DPDEdit: Detail-Preserved Diffusion Models for Multimodal Fashion Image Editing

0
🖼️
Sign in to get full access
Overview
- The provided paper introduces a novel approach for multimodal fashion garment synthesis using a deep learning model.
- The model is capable of generating high-quality fashion garments based on various input modalities, including text descriptions, images, and sketches.
- The research demonstrates the effectiveness of the proposed method in producing realistic and diverse fashion designs.
Plain English Explanation
The paper describes a deep learning system that can create virtual fashion garments based on different types of inputs. For example, the model can generate a 3D clothing item by taking a text description, an image, or a sketch as input. This allows designers and consumers to experiment with new clothing designs more easily. The key idea is to combine multiple data sources, such as text and images, to give the model a richer understanding of fashion and enable it to generate more realistic and varied clothing. By using this technology, the fashion industry could become more efficient and accessible, as it would be easier to experiment with new designs and trends.
Technical Explanation
The paper introduces a novel FashionSD-X model for multimodal fashion garment synthesis. The model is designed to take a combination of text descriptions, images, and sketches as input and generate high-quality 3D clothing designs.
The architecture of the FashionSD-X model includes:
- A text encoder to extract semantic features from the input text
- An image encoder to extract visual features from the input image or sketch
- A cross-modal fusion module to combine the text and visual features
- A garment generation module to produce the final 3D clothing design
The key innovation of the FashionSD-X model is its ability to leverage multiple input modalities to create more realistic and diverse fashion designs. By incorporating text, image, and sketch data, the model can better understand the context and constraints of fashion, resulting in more visually appealing and conceptually coherent garments.
Critical Analysis
The paper presents a promising approach to multimodal fashion garment synthesis, but it also acknowledges some limitations and areas for further research:
- The current model is limited to generating single garment items, whereas real-world fashion often involves coordinating multiple pieces. Future work could explore ways to generate complete outfits.
- The training dataset used in the experiments is relatively small, which may limit the diversity and complexity of the generated designs. Expanding the dataset could lead to more varied and high-quality results.
- The paper does not provide detailed comparisons to existing state-of-the-art methods in this domain, making it difficult to fully assess the relative performance of the FashionSD-X model.
- While the generated garments appear realistic, their practical suitability for manufacturing and real-world use is not extensively evaluated. Further research could explore the integration of the model with downstream manufacturing processes.
Overall, the FashionSD-X model represents an interesting step forward in multimodal fashion design, but there are still opportunities to expand its capabilities and validate its real-world applicability.
Conclusion
The paper introduces the FashionSD-X model, a novel deep learning-based approach for multimodal fashion garment synthesis. By leveraging text, image, and sketch inputs, the model can generate high-quality 3D clothing designs that are visually appealing and conceptually coherent.
This research demonstrates the potential of using advanced AI technologies to enhance the fashion design process, making it more efficient, accessible, and exploratory. While the current model has some limitations, the promising results suggest that continued advancements in this area could have significant implications for the fashion industry, enabling designers and consumers to more easily experiment with new styles and trends.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
DPDEdit: Detail-Preserved Diffusion Models for Multimodal Fashion Image Editing
Xiaolong Wang, Zhi-Qi Cheng, Jue Wang, Xiaojiang Peng
Fashion image editing is a crucial tool for designers to convey their creative ideas by visualizing design concepts interactively. Current fashion image editing techniques, though advanced with multimodal prompts and powerful diffusion models, often struggle to accurately identify editing regions and preserve the desired garment texture detail. To address these challenges, we introduce a new multimodal fashion image editing architecture based on latent diffusion models, called Detail-Preserved Diffusion Models (DPDEdit). DPDEdit guides the fashion image generation of diffusion models by integrating text prompts, region masks, human pose images, and garment texture images. To precisely locate the editing region, we first introduce Grounded-SAM to predict the editing region based on the user's textual description, and then combine it with other conditions to perform local editing. To transfer the detail of the given garment texture into the target fashion image, we propose a texture injection and refinement mechanism. Specifically, this mechanism employs a decoupled cross-attention layer to integrate textual descriptions and texture images, and incorporates an auxiliary U-Net to preserve the high-frequency details of generated garment texture. Additionally, we extend the VITON-HD dataset using a multimodal large language model to generate paired samples with texture images and textual descriptions. Extensive experiments show that our DPDEdit outperforms state-of-the-art methods in terms of image fidelity and coherence with the given multimodal inputs.
Read more9/17/2024

0
FashionSD-X: Multimodal Fashion Garment Synthesis using Latent Diffusion
Abhishek Kumar Singh, Ioannis Patras
The rapid evolution of the fashion industry increasingly intersects with technological advancements, particularly through the integration of generative AI. This study introduces a novel generative pipeline designed to transform the fashion design process by employing latent diffusion models. Utilizing ControlNet and LoRA fine-tuning, our approach generates high-quality images from multimodal inputs such as text and sketches. We leverage and enhance state-of-the-art virtual try-on datasets, including Multimodal Dress Code and VITON-HD, by integrating sketch data. Our evaluation, utilizing metrics like FID, CLIP Score, and KID, demonstrates that our model significantly outperforms traditional stable diffusion models. The results not only highlight the effectiveness of our model in generating fashion-appropriate outputs but also underscore the potential of diffusion models in revolutionizing fashion design workflows. This research paves the way for more interactive, personalized, and technologically enriched methodologies in fashion design and representation, bridging the gap between creative vision and practical application.
