, we propose an automated KC annotation process using large language models (LLMs), which generates question solutions and then annotates KCs in each solution step of the questions. Second, we introduce a contrastive learning approach to generate semantically rich embeddings for questions and solution steps, aligning them with their associated KCs via a tailored false negative elimination approach. These embeddings can be readily integrated into existing KT models, replacing their randomly initialized embeddings. We demonstrate the effectiveness of KCQRL across 15 KT algorithms on two large real-world Math learning datasets, where we achieve consistent performance improvements.
Read more10/3/2024
⚙️
0
Explainable Few-shot Knowledge Tracing
Haoxuan Li, Jifan Yu, Yuanxin Ouyang, Zhuang Liu, Wenge Rong, Juanzi Li, Zhang Xiong
Knowledge tracing (KT), aiming to mine students' mastery of knowledge by their exercise records and predict their performance on future test questions, is a critical task in educational assessment. While researchers achieved tremendous success with the rapid development of deep learning techniques, current knowledge tracing tasks fall into the cracks from real-world teaching scenarios. Relying heavily on extensive student data and solely predicting numerical performances differs from the settings where teachers assess students' knowledge state from limited practices and provide explanatory feedback. To fill this gap, we explore a new task formulation: Explainable Few-shot Knowledge Tracing. By leveraging the powerful reasoning and generation abilities of large language models (LLMs), we then propose a cognition-guided framework that can track the student knowledge from a few student records while providing natural language explanations. Experimental results from three widely used datasets show that LLMs can perform comparable or superior to competitive deep knowledge tracing methods. We also discuss potential directions and call for future improvements in relevant topics.
Read more5/28/2024