PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor
2303.17546
0
0
🖼️
Abstract
Generative image editing has recently witnessed extremely fast-paced growth. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we tackle the task by perceiving the images as an amalgamation of various objects and aim to control the properties of each object in a fine-grained manner. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose PAIR Diffusion, a generic framework that can enable a diffusion model to control the structure and appearance properties of each object in the image. We show that having control over the properties of each object in an image leads to comprehensive editing capabilities. Our framework allows for various object-level editing operations on real images such as reference image-based appearance editing, free-form shape editing, adding objects, and variations. Thanks to our design, we do not require any inversion step. Additionally, we propose multimodal classifier-free guidance which enables editing images using both reference images and text when using our approach with foundational diffusion models. We validate the above claims by extensively evaluating our framework on both unconditional and foundational diffusion models. Please refer to https://vidit98.github.io/publication/conference-paper/pair_diff.html for code and model release.
Create account to get full access
Overview
- Generative image editing has seen rapid growth, with methods using high-level conditioning like text or low-level conditioning.
- Most existing methods lack fine-grained control over the properties of different objects in the image.
- This work aims to enable control over the structure and appearance of individual objects in an image.
- The proposed PAIR Diffusion framework allows for comprehensive object-level editing capabilities.
- The framework can be used with both unconditional and foundational diffusion models.
Plain English Explanation
Generating and editing images using AI has become a rapidly advancing field. Some approaches use high-level instructions like text, while others use low-level details. However, most of these methods don't give you fine-grained control over the individual objects in the image.
This research introduces a new framework called PAIR Diffusion that aims to change that. It lets you precisely control the structure and appearance of each object in an image. This allows for a wide range of editing possibilities, like changing the shape or look of specific objects, adding new objects, and generating variations.
The key idea is to treat the image as a collection of different objects, and then give the AI system the ability to independently manipulate the properties of each one. This granular control over the image contents is what enables the comprehensive editing capabilities.
The framework works with both basic diffusion models that generate images from scratch, as well as more advanced "foundational" diffusion models. It also includes a novel technique for guiding the editing process using both reference images and text instructions.
Technical Explanation
The PAIR Diffusion framework builds on top of diffusion models, which are a powerful class of generative AI models. Diffusion models work by starting with random noise and progressively refining it into a realistic image through a series of denoising steps.
The key innovation in this work is to extend diffusion models to enable fine-grained control over the structure and appearance of individual objects in the generated images. This is achieved by perceiving the image as a composition of different objects, and learning to independently manipulate the properties of each one.
Specifically, the framework uses object detection to identify the objects in the image, and then learns to predict the structure (shape) and appearance (texture, color, etc.) of each object. During the image generation process, the model can then adjust these object-level properties to produce the desired editing effects.
The framework is designed to be generic and can be applied to both unconditional diffusion models that generate images from scratch, as well as more advanced "foundational" diffusion models that can be guided by additional modalities like text or reference images. For the latter case, the authors propose a novel multimodal classifier-free guidance technique.
Through extensive experiments, the authors demonstrate the ability of their PAIR Diffusion framework to enable a wide range of object-level editing operations, including reference-based appearance editing, free-form shape editing, object addition, and variations. They show results on both unconditional and foundational diffusion models, highlighting the generality of the approach.
Critical Analysis
The PAIR Diffusion framework represents an important step forward in generative image editing, providing a novel way to achieve fine-grained control over image contents. The ability to independently manipulate the structure and appearance of objects is a valuable capability that could enable more sophisticated and creative editing workflows.
However, the paper also acknowledges some limitations of the current approach. For example, the object detection and segmentation components are still imperfect, and may struggle with complex or overlapping objects. Additionally, the framework does not yet support editing relationships between objects, which could be an important direction for future work.
It would also be interesting to see how the PAIR Diffusion framework compares to other recent approaches for object-level image editing, such as ClickDiffusion or DiffHarmony. A more thorough comparative analysis could help identify the unique strengths and tradeoffs of each method.
Overall, the PAIR Diffusion framework represents an exciting development in the field of generative image editing, and its potential impact will likely depend on how the technique evolves and is applied in the future.
Conclusion
The PAIR Diffusion framework introduced in this paper represents a significant advancement in generative image editing. By providing fine-grained control over the structure and appearance of individual objects within an image, it enables a wide range of comprehensive editing capabilities.
This work highlights the potential for diffusion models to go beyond simply generating images from scratch, and instead be used as powerful tools for interactive image manipulation and content creation. The ability to edit images at the object level could open up new creative possibilities and workflows for artists, designers, and hobbyists alike.