Read more4/30/2024
0
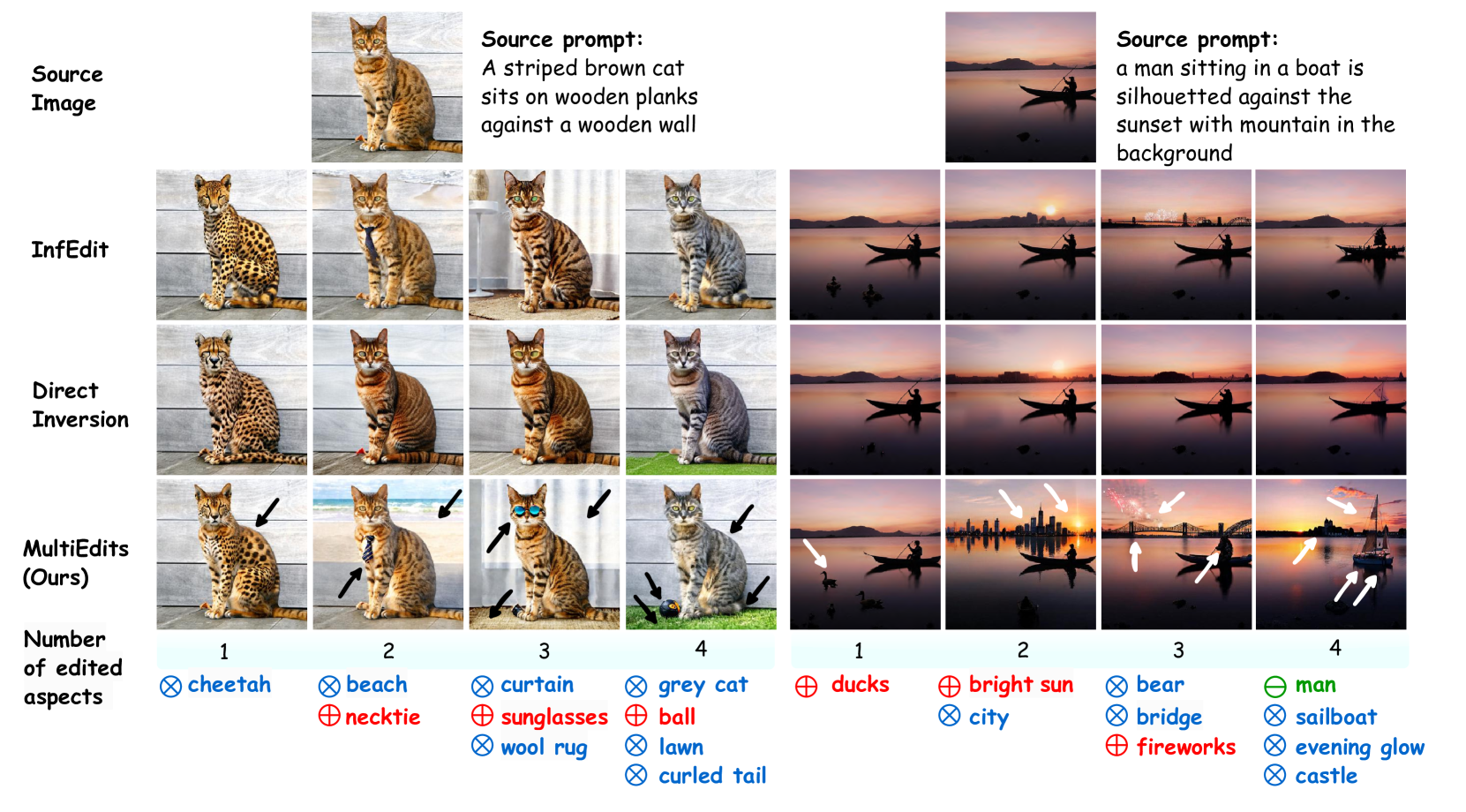
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Mingzhen Huang, Jialing Cai, Shan Jia, Vishnu Suresh Lokhande, Siwei Lyu
Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
Read more6/4/2024
🖼️
0
PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor
Vidit Goel, Elia Peruzzo, Yifan Jiang, Dejia Xu, Xingqian Xu, Nicu Sebe, Trevor Darrell, Zhangyang Wang, Humphrey Shi
Generative image editing has recently witnessed extremely fast-paced growth. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we tackle the task by perceiving the images as an amalgamation of various objects and aim to control the properties of each object in a fine-grained manner. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose PAIR Diffusion, a generic framework that can enable a diffusion model to control the structure and appearance properties of each object in the image. We show that having control over the properties of each object in an image leads to comprehensive editing capabilities. Our framework allows for various object-level editing operations on real images such as reference image-based appearance editing, free-form shape editing, adding objects, and variations. Thanks to our design, we do not require any inversion step. Additionally, we propose multimodal classifier-free guidance which enables editing images using both reference images and text when using our approach with foundational diffusion models. We validate the above claims by extensively evaluating our framework on both unconditional and foundational diffusion models. Please refer to https://vidit98.github.io/publication/conference-paper/pair_diff.html for code and model release.
Read more4/10/2024