Less is More: Pseudo-Label Filtering for Continual Test-Time Adaptation

0

Sign in to get full access
Overview
- This paper introduces a method called "Pseudo-Label Filtering for Continual Test-Time Adaptation" that aims to improve the performance of machine learning models on new, unseen data.
- The key idea is to selectively use the model's own predictions (pseudo-labels) to update the model during testing, rather than relying on all predictions.
- This "less is more" approach helps the model adapt to new data without catastrophically forgetting previous knowledge.
Plain English Explanation
Machine learning models are often trained on a fixed dataset, but in the real world, they need to handle new and different data over time. This paper proposes a way to help models adapt to new data without completely forgetting what they've learned before.
The core of the idea is to be selective about how the model updates itself during testing on new data. Instead of using all of the model's predictions, the method filters the predictions to only use the most confident ones (the "pseudo-labels"). This allows the model to learn from the new data without overwriting important knowledge from the original training.
The authors show this "less is more" approach leads to better performance on new, unseen data compared to simply fine-tuning the model on all the new predictions. It's a way to help machine learning models continually adapt to the real world without completely forgetting what they've learned.
Technical Explanation
The key contribution of this paper is a novel method for continual test-time adaptation called "Pseudo-Label Filtering." The core idea is to selectively update the model parameters during testing using only the model's most confident predictions (pseudo-labels), rather than all predictions.
Specifically, the authors propose a two-stage process:
- Run the model on new test data and obtain the model's predictions (softmax outputs).
- Filter these predictions to keep only the most confident ones (above a certain threshold) as pseudo-labels.
- Use these filtered pseudo-labels to update the model parameters via gradient descent, similar to fine-tuning.
This "less is more" approach is motivated by the observation that using all predictions during fine-tuning can lead to catastrophic forgetting of the model's original training. By being more selective with the pseudo-labels, the method allows the model to adapt to new data while preserving its core knowledge.
The authors evaluate their approach on several standard benchmark datasets and show consistent improvements over baselines like fine-tuning or full adaptation. They also analyze the impact of key hyperparameters like the pseudo-label threshold.
Critical Analysis
One key limitation of this work is that the pseudo-label filtering approach relies on setting a good threshold for confidence. The authors show the performance is sensitive to this hyperparameter, and selecting the optimal value may require additional validation data or cross-validation.
Additionally, the method assumes the model's softmax outputs are well-calibrated and reflect its true confidence. In practice, modern deep learning models can often be overconfident, so this assumption may not always hold. Further research could explore ways to better estimate model uncertainty for the pseudo-label selection.
Finally, the experiments in this paper are focused on image classification tasks. It remains to be seen how well the pseudo-label filtering approach would generalize to other domains, such as natural language processing or reinforcement learning, where the notion of confidence may differ.
Conclusion
This paper introduces a novel approach called "Pseudo-Label Filtering for Continual Test-Time Adaptation" that aims to help machine learning models adapt to new data without catastrophically forgetting their original training. By selectively using the model's most confident predictions to update the parameters, the method allows for effective adaptation while preserving core knowledge.
The results demonstrate the potential of this "less is more" approach, showing consistent performance improvements over standard fine-tuning baselines. While the method has some limitations around hyperparameter tuning and model calibration, it represents an important step towards building more robust and adaptable AI systems that can continually learn and evolve in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Less is More: Pseudo-Label Filtering for Continual Test-Time Adaptation
Jiayao Tan, Fan Lyu, Chenggong Ni, Tingliang Feng, Fuyuan Hu, Zhang Zhang, Shaochuang Zhao, Liang Wang
Continual Test-Time Adaptation (CTTA) aims to adapt a pre-trained model to a sequence of target domains during the test phase without accessing the source data. To adapt to unlabeled data from unknown domains, existing methods rely on constructing pseudo-labels for all samples and updating the model through self-training. However, these pseudo-labels often involve noise, leading to insufficient adaptation. To improve the quality of pseudo-labels, we propose a pseudo-label selection method for CTTA, called Pseudo Labeling Filter (PLF). The key idea of PLF is to keep selecting appropriate thresholds for pseudo-labels and identify reliable ones for self-training. Specifically, we present three principles for setting thresholds during continuous domain learning, including initialization, growth and diversity. Based on these principles, we design Self-Adaptive Thresholding to filter pseudo-labels. Additionally, we introduce a Class Prior Alignment (CPA) method to encourage the model to make diverse predictions for unknown domain samples. Through extensive experiments, PLF outperforms current state-of-the-art methods, proving its effectiveness in CTTA.
