Reevaluating Bias Detection in Language Models: The Role of Implicit Norm
2404.03471
0
0
Abstract
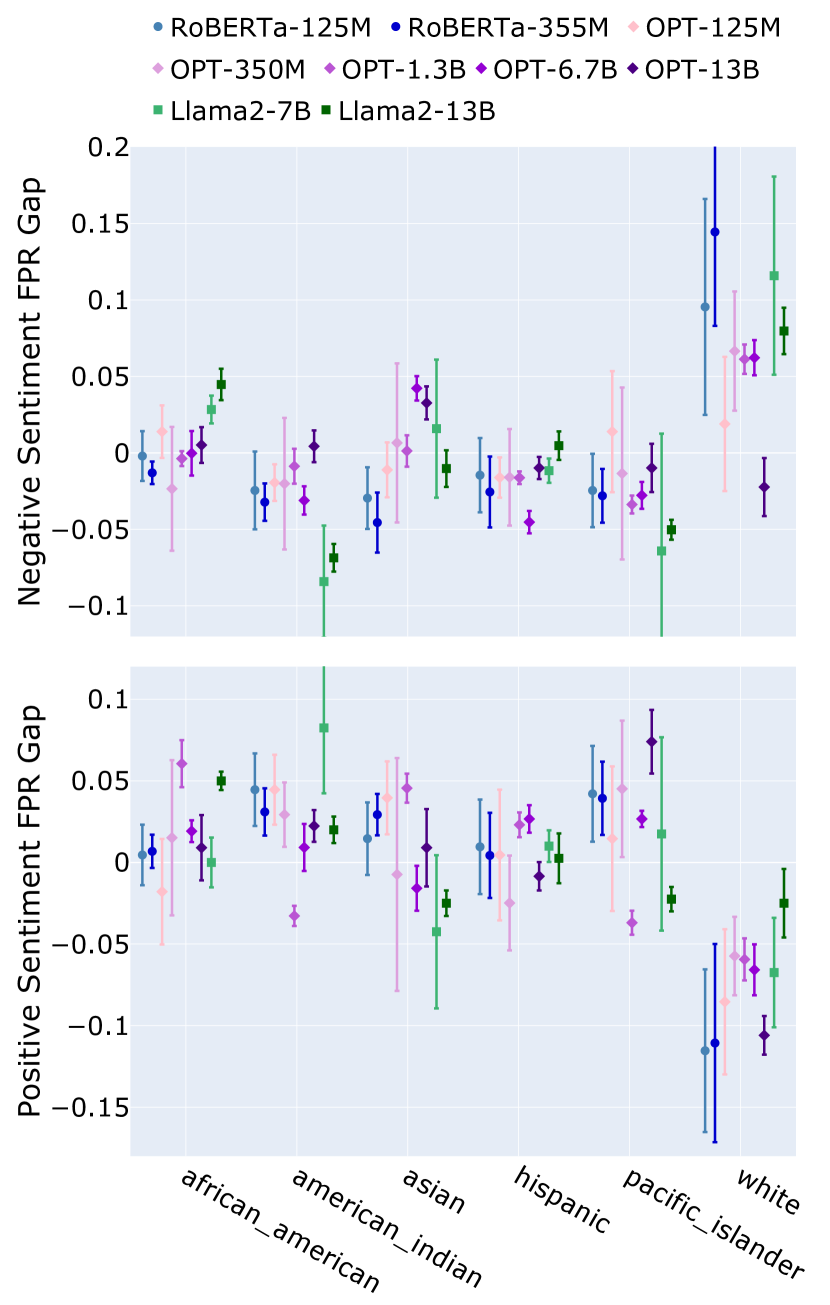
Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the role of implicit norms in bias detection within language models.
- It reevaluates common approaches to identifying biases in language models and highlights the importance of understanding the implicit assumptions and social norms underlying these models.
- The research explores how these implicit norms can influence the perceived biases in language models and the need for more nuanced evaluation methods.
Plain English Explanation
Language models, which are AI systems trained on vast amounts of text data, have become increasingly powerful and widely used. However, there is growing concern about the potential biases these models may encode, reflecting the biases present in the data they were trained on.
The researchers in this paper argue that the common approaches to detecting biases in language models may be oversimplified. They suggest that the perceived biases in these models are often influenced by implicit social norms and assumptions that are not always explicitly captured in the training data or the evaluation methods.
For example, a language model may use certain words or phrases in a way that aligns with societal norms, even if those norms are problematic or discriminatory. Traditional bias detection methods may flag these as biases, without considering the underlying social context and expectations that shape the model's behavior.
The paper proposes that a more nuanced understanding of these implicit norms is necessary to properly evaluate and address biases in language models. By recognizing the role of these implicit factors, researchers and developers can design more robust and comprehensive approaches to bias detection and mitigation.
