HateTinyLLM : Hate Speech Detection Using Tiny Large Language Models

0
🗣️
Sign in to get full access
Overview
- This research paper introduces HateTinyLLM, a novel framework for efficient hate speech detection using fine-tuned tiny large language models (tinyLLMs).
- The paper explores various tinyLLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and evaluates their performance on hate speech detection tasks.
- The findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model, with all LoRA-based fine-tuned models achieving over 80% accuracy.
Plain English Explanation
Hate speech is when someone uses hurtful or discriminatory language to target individuals or groups based on their personal characteristics, like race, religion, or gender. This is a serious problem, especially on social media platforms where it can spread quickly.
To help address this issue, researchers have developed automated systems to detect hate speech. One new approach, called HateTinyLLM, uses small but powerful language models that have been specially trained to recognize and flag hate speech. The researchers tested out different small language models, including ones from companies like Microsoft and Meta, and found that these fine-tuned models were able to identify hate speech with over 80% accuracy.
This is an important breakthrough because these small, efficient models can be deployed more easily and cost-effectively on social media platforms to help curb the spread of hate speech. By catching hateful content early, platforms can take action to remove it and prevent it from reaching a wider audience.
Technical Explanation
The paper introduces HateTinyLLM, a framework that leverages fine-tuned decoder-only tiny large language models (tinyLLMs) for efficient hate speech detection. The researchers explored various tinyLLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and fine-tuned them using LoRA and adapter methods.
The experimental findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model by a significant margin. The researchers observed that all LoRA-based fine-tuned models achieved over 80% accuracy on hate speech detection tasks.
The use of tinyLLMs is advantageous for this application as they are more efficient and cost-effective to deploy, which is crucial for real-world implementation on social media platforms. The fine-tuning process helps these small models specialize in the task of hate speech detection, making them a powerful and practical solution.
Critical Analysis
The paper provides a comprehensive evaluation of various tinyLLM architectures and fine-tuning strategies for hate speech detection. However, the researchers acknowledge that their work is limited to a specific dataset and language (English), and further research is needed to assess the performance on more diverse datasets and languages.
Additionally, while the high accuracy achieved by the fine-tuned HateTinyLLM is promising, the paper does not address potential issues around false positives or the interpretability of the model's decisions. These are important considerations for real-world deployment, as overly aggressive hate speech detection could lead to the silencing of legitimate speech.
To further strengthen the research, it would be valuable to explore the mitigation of linguistic discrimination in large language models and investigate the potential of targeted sentiment analysis to better understand the nuances of hate speech detection.
Conclusion
The introduction of HateTinyLLM represents a significant advancement in the field of automated hate speech detection. The ability to leverage efficient tinyLLMs for this task holds great promise for real-world implementation, enabling social media platforms to more effectively curb the spread of hateful and discriminatory content. However, further research is needed to address potential limitations and ensure the responsible deployment of such systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
HateTinyLLM : Hate Speech Detection Using Tiny Large Language Models
Tanmay Sen, Ansuman Das, Mrinmay Sen
Hate speech encompasses verbal, written, or behavioral communication that targets derogatory or discriminatory language against individuals or groups based on sensitive characteristics. Automated hate speech detection plays a crucial role in curbing its propagation, especially across social media platforms. Various methods, including recent advancements in deep learning, have been devised to address this challenge. In this study, we introduce HateTinyLLM, a novel framework based on fine-tuned decoder-only tiny large language models (tinyLLMs) for efficient hate speech detection. Our experimental findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model by a significant margin. We explored various tiny LLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and fine-tuned them using LoRA and adapter methods. Our observations indicate that all LoRA-based fine-tuned models achieved over 80% accuracy.
