Do More With What You Have: Transferring Depth-Scale from Labeled to Unlabeled Domains
2303.07662
0
0
🧠
Abstract
Transferring the absolute depth prediction capabilities of an estimator to a new domain is a task with significant real-world applications. This task is specifically challenging when images from the new domain are collected without ground-truth depth measurements, and possibly with sensors of different intrinsics. To overcome such limitations, a recent zero-shot solution was trained on an extensive training dataset and encoded the various camera intrinsics. Other solutions generated synthetic data with depth labels that matched the intrinsics of the new target data to enable depth-scale transfer between the domains. In this work we present an alternative solution that can utilize any existing synthetic or real dataset, that has a small number of images annotated with ground truth depth labels. Specifically, we show that self-supervised depth estimators result in up-to-scale predictions that are linearly correlated to their absolute depth values across the domain, a property that we model in this work using a single scalar. In addition, aligning the field-of-view of two datasets prior to training, results in a common linear relationship for both domains. We use this observed property to transfer the depth-scale from source datasets that have absolute depth labels to new target datasets that lack these measurements, enabling absolute depth predictions in the target domain. The suggested method was successfully demonstrated on the KITTI, DDAD and nuScenes datasets, while using other existing real or synthetic source datasets, that have a different field-of-view, other image style or structural content, achieving comparable or better accuracy than other existing methods that do not use target ground-truth depths.
Create account to get full access
Overview
- Transferring depth prediction capabilities to new domains is an important task with real-world applications
- Challenging when new domain images lack ground-truth depth measurements and have different camera intrinsics
- Existing solutions include training on extensive datasets that encode camera intrinsics, and generating synthetic data to match target intrinsics
- This work presents an alternative approach that can utilize any existing synthetic or real dataset with a small number of depth-annotated images
Plain English Explanation
This research paper tackles the challenge of depth estimation in new environments, where the camera properties may be different from the ones used to train the depth estimation model. This is a common problem in real-world applications, as depth sensors may not always be available, and the camera settings can vary between different setups.
The key insight of this paper is that self-supervised depth estimators produce predictions that are linearly correlated with the actual depth values, even across different domains. By aligning the field of view between the source and target datasets, the researchers were able to leverage this linear relationship to transfer the depth scale from the source dataset to the target dataset, enabling accurate absolute depth predictions without requiring any ground-truth depth labels in the target domain.
This approach is demonstrated to be effective on several popular datasets, such as KITTI, DDAD, and nuScenes, and outperforms other methods that do not use target ground-truth depths. The ability to leverage existing datasets, even with a small number of depth-annotated images, is a significant advantage of this self-training via metric learning approach.
Technical Explanation
The proposed method leverages the observation that self-supervised depth estimators produce predictions that are linearly correlated with the actual depth values, even across different domains. By aligning the field of view between the source and target datasets, the researchers were able to model this linear relationship using a single scalar factor, which allows transferring the depth scale from the source dataset to the target dataset.
The key steps of the proposed approach are:
- Aligning field of view: The researchers align the field of view of the source and target datasets to ensure a common linear relationship between the self-supervised depth predictions and the actual depth values.
- Estimating the depth scale factor: The researchers estimate a single scalar factor that linearly relates the self-supervised depth predictions to the actual depth values in the source dataset.
- Transferring the depth scale: The estimated depth scale factor is then used to transfer the depth scale from the source dataset to the target dataset, enabling absolute depth predictions without requiring any ground-truth depth labels in the target domain.
The researchers demonstrate the effectiveness of their approach on the KITTI, DDAD, and nuScenes datasets, using a variety of real and synthetic source datasets. Their method achieves comparable or better accuracy than other existing methods that do not use target ground-truth depths.
Critical Analysis
The researchers present a compelling approach to addressing the challenge of domain adaptation in depth estimation, which is a crucial step towards enabling the practical deployment of depth prediction models in real-world applications.
One potential limitation of the method is that it relies on the assumption that self-supervised depth estimators produce predictions that are linearly correlated with the actual depth values. While the researchers demonstrate the validity of this assumption across multiple datasets, it may not hold true in all scenarios, particularly in cases where the domain shift is more substantial.
Additionally, the method requires at least a small number of depth-annotated images in the target domain, which may not always be available. It would be interesting to see if the researchers can further extend their approach to handle scenarios where no target ground-truth depth data is available at all.
