DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection

0

Sign in to get full access
Overview
- This paper presents DPDETR, a novel model for detecting objects in infrared-visible images.
- It uses a decoupled learning approach to separately handle object detection and position encoding.
- The model achieves state-of-the-art performance on infrared-visible object detection benchmarks.
Plain English Explanation
The paper introduces DPDETR, a new deep learning model for detecting objects in infrared-visible images. Infrared-visible imaging is useful for applications like security and defense, where both thermal and visible information can be valuable.
The key idea behind DPDETR is decoupling the tasks of object detection and position encoding. Traditional object detection models try to handle both of these tasks simultaneously, which can be challenging. DPDETR instead separates them into two distinct components:
- Object Detection: This part of the model focuses solely on identifying the presence and class of objects in the image.
- Position Encoding: This component is responsible for accurately localizing the position of the detected objects.
By decoupling these tasks, DPDETR is able to better optimize each component and ultimately achieve superior performance on infrared-visible object detection benchmarks compared to previous approaches.
The paper also introduces a feature alignment technique to help the model better integrate information from the infrared and visible image channels. Additionally, the authors employ a denoising training strategy to improve the model's robustness to noise in the input images.
Technical Explanation
DPDETR is built upon the DETR (Detector Transformer) architecture, which uses a transformer-based approach for object detection. However, DPDETR introduces several key modifications:
-
Decoupled Learning: The model separates the object detection and position encoding tasks into two distinct components, each with its own optimization objective. This allows the model to better specialize in each sub-task.
-
Feature Alignment: To effectively combine information from the infrared and visible image channels, DPDETR employs a feature alignment module. This helps the model learn a unified representation that captures relevant details from both modalities.
-
Denoising Training: The authors train DPDETR using a denoising strategy, where the model is exposed to noisy input images during training. This improves the model's robustness to real-world noise and artifacts in the input data.
The experiments in the paper demonstrate that DPDETR outperforms previous state-of-the-art methods on several infrared-visible object detection benchmarks. The decoupled learning approach, feature alignment, and denoising training all contribute to the model's strong performance.
Critical Analysis
The paper presents a well-designed and thorough study of DPDETR, but there are a few potential areas for improvement or further exploration:
-
Generalization: While DPDETR excels on the specific infrared-visible benchmarks used in the experiments, it would be valuable to assess its performance on a broader range of object detection tasks and datasets. This could help validate the model's generalization capabilities.
-
Computational Efficiency: The paper does not provide a detailed analysis of the model's computational complexity or inference time. As real-world applications may have strict latency requirements, exploring ways to optimize DPDETR's efficiency could be beneficial.
-
Interpretability: The paper does not delve into the interpretability of DPDETR's decision-making process. Providing insights into how the model arrives at its predictions could help build trust and enable further refinements.
-
Ethical Considerations: The paper does not address any potential ethical concerns or societal impacts of the proposed infrared-visible object detection technology. Considering these aspects could help ensure the responsible development and deployment of such systems.
Conclusion
This paper introduces DPDETR, a novel deep learning model for infrared-visible object detection that achieves state-of-the-art performance. By decoupling the object detection and position encoding tasks, and incorporating feature alignment and denoising training strategies, DPDETR demonstrates significant improvements over previous approaches.
The technical contributions of DPDETR, along with the potential for real-world applications in areas like security and defense, make this an important advancement in the field of object detection. While the paper presents a robust evaluation, further research into the model's generalization, efficiency, interpretability, and ethical considerations could help strengthen the impact and practical viability of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection
Junjie Guo, Chenqiang Gao, Fangcen Liu, Deyu Meng
Infrared-visible object detection aims to achieve robust object detection by leveraging the complementary information of infrared and visible image pairs. However, the commonly existing modality misalignment problem presents two challenges: fusing misalignment complementary features is difficult, and current methods cannot accurately locate objects in both modalities under misalignment conditions. In this paper, we propose a Decoupled Position Detection Transformer (DPDETR) to address these problems. Specifically, we explicitly formulate the object category, visible modality position, and infrared modality position to enable the network to learn the intrinsic relationships and output accurate positions of objects in both modalities. To fuse misaligned object features accurately, we propose a Decoupled Position Multispectral Cross-attention module that adaptively samples and aggregates multispectral complementary features with the constraint of infrared and visible reference positions. Additionally, we design a query-decoupled Multispectral Decoder structure to address the optimization gap among the three kinds of object information in our task and propose a Decoupled Position Contrastive DeNosing Training strategy to enhance the DPDETR's ability to learn decoupled positions. Experiments on DroneVehicle and KAIST datasets demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DPDETR.
Read more8/13/2024