Read more5/6/2024
0
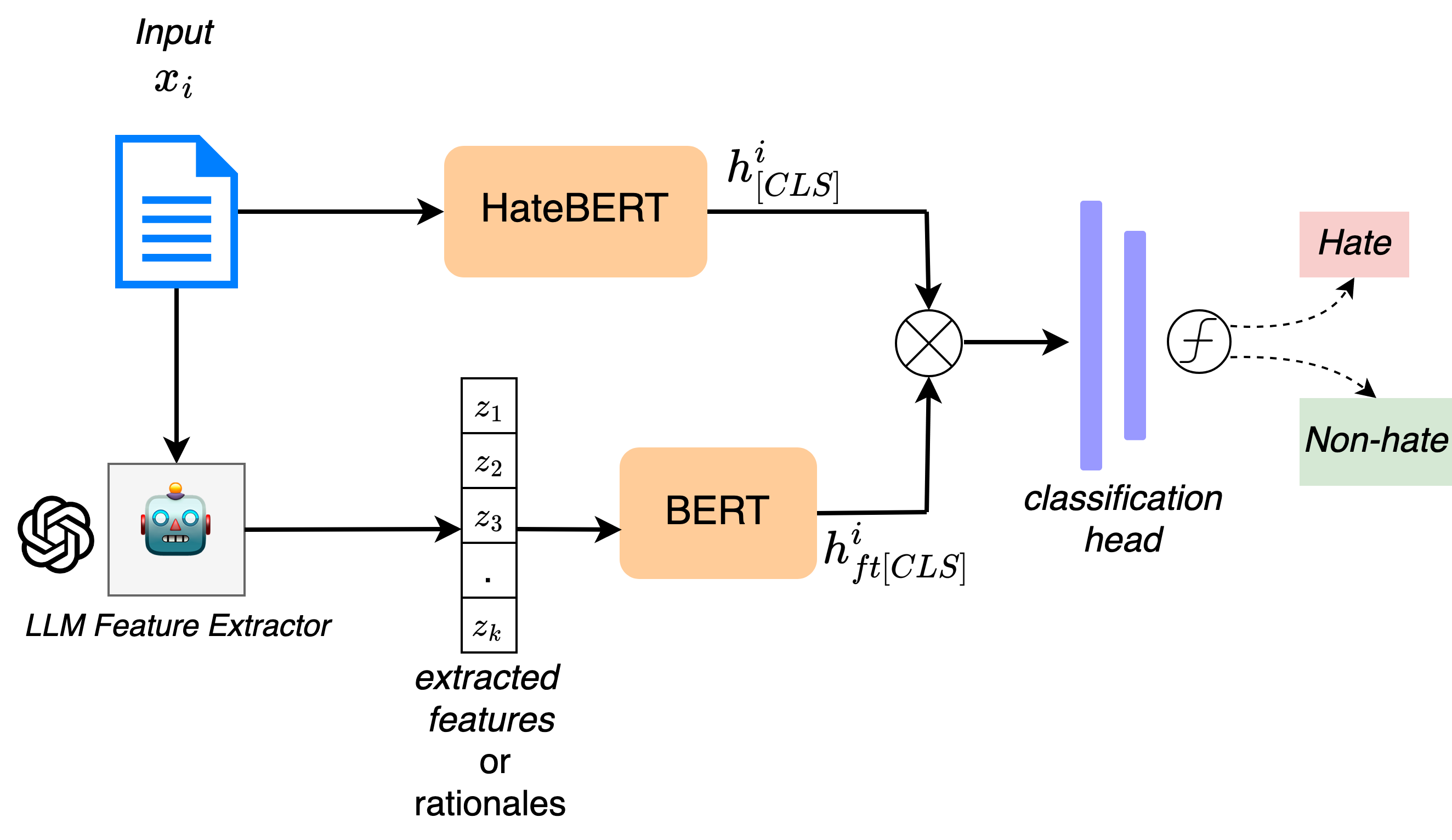
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Ayushi Nirmal, Amrita Bhattacharjee, Paras Sheth, Huan Liu
Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of English language social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability. All code and data will be made available at https://github.com/AmritaBh/shield.
Read more5/9/2024

0
Detecting Anti-Semitic Hate Speech using Transformer-based Large Language Models
Dengyi Liu, Minghao Wang, Andrew G. Catlin
Academic researchers and social media entities grappling with the identification of hate speech face significant challenges, primarily due to the vast scale of data and the dynamic nature of hate speech. Given the ethical and practical limitations of large predictive models like ChatGPT in directly addressing such sensitive issues, our research has explored alternative advanced transformer-based and generative AI technologies since 2019. Specifically, we developed a new data labeling technique and established a proof of concept targeting anti-Semitic hate speech, utilizing a variety of transformer models such as BERT (arXiv:1810.04805), DistillBERT (arXiv:1910.01108), RoBERTa (arXiv:1907.11692), and LLaMA-2 (arXiv:2307.09288), complemented by the LoRA fine-tuning approach (arXiv:2106.09685). This paper delineates and evaluates the comparative efficacy of these cutting-edge methods in tackling the intricacies of hate speech detection, highlighting the need for responsible and carefully managed AI applications within sensitive contexts.
Read more5/8/2024
🗣️
0
Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection
Min Zhang, Jianfeng He, Taoran Ji, Chang-Tien Lu
The fairness and trustworthiness of Large Language Models (LLMs) are receiving increasing attention. Implicit hate speech, which employs indirect language to convey hateful intentions, occupies a significant portion of practice. However, the extent to which LLMs effectively address this issue remains insufficiently examined. This paper delves into the capability of LLMs to detect implicit hate speech (Classification Task) and express confidence in their responses (Calibration Task). Our evaluation meticulously considers various prompt patterns and mainstream uncertainty estimation methods. Our findings highlight that LLMs exhibit two extremes: (1) LLMs display excessive sensitivity towards groups or topics that may cause fairness issues, resulting in misclassifying benign statements as hate speech. (2) LLMs' confidence scores for each method excessively concentrate on a fixed range, remaining unchanged regardless of the dataset's complexity. Consequently, the calibration performance is heavily reliant on primary classification accuracy. These discoveries unveil new limitations of LLMs, underscoring the need for caution when optimizing models to ensure they do not veer towards extremes. This serves as a reminder to carefully consider sensitivity and confidence in the pursuit of model fairness.
Read more7/24/2024