While the current implementation has some limitations, the core ideas behind PAIR Diffusion represent an important step forward in generative image editing. Continued research and development in this area could lead to even more advanced and user-friendly tools for visual content creation and modification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
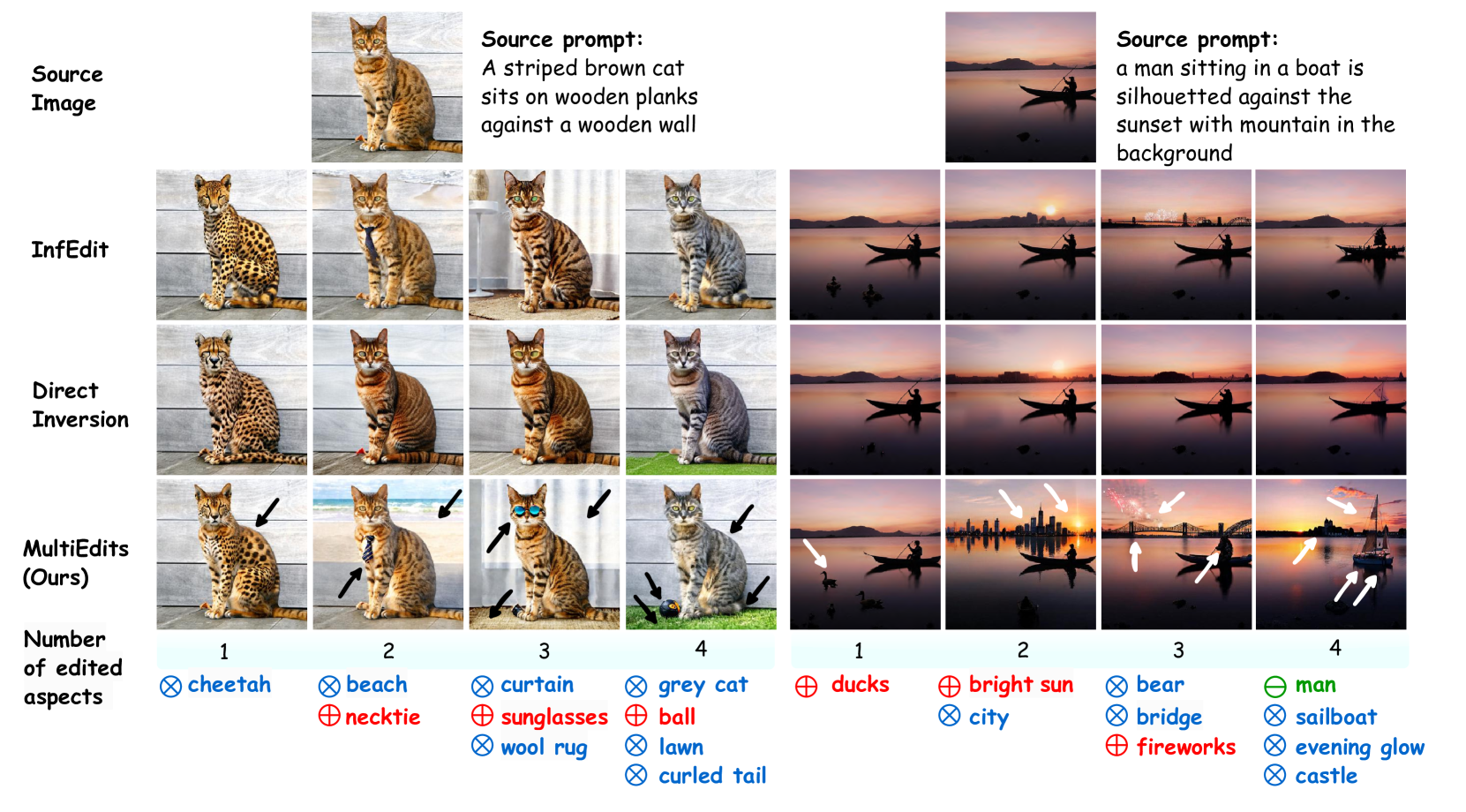
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Mingzhen Huang, Jialing Cai, Shan Jia, Vishnu Suresh Lokhande, Siwei Lyu
0
0
Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
6/4/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024
🖼️
GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
Rahul Sajnani, Jeroen Vanbaar, Jie Min, Kapil Katyal, Srinath Sridhar
0
0
The success of image generative models has enabled us to build methods that can edit images based on text or other user input. However, these methods are bespoke, imprecise, require additional information, or are limited to only 2D image edits. We present GeoDiffuser, a zero-shot optimization-based method that unifies common 2D and 3D image-based object editing capabilities into a single method. Our key insight is to view image editing operations as geometric transformations. We show that these transformations can be directly incorporated into the attention layers in diffusion models to implicitly perform editing operations. Our training-free optimization method uses an objective function that seeks to preserve object style but generate plausible images, for instance with accurate lighting and shadows. It also inpaints disoccluded parts of the image where the object was originally located. Given a natural image and user input, we segment the foreground object using SAM and estimate a corresponding transform which is used by our optimization approach for editing. GeoDiffuser can perform common 2D and 3D edits like object translation, 3D rotation, and removal. We present quantitative results, including a perceptual study, that shows how our approach is better than existing methods. Visit https://ivl.cs.brown.edu/research/geodiffuser.html for more information.
4/23/2024
🖼️
Streamlining Image Editing with Layered Diffusion Brushes
Peyman Gholami, Robert Xiao
0
0
Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
5/2/2024