Technical Explanation
The paper begins by highlighting the limitations of existing methods for detecting biases in language models. Traditional approaches often focus on measuring biases through predetermined metrics, such as word association tests or text generation experiments. However, the authors argue that these methods may overlook the more subtle and complex ways in which biases can manifest in language models.
To address this, the researchers propose a framework that considers the role of implicit norms in shaping the behavior of language models. They argue that these models do not simply reflect the biases present in the training data, but also incorporate the implicit social expectations and assumptions that are embedded in the language used in that data.
The paper presents a series of experiments that explore how different types of implicit norms can influence the perceived biases in language models. For example, the researchers investigate how gender norms and cultural stereotypes can affect the way language models generate text or respond to prompts.
By incorporating a more nuanced understanding of these implicit factors, the paper suggests that researchers and developers can develop more robust and comprehensive approaches to bias detection and mitigation in language models. This includes considering the social and cultural contexts that shape the use of language, as well as the potential for language models to reflect and perpetuate harmful societal biases.
Critical Analysis
The paper makes a compelling case for the need to reevaluate bias detection in language models, highlighting the role of implicit norms as a key factor that is often overlooked. By acknowledging the complex interplay between language, societal expectations, and the biases encoded in language models, the researchers offer a more nuanced perspective on the challenge of addressing these issues.
However, the paper also acknowledges some limitations in its approach. For example, the experiments focused on a relatively narrow set of implicit norms, and it's possible that other types of norms or cultural influences may also play a significant role in shaping the behavior of language models.
Additionally, while the paper emphasizes the need for more comprehensive evaluation methods, it does not provide a clear roadmap for how to develop and implement these methods in practice. Further research and experimentation will be necessary to translate the insights from this paper into actionable strategies for language model developers and users.
Conclusion
This paper challenges the traditional approaches to bias detection in language models and underscores the importance of considering the implicit norms and social expectations that shape the behavior of these AI systems. By recognizing the complex interplay between language, societal norms, and the biases encoded in language models, the researchers offer a more nuanced perspective on a critical issue in the field of natural language processing.
As language models become increasingly ubiquitous and influential, it is crucial that researchers, developers, and users understand the potential biases and limitations of these systems. The insights provided in this paper can serve as a foundation for developing more robust and comprehensive approaches to bias detection and mitigation, ultimately contributing to the responsible development and deployment of language models that better align with societal values and promote more inclusive and equitable outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Yuval Reif, Roy Schwartz
0
0
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
5/7/2024
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024
💬
Large Language Models Portray Socially Subordinate Groups as More Homogeneous, Consistent with a Bias Observed in Humans
Messi H. J. Lee, Jacob M. Montgomery, Calvin K. Lai
0
0
Large language models (LLMs) are becoming pervasive in everyday life, yet their propensity to reproduce biases inherited from training data remains a pressing concern. Prior investigations into bias in LLMs have focused on the association of social groups with stereotypical attributes. However, this is only one form of human bias such systems may reproduce. We investigate a new form of bias in LLMs that resembles a social psychological phenomenon where socially subordinate groups are perceived as more homogeneous than socially dominant groups. We had ChatGPT, a state-of-the-art LLM, generate texts about intersectional group identities and compared those texts on measures of homogeneity. We consistently found that ChatGPT portrayed African, Asian, and Hispanic Americans as more homogeneous than White Americans, indicating that the model described racial minority groups with a narrower range of human experience. ChatGPT also portrayed women as more homogeneous than men, but these differences were small. Finally, we found that the effect of gender differed across racial/ethnic groups such that the effect of gender was consistent within African and Hispanic Americans but not within Asian and White Americans. We argue that the tendency of LLMs to describe groups as less diverse risks perpetuating stereotypes and discriminatory behavior.
4/29/2024
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Tianyu Shi
0
0
Biases and stereotypes in Large Language Models (LLMs) can have negative implications for user experience and societal outcomes. Current approaches to bias mitigation like Reinforcement Learning from Human Feedback (RLHF) rely on costly manual feedback. While LLMs have the capability to understand logic and identify biases in text, they often struggle to effectively acknowledge and address their own biases due to factors such as prompt influences, internal mechanisms, and policies. We found that informing LLMs that the content they generate is not their own and questioning them about potential biases in the text can significantly enhance their recognition and improvement capabilities regarding biases. Based on this finding, we propose RLRF (Reinforcement Learning from Reflection through Debates as Feedback), replacing human feedback with AI for bias mitigation. RLRF engages LLMs in multi-role debates to expose biases and gradually reduce biases in each iteration using a ranking scoring mechanism. The dialogue are then used to create a dataset with high-bias and low-bias instances to train the reward model in reinforcement learning. This dataset can be generated by the same LLMs for self-reflection or a superior LLMs guiding the former in a student-teacher mode to enhance its logical reasoning abilities. Experimental results demonstrate the significant effectiveness of our approach in bias reduction.
4/30/2024