Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection

0
🗣️
Sign in to get full access
Overview
- This paper examines the ability of Large Language Models (LLMs) to detect and respond to implicit hate speech.
- Implicit hate speech uses indirect language to convey hateful intentions, which is a significant challenge.
- The paper evaluates LLMs' performance on two tasks: Classification Task and Calibration Task.
- The evaluation considers various prompt patterns and mainstream uncertainty estimation methods.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text. As these models become more powerful, there are growing concerns about their fairness and trustworthiness. One issue is the use of implicit hate speech, where people use indirect language to express hateful intentions.
This paper investigates how well LLMs can detect and respond to implicit hate speech. The researchers looked at two specific tasks:
- Classification Task: Can the LLMs correctly identify when a statement contains implicit hate speech?
- Calibration Task: How confident are the LLMs in their decisions, and does this confidence align with their accuracy?
To test this, the researchers used different ways of phrasing prompts and measuring the models' uncertainty. They found two key issues:
- Excessive Sensitivity: The LLMs were overly sensitive to certain groups or topics, leading them to wrongly classify benign statements as hate speech.
- Overconfidence: The LLMs' confidence scores were heavily skewed towards a narrow range, regardless of the complexity of the input. This meant their level of confidence didn't always match their actual accuracy.
These findings reveal new limitations in how LLMs handle sensitive topics like hate speech. It highlights the need to carefully monitor both the models' sensitivity and their confidence to ensure they don't veer towards extremes and make unfair or unreliable decisions.
Technical Explanation
The researchers designed two experiments to evaluate LLMs' capabilities in detecting and responding to implicit hate speech:
- Classification Task: The models were asked to classify whether a given statement contained implicit hate speech or not. The researchers used various prompt patterns to understand how the models would respond.
- Calibration Task: The researchers measured the models' confidence in their classifications and examined how well this confidence aligned with their actual accuracy. They used several mainstream uncertainty estimation methods for this.
The key findings were:
- Excessive Sensitivity: The LLMs displayed excessive sensitivity towards certain groups or topics, leading them to misclassify benign statements as hate speech. This suggests the models may struggle to distinguish subtle differences and could have fairness issues.
- Overconfidence: The models' confidence scores were heavily concentrated within a fixed range, regardless of the complexity of the input. This meant their level of confidence did not always match their classification accuracy, a phenomenon known as miscalibration.
These discoveries highlight new limitations in how LLMs handle sensitive content like implicit hate speech. The models may be overly sensitive in certain areas and overly confident in their responses, which could lead to unreliable and unfair decisions. The researchers emphasize the need to carefully monitor both sensitivity and confidence when developing LLMs to ensure they do not veer towards these extremes.
Critical Analysis
The paper provides valuable insights into the challenges of using LLMs for sensitive tasks like hate speech detection. By examining both the classification accuracy and confidence calibration of the models, the researchers uncover nuanced issues that have important implications.
One key limitation is the specific prompts and datasets used in the experiments. The researchers acknowledge that the patterns of implicit hate speech can vary greatly, and the models' performance may differ with other types of prompts or data. Further research is needed to understand the generalizability of these findings.
Additionally, the paper does not delve into the potential causes of the observed issues. It would be helpful to understand the underlying architectural or training factors that contribute to the models' excessive sensitivity and overconfidence. This could inform more targeted solutions to address these problems.
Another area for further exploration is the impact of these limitations in real-world applications. The paper focuses on the technical performance of the models, but it would be valuable to understand how these issues might manifest in practical scenarios and the potential harms they could cause.
Overall, this paper serves as an important wake-up call for the AI research community. It highlights the need to scrutinize the fairness and reliability of LLMs, especially when deploying them for high-stakes tasks. Continued critical examination and a commitment to responsible development will be crucial as these powerful models become more widespread.