Read more7/15/2024
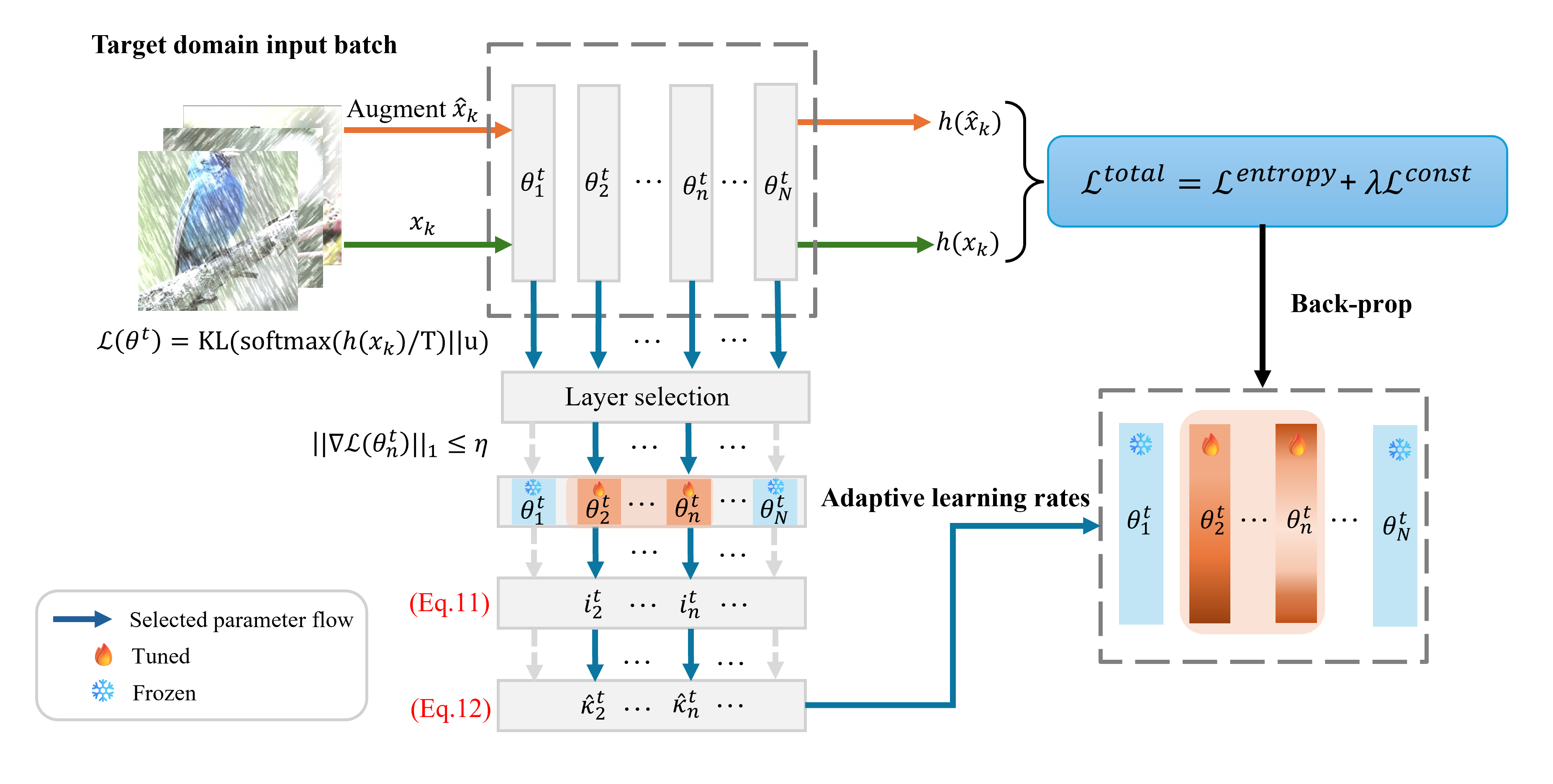
0
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Sarthak Kumar Maharana, Baoming Zhang, Yunhui Guo
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Using unlabeled test data, continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains. A highly effective CTTA method involves applying layer-wise adaptive learning rates for selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. This work aims to overcome these limitations by identifying layers for adaptation via quantifying model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity to approximate the domain shift and adjust their learning rates accordingly. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C, demonstrating the superior efficacy of our method compared to prior approaches.
Read more8/27/2024

0
Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation
Yeonguk Yu, Sungho Shin, Seunghyeok Back, Minhwan Ko, Sangjun Noh, Kyoobin Lee
Test-time adaptation (TTA) aims to adapt a pre-trained model to a new test domain without access to source data after deployment. Existing approaches typically rely on self-training with pseudo-labels since ground-truth cannot be obtained from test data. Although the quality of pseudo labels is important for stable and accurate long-term adaptation, it has not been previously addressed. In this work, we propose DPLOT, a simple yet effective TTA framework that consists of two components: (1) domain-specific block selection and (2) pseudo-label generation using paired-view images. Specifically, we select blocks that involve domain-specific feature extraction and train these blocks by entropy minimization. After blocks are adjusted for current test domain, we generate pseudo-labels by averaging given test images and corresponding flipped counterparts. By simply using flip augmentation, we