Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation

0

Sign in to get full access
Overview
- This paper proposes a novel approach for online test-time adaptation of deep learning models, called Domain-Specific Block Selection and Paired-View Pseudo-Labeling (DSBS-PVPL).
- The key ideas are to selectively update the model's weights based on domain-specific feature blocks, and to leverage paired-view pseudo-labels to improve adaptation performance.
- The method is designed to work in an online setting, where the model needs to adapt to new data during deployment without access to the original training data.
Plain English Explanation
The paper describes a way for AI models to automatically adapt and improve their performance when applied to new data, without requiring access to the original training data. This is an important capability, as AI models are often deployed in the real world where the data they encounter may differ from the data they were trained on.
The proposed approach, DSBS-PVPL, works by selectively updating parts of the model's neural network based on the specific features of the new data. It also generates pseudo-labels for the new data, using the model's own predictions, to further help the adaptation process. This allows the model to continuously learn and improve itself as it encounters new situations, without the need to go back and retrain on the original training data.
The key innovation is the selective weight updating and the use of pseudo-labels, which help the model adapt in an efficient and effective way. This is particularly useful for applications where the input data can change over time, such as in autonomous vehicles, medical imaging, or environmental monitoring.
Technical Explanation
The DSBS-PVPL approach consists of two main components:
-
Domain-Specific Block Selection (DSBS): The model's neural network is divided into different feature blocks, and only the blocks that are most relevant to the new domain are selectively updated during the adaptation process. This helps prevent catastrophic forgetting and ensures the model retains its performance on the original task.
-
Paired-View Pseudo-Labeling (PVPL): The model's predictions on the new data are used to generate pseudo-labels, which are then used to further fine-tune the model. This helps the model learn from the new data, even when ground-truth labels are not available.
The authors evaluate their approach on several computer vision tasks, including image classification and semantic segmentation, and show that it outperforms other state-of-the-art test-time adaptation methods.
Critical Analysis
The paper presents a well-designed and empirically validated approach for online test-time adaptation. The selective weight updating and pseudo-labeling techniques are novel and seem effective at allowing the model to adapt to new domains without forgetting its original capabilities.
One potential limitation is that the approach assumes the availability of paired-view data, which may not always be the case in real-world applications. The authors mention that their method could be extended to handle single-view data, but this would likely require additional research and experimentation.
Additionally, the paper does not explore the robustness of the approach to noisy or adversarial inputs, which is an important consideration for real-world deployment. Further investigation into the method's sensitivity to different types of distribution shift would be valuable.
Conclusion
The DSBS-PVPL method proposed in this paper represents an important advancement in the field of test-time adaptation, enabling AI models to continuously improve their performance on new data without catastrophic forgetting. The selective weight updating and pseudo-labeling techniques are innovative and show promise for a wide range of applications where model adaptation is crucial.
While the paper has some limitations, the core ideas and empirical results suggest that this approach could have a significant impact on the deployment of robust and adaptable AI systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation
Yeonguk Yu, Sungho Shin, Seunghyeok Back, Minhwan Ko, Sangjun Noh, Kyoobin Lee
Test-time adaptation (TTA) aims to adapt a pre-trained model to a new test domain without access to source data after deployment. Existing approaches typically rely on self-training with pseudo-labels since ground-truth cannot be obtained from test data. Although the quality of pseudo labels is important for stable and accurate long-term adaptation, it has not been previously addressed. In this work, we propose DPLOT, a simple yet effective TTA framework that consists of two components: (1) domain-specific block selection and (2) pseudo-label generation using paired-view images. Specifically, we select blocks that involve domain-specific feature extraction and train these blocks by entropy minimization. After blocks are adjusted for current test domain, we generate pseudo-labels by averaging given test images and corresponding flipped counterparts. By simply using flip augmentation, we prevent a decrease in the quality of the pseudo-labels, which can be caused by the domain gap resulting from strong augmentation. Our experimental results demonstrate that DPLOT outperforms previous TTA methods in CIFAR10-C, CIFAR100-C, and ImageNet-C benchmarks, reducing error by up to 5.4%, 9.1%, and 2.9%, respectively. Also, we provide an extensive analysis to demonstrate effectiveness of our framework. Code is available at https://github.com/gist-ailab/domain-specific-block-selection-and-paired-view-pseudo-labeling-for-online-TTA.