Conclusion
This paper sheds light on significant limitations in how large language models (LLMs) handle the detection and response to implicit hate speech. The researchers found that LLMs can exhibit two problematic extremes: excessive sensitivity, leading to the misclassification of benign statements as hate speech, and overconfidence, where the models' confidence scores do not align with their actual accuracy.
These discoveries underscore the need for caution and careful monitoring when optimizing LLMs for sensitive applications. Ensuring the models maintain appropriate sensitivity and well-calibrated confidence is crucial to upholding fairness and trustworthiness. As these powerful AI systems become more prevalent, continued critical analysis and responsible development will be essential to mitigate potential harms and unlock the full benefits of this transformative technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection
Min Zhang, Jianfeng He, Taoran Ji, Chang-Tien Lu
The fairness and trustworthiness of Large Language Models (LLMs) are receiving increasing attention. Implicit hate speech, which employs indirect language to convey hateful intentions, occupies a significant portion of practice. However, the extent to which LLMs effectively address this issue remains insufficiently examined. This paper delves into the capability of LLMs to detect implicit hate speech (Classification Task) and express confidence in their responses (Calibration Task). Our evaluation meticulously considers various prompt patterns and mainstream uncertainty estimation methods. Our findings highlight that LLMs exhibit two extremes: (1) LLMs display excessive sensitivity towards groups or topics that may cause fairness issues, resulting in misclassifying benign statements as hate speech. (2) LLMs' confidence scores for each method excessively concentrate on a fixed range, remaining unchanged regardless of the dataset's complexity. Consequently, the calibration performance is heavily reliant on primary classification accuracy. These discoveries unveil new limitations of LLMs, underscoring the need for caution when optimizing models to ensure they do not veer towards extremes. This serves as a reminder to carefully consider sensitivity and confidence in the pursuit of model fairness.
Read more7/24/2024
🗣️
0
HateTinyLLM : Hate Speech Detection Using Tiny Large Language Models
Tanmay Sen, Ansuman Das, Mrinmay Sen