prevent a decrease in the quality of the pseudo-labels, which can be caused by the domain gap resulting from strong augmentation. Our experimental results demonstrate that DPLOT outperforms previous TTA methods in CIFAR10-C, CIFAR100-C, and ImageNet-C benchmarks, reducing error by up to 5.4%, 9.1%, and 2.9%, respectively. Also, we provide an extensive analysis to demonstrate effectiveness of our framework. Code is available at https://github.com/gist-ailab/domain-specific-block-selection-and-paired-view-pseudo-labeling-for-online-TTA.
Read more5/8/2024
➖
0
Controllable Continual Test-Time Adaptation
Ziqi Shi, Fan Lyu, Ye Liu, Fanhua Shang, Fuyuan Hu, Wei Feng, Zhang Zhang, Liang Wang
Continual Test-Time Adaptation (CTTA) is an emerging and challenging task where a model trained in a source domain must adapt to continuously changing conditions during testing, without access to the original source data. CTTA is prone to error accumulation due to uncontrollable domain shifts, leading to blurred decision boundaries between categories. Existing CTTA methods primarily focus on suppressing domain shifts, which proves inadequate during the unsupervised test phase. In contrast, we introduce a novel approach that guides rather than suppresses these shifts. Specifically, we propose $textbf{C}$ontrollable $textbf{Co}$ntinual $textbf{T}$est-$textbf{T}$ime $textbf{A}$daptation (C-CoTTA), which explicitly prevents any single category from encroaching on others, thereby mitigating the mutual influence between categories caused by uncontrollable shifts. Moreover, our method reduces the sensitivity of model to domain transformations, thereby minimizing the magnitude of category shifts. Extensive quantitative experiments demonstrate the effectiveness of our method, while qualitative analyses, such as t-SNE plots, confirm the theoretical validity of our approach.
Read more5/29/2024