Overall, the researchers have presented a compelling and practical solution to a challenging problem, and their work could have significant implications for the field of depth estimation and its real-world applications.
Conclusion
This research paper presents an innovative approach to transferring depth prediction capabilities from one domain to another, even when the target domain lacks ground-truth depth measurements and has different camera intrinsics.
The key insight is that self-supervised depth estimators produce predictions that are linearly correlated with actual depth values, and this linear relationship can be leveraged to transfer the depth scale from a source dataset to a target dataset.
This approach enables accurate absolute depth predictions in the target domain without requiring any ground-truth depth labels, making it a significant advancement in the field of depth estimation and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
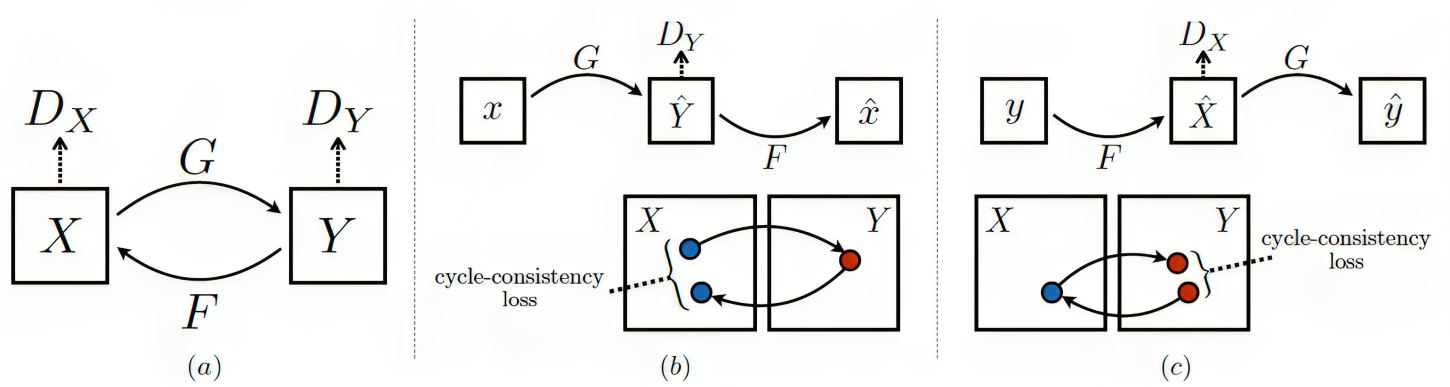
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
Seungyeop Lee, Knut Peterson, Solmaz Arezoomandan, Bill Cai, Peihan Li, Lifeng Zhou, David Han
0
0
A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
5/3/2024
🛸
Test-Time Adaptation for Depth Completion
Hyoungseob Park, Anjali Gupta, Alex Wong
0
0
It is common to observe performance degradation when transferring models trained on some (source) datasets to target testing data due to a domain gap between them. Existing methods for bridging this gap, such as domain adaptation (DA), may require the source data on which the model was trained (often not available), while others, i.e., source-free DA, require many passes through the testing data. We propose an online test-time adaptation method for depth completion, the task of inferring a dense depth map from a single image and associated sparse depth map, that closes the performance gap in a single pass. We first present a study on how the domain shift in each data modality affects model performance. Based on our observations that the sparse depth modality exhibits a much smaller covariate shift than the image, we design an embedding module trained in the source domain that preserves a mapping from features encoding only sparse depth to those encoding image and sparse depth. During test time, sparse depth features are projected using this map as a proxy for source domain features and are used as guidance to train a set of auxiliary parameters (i.e., adaptation layer) to align image and sparse depth features from the target test domain to that of the source domain. We evaluate our method on indoor and outdoor scenarios and show that it improves over baselines by an average of 21.1%.
5/28/2024

Consistency Regularisation for Unsupervised Domain Adaptation in Monocular Depth Estimation
Amir El-Ghoussani, Julia Hornauer, Gustavo Carneiro, Vasileios Belagiannis
0
0
In monocular depth estimation, unsupervised domain adaptation has recently been explored to relax the dependence on large annotated image-based depth datasets. However, this comes at the cost of training multiple models or requiring complex training protocols. We formulate unsupervised domain adaptation for monocular depth estimation as a consistency-based semi-supervised learning problem by assuming access only to the source domain ground truth labels. To this end, we introduce a pairwise loss function that regularises predictions on the source domain while enforcing perturbation consistency across multiple augmented views of the unlabelled target samples. Importantly, our approach is simple and effective, requiring only training of a single model in contrast to the prior work. In our experiments, we rely on the standard depth estimation benchmarks KITTI and NYUv2 to demonstrate state-of-the-art results compared to related approaches. Furthermore, we analyse the simplicity and effectiveness of our approach in a series of ablation studies. The code is available at url{https://github.com/AmirMaEl/SemiSupMDE}.