Hate speech encompasses verbal, written, or behavioral communication that targets derogatory or discriminatory language against individuals or groups based on sensitive characteristics. Automated hate speech detection plays a crucial role in curbing its propagation, especially across social media platforms. Various methods, including recent advancements in deep learning, have been devised to address this challenge. In this study, we introduce HateTinyLLM, a novel framework based on fine-tuned decoder-only tiny large language models (tinyLLMs) for efficient hate speech detection. Our experimental findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model by a significant margin. We explored various tiny LLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and fine-tuned them using LoRA and adapter methods. Our observations indicate that all LoRA-based fine-tuned models achieved over 80% accuracy.
Read more5/6/2024
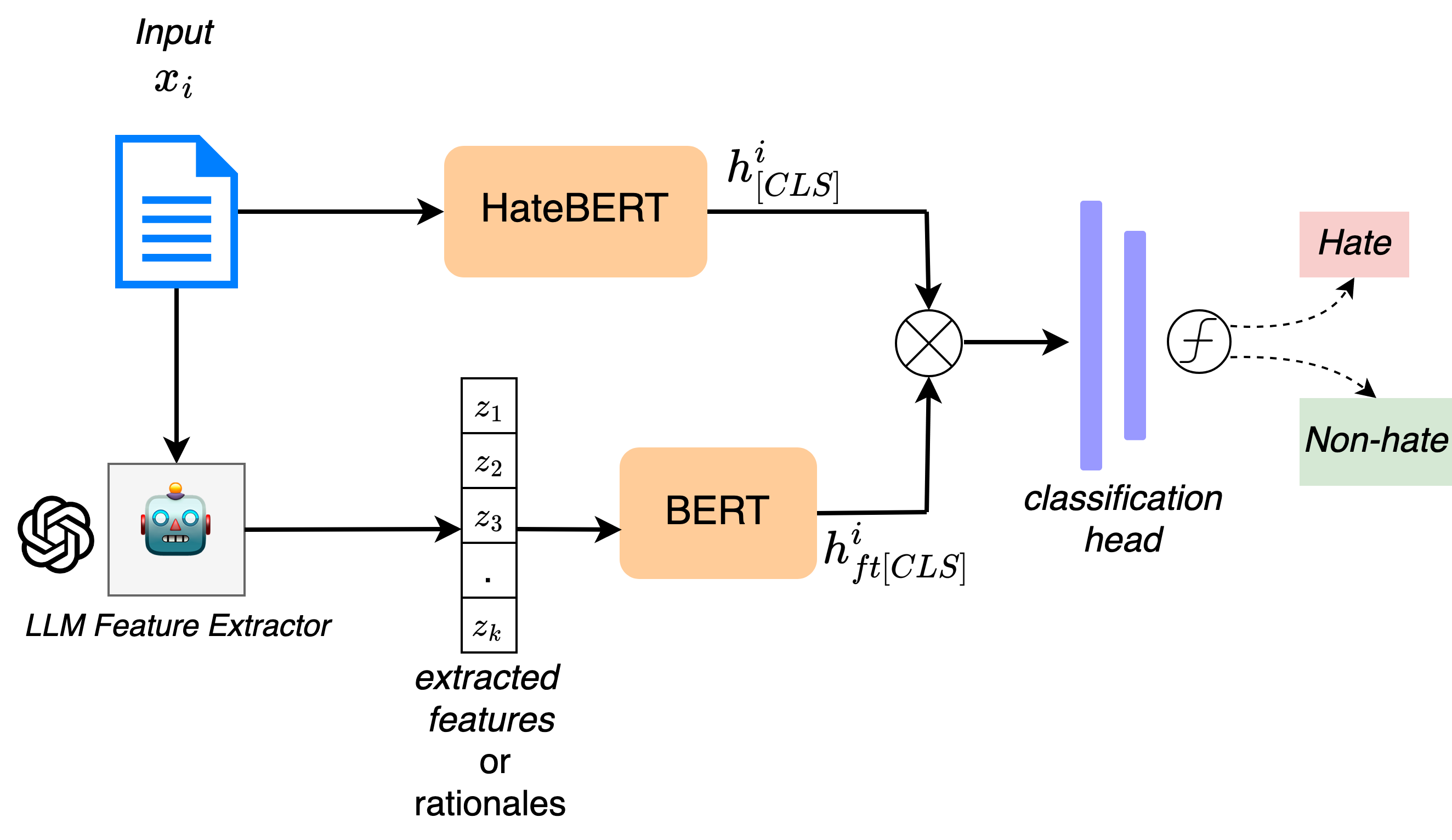
0
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Ayushi Nirmal, Amrita Bhattacharjee, Paras Sheth, Huan Liu
Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of English language social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability. All code and data will be made available at https://github.com/AmritaBh/shield.
Read more5/9/2024

0
Large Language Models for Automatic Detection of Sensitive Topics
Ruoyu Wen, Stephanie Elena Crowe, Kunal Gupta, Xinyue Li, Mark Billinghurst, Simon Hoermann, Dwain Allan, Alaeddin Nassani, Thammathip Piumsomboon
Sensitive information detection is crucial in content moderation to maintain safe online communities. Assisting in this traditionally manual process could relieve human moderators from overwhelming and tedious tasks, allowing them to focus solely on flagged content that may pose potential risks. Rapidly advancing large language models (LLMs) are known for their capability to understand and process natural language and so present a potential solution to support this process. This study explores the capabilities of five LLMs for detecting sensitive messages in the mental well-being domain within two online datasets and assesses their performance in terms of accuracy, precision, recall, F1 scores, and consistency. Our findings indicate that LLMs have the potential to be integrated into the moderation workflow as a convenient and precise detection tool. The best-performing model, GPT-4o, achieved an average accuracy of 99.5% and an F1-score of 0.99. We discuss the advantages and potential challenges of using LLMs in the moderation workflow and suggest that future research should address the ethical considerations of utilising this technology.
Read more9/4/2024