0
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Zichao Dong, Yilin Zhang, Xufeng Huang, Hang Ji, Zhan Shi, Xin Zhan, Junbo Chen
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78% AP which create new state of the art on ScanNetv2 benchmark.
Read more8/14/2024
0
Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
Xiuquan Hou, Meiqin Liu, Senlin Zhang, Ping Wei, Badong Chen, Xuguang Lan
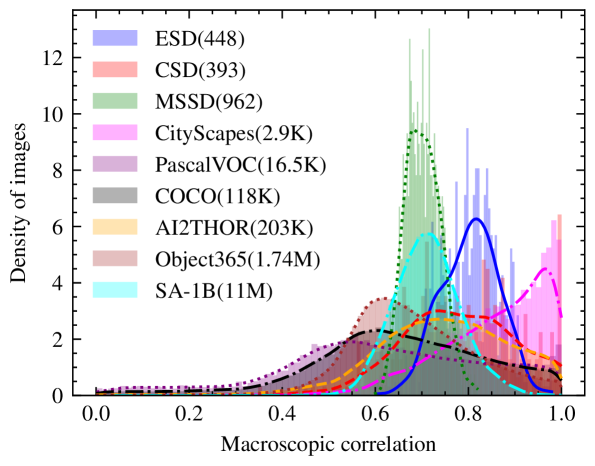
This paper presents a general scheme for enhancing the convergence and performance of DETR (DEtection TRansformer). We investigate the slow convergence problem in transformers from a new perspective, suggesting that it arises from the self-attention that introduces no structural bias over inputs. To address this issue, we explore incorporating position relation prior as attention bias to augment object detection, following the verification of its statistical significance using a proposed quantitative macroscopic correlation (MC) metric. Our approach, termed Relation-DETR, introduces an encoder to construct position relation embeddings for progressive attention refinement, which further extends the traditional streaming pipeline of DETR into a contrastive relation pipeline to address the conflicts between non-duplicate predictions and positive supervision. Extensive experiments on both generic and task-specific datasets demonstrate the effectiveness of our approach. Under the same configurations, Relation-DETR achieves a significant improvement (+2.0% AP compared to DINO), state-of-the-art performance (51.7% AP for 1x and 52.1% AP for 2x settings), and a remarkably faster convergence speed (over 40% AP with only 2 training epochs) than existing DETR detectors on COCO val2017. Moreover, the proposed relation encoder serves as a universal plug-in-and-play component, bringing clear improvements for theoretically any DETR-like methods. Furthermore, we introduce a class-agnostic detection dataset, SA-Det-100k. The experimental results on the dataset illustrate that the proposed explicit position relation achieves a clear improvement of 1.3% AP, highlighting its potential towards universal object detection. The code and dataset are available at https://github.com/xiuqhou/Relation-DETR.
Read more7/17/2024
0
SpecDETR: A Transformer-based Hyperspectral Point Object Detection Network
Zhaoxu Li, Wei An, Gaowei Guo, Longguang Wang, Yingqian Wang, Zaiping Lin
Hyperspectral target detection (HTD) aims to identify specific materials based on spectral information in hyperspectral imagery and can detect point targets, some of which occupy a smaller than one-pixel area. However, existing HTD methods are developed based on per-pixel binary classification, which limits the feature representation capability for point targets. In this paper, we rethink the hyperspectral point target detection from the object detection perspective, and focus more on the object-level prediction capability rather than the pixel classification capability. Inspired by the token-based processing flow of Detection Transformer (DETR), we propose the first specialized network for hyperspectral multi-class point object detection, SpecDETR. Without the backbone part of the current object detection framework, SpecDETR treats the spectral features of each pixel in hyperspectral images as a token and utilizes a multi-layer Transformer encoder with local and global coordination attention modules to extract deep spatial-spectral joint features. SpecDETR regards point object detection as a one-to-many set prediction problem, thereby achieving a concise and efficient DETR decoder that surpasses the current state-of-the-art DETR decoder in terms of parameters and accuracy in point object detection. We develop a simulated hyperSpectral Point Object Detection benchmark termed SPOD, and for the first time, evaluate and compare the performance of current object detection networks and HTD methods on hyperspectral multi-class point object detection. SpecDETR demonstrates superior performance as compared to current object detection networks and HTD methods on the SPOD dataset. Additionally, we validate on a public HTD dataset that by using data simulation instead of manual annotation, SpecDETR can detect real-world single-spectral point objects directly.
Read more5/17/2024