Read more5/8/2024
0
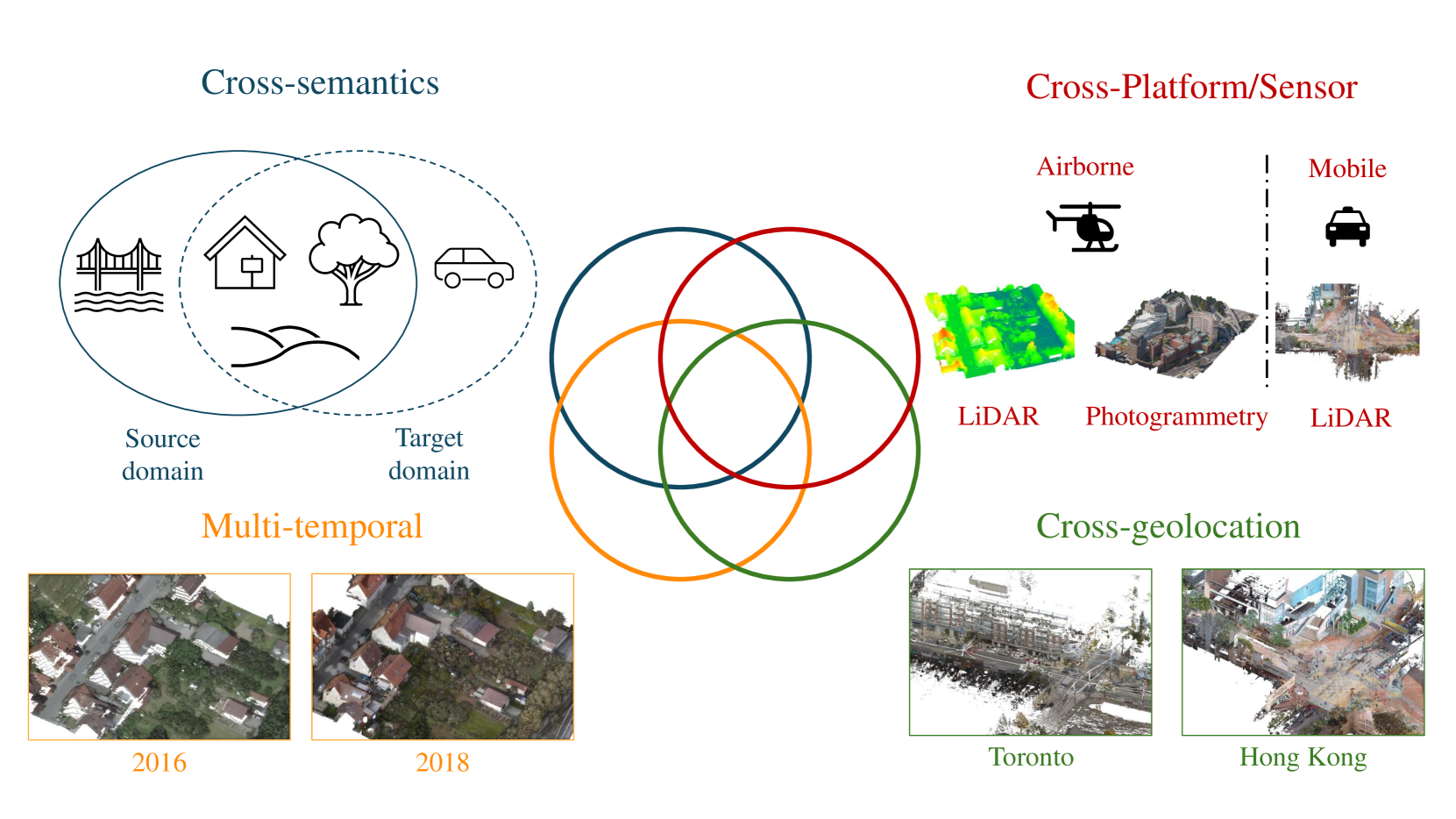
Test-time adaptation for geospatial point cloud semantic segmentation with distinct domain shifts
Puzuo Wang, Wei Yao, Jie Shao, Zhiyi He
Domain adaptation (DA) techniques help deep learning models generalize across data shifts for point cloud semantic segmentation (PCSS). Test-time adaptation (TTA) allows direct adaptation of a pre-trained model to unlabeled data during inference stage without access to source data or additional training, avoiding privacy issues and large computational resources. We address TTA for geospatial PCSS by introducing three domain shift paradigms: photogrammetric to airborne LiDAR, airborne to mobile LiDAR, and synthetic to mobile laser scanning. We propose a TTA method that progressively updates batch normalization (BN) statistics with each testing batch. Additionally, a self-supervised learning module optimizes learnable BN affine parameters. Information maximization and reliability-constrained pseudo-labeling improve prediction confidence and supply supervisory signals. Experimental results show our method improves classification accuracy by up to 20% mIoU, outperforming other methods. For photogrammetric (SensatUrban) to airborne (Hessigheim 3D) adaptation at the inference stage, our method achieves 59.46% mIoU and 85.97% OA without retraining or fine-turning.
Read more7/9/2024

0
Less is More: Pseudo-Label Filtering for Continual Test-Time Adaptation
Jiayao Tan, Fan Lyu, Chenggong Ni, Tingliang Feng, Fuyuan Hu, Zhang Zhang, Shaochuang Zhao, Liang Wang
Continual Test-Time Adaptation (CTTA) aims to adapt a pre-trained model to a sequence of target domains during the test phase without accessing the source data. To adapt to unlabeled data from unknown domains, existing methods rely on constructing pseudo-labels for all samples and updating the model through self-training. However, these pseudo-labels often involve noise, leading to insufficient adaptation. To improve the quality of pseudo-labels, we propose a pseudo-label selection method for CTTA, called