5/29/2024
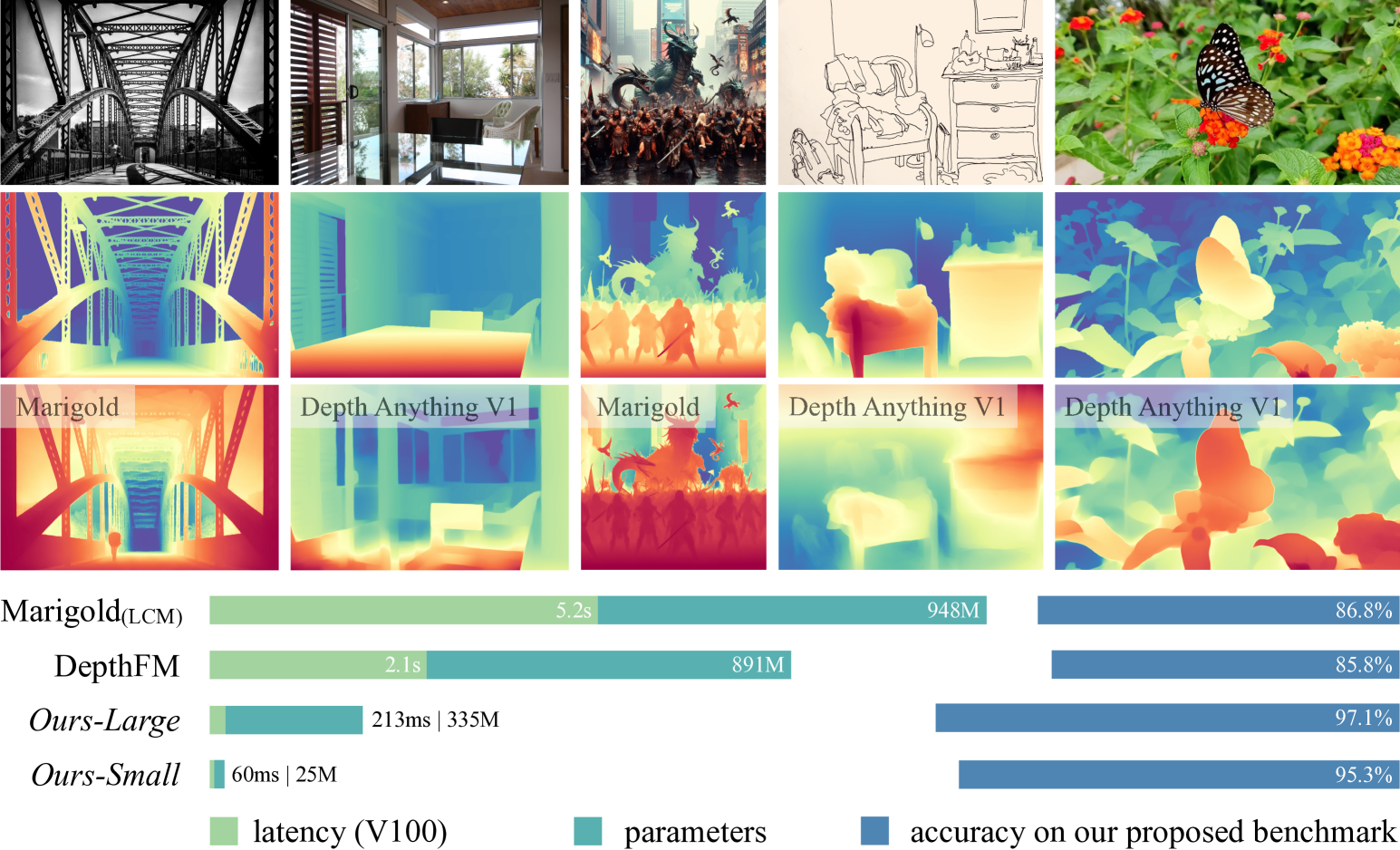
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
0
0
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
6/14/2024