Pseudo Labeling Filter (PLF). The key idea of PLF is to keep selecting appropriate thresholds for pseudo-labels and identify reliable ones for self-training. Specifically, we present three principles for setting thresholds during continuous domain learning, including initialization, growth and diversity. Based on these principles, we design Self-Adaptive Thresholding to filter pseudo-labels. Additionally, we introduce a Class Prior Alignment (CPA) method to encourage the model to make diverse predictions for unknown domain samples. Through extensive experiments, PLF outperforms current state-of-the-art methods, proving its effectiveness in CTTA.
Read more7/15/2024

0
Enhancing Test Time Adaptation with Few-shot Guidance
Siqi Luo, Yi Xin, Yuntao Du, Zhongwei Wan, Tao Tan, Guangtao Zhai, Xiaohong Liu
Deep neural networks often encounter significant performance drops while facing with domain shifts between training (source) and test (target) data. To address this issue, Test Time Adaptation (TTA) methods have been proposed to adapt pre-trained source model to handle out-of-distribution streaming target data. Although these methods offer some relief, they lack a reliable mechanism for domain shift correction, which can often be erratic in real-world applications. In response, we develop Few-Shot Test Time Adaptation (FS-TTA), a novel and practical setting that utilizes a few-shot support set on top of TTA. Adhering to the principle of few inputs, big gains, FS-TTA reduces blind exploration in unseen target domains. Furthermore, we propose a two-stage framework to tackle FS-TTA, including (i) fine-tuning the pre-trained source model with few-shot support set, along with using feature diversity augmentation module to avoid overfitting, (ii) implementing test time adaptation based on prototype memory bank guidance to produce high quality pseudo-label for model adaptation. Through extensive experiments on three cross-domain classification benchmarks, we demonstrate the superior performance and reliability of our FS-TTA and framework.
Read more9/4/2024