Relation DETR: Exploring Explicit Position Relation Prior for Object Detection

0
Sign in to get full access
Overview
- The paper "Relation DETR: Exploring Explicit Position Relation Prior for Object Detection" proposes a new object detection model called Relation DETR that incorporates explicit spatial relationships between objects.
- This is an extension of the DETR (Detection Transformer) model, which uses a transformer-based architecture for object detection.
- The key idea is to model the relative positions of objects explicitly, as this can provide useful information for detecting and localizing objects.
Plain English Explanation
The paper introduces a new object detection model called Relation DETR. Object detection is the task of finding and identifying objects in an image. Relation DETR builds on an existing model called DETR, which uses a transformer-based architecture for this task.
The key innovation in Relation DETR is that it explicitly models the spatial relationships between objects. For example, it might learn that a car is usually below a traffic light, or that a person is often next to a bicycle. By encoding these kinds of spatial relations, the model can better understand the scene and improve its ability to detect and localize objects.
This is an important advance because the relative positions of objects can provide valuable cues for detection. If the model knows that certain objects tend to co-occur in particular spatial configurations, it can use this information to make more accurate predictions.
The authors show that Relation DETR outperforms the original DETR model on standard object detection benchmarks. This suggests that explicitly modeling object relations is an effective way to enhance the performance of transformer-based object detectors.
Technical Explanation
The Relation DETR model builds on the DETR architecture by incorporating an explicit representation of the spatial relationships between objects. DETR uses a transformer-based approach to object detection, where a set of learned object queries are matched to the features in the input image.
Relation DETR extends this by adding a "relation encoder" module that learns to encode the relative positions of the detected objects. This relation encoder takes the object queries and the image features as input, and outputs a set of relation features that capture the spatial dependencies between the objects.
These relation features are then combined with the original object queries, and the entire model is trained end-to-end. The authors show that this explicit modeling of object relations leads to improved performance on standard object detection benchmarks, compared to the original DETR model.
The Enhancing DETR's Variants Through Improved Content Query and DQ-DETR: DETR Dynamic Query for Tiny Object papers also explore ways to enhance DETR-based object detectors, but they focus on different aspects of the model architecture.
Critical Analysis
The Relation DETR paper presents a compelling approach to improving object detection by explicitly modeling spatial relationships between objects. The authors provide a thorough evaluation, showing consistent improvements over the original DETR model on multiple datasets and task settings.
One potential limitation is that the relation encoder module adds extra complexity to the model, which could make it more computationally expensive or harder to train. The authors do not provide extensive analysis of the computational or training cost of their approach.
Additionally, the paper does not explore how Relation DETR might perform on more challenging or crowded scenes, where the spatial relationships between objects could be more complex and ambiguous. The MutDet: Mutually Optimizing Pre-training for Remote Sensing paper, for example, looks at object detection in aerial imagery, which often involves dense and overlapping objects.
Overall, the Relation DETR model represents a promising direction for enhancing transformer-based object detectors by incorporating explicit spatial reasoning. Further research could explore ways to make the relation modeling more efficient, as well as evaluating the approach on a wider range of detection scenarios.
Conclusion
The "Relation DETR" paper presents a novel object detection model that explicitly encodes the spatial relationships between detected objects. By incorporating a relation encoder module, the model is able to leverage information about the relative positions of objects, which can improve its ability to detect and localize objects in an image.
The authors demonstrate that Relation DETR outperforms the original DETR model on standard object detection benchmarks, highlighting the value of modeling object-to-object spatial dependencies. This work represents an important advancement in transformer-based object detection, and the ideas could potentially be applied to enhance other detection models as well.
Overall, the Relation DETR model provides a compelling approach for enhancing the performance of object detectors by incorporating explicit spatial reasoning. As computer vision systems continue to play an increasingly important role in applications like autonomous driving, surveillance, and image understanding, techniques like this that can better capture the spatial structure of scenes will likely become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
Xiuquan Hou, Meiqin Liu, Senlin Zhang, Ping Wei, Badong Chen, Xuguang Lan
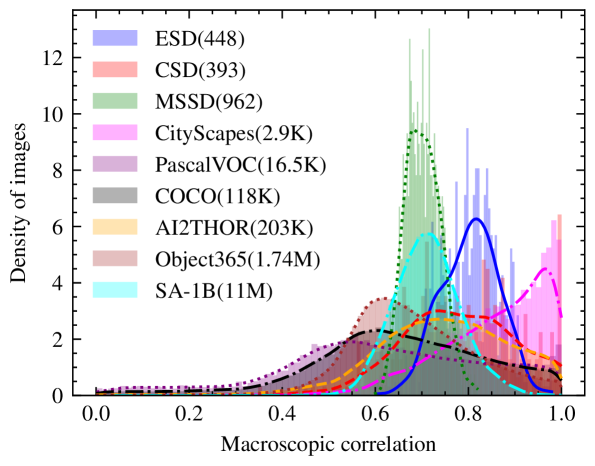
This paper presents a general scheme for enhancing the convergence and performance of DETR (DEtection TRansformer). We investigate the slow convergence problem in transformers from a new perspective, suggesting that it arises from the self-attention that introduces no structural bias over inputs. To address this issue, we explore incorporating position relation prior as attention bias to augment object detection, following the verification of its statistical significance using a proposed quantitative macroscopic correlation (MC) metric. Our approach, termed Relation-DETR, introduces an encoder to construct position relation embeddings for progressive attention refinement, which further extends the traditional streaming pipeline of DETR into a contrastive relation pipeline to address the conflicts between non-duplicate predictions and positive supervision. Extensive experiments on both generic and task-specific datasets demonstrate the effectiveness of our approach. Under the same configurations, Relation-DETR achieves a significant improvement (+2.0% AP compared to DINO), state-of-the-art performance (51.7% AP for 1x and 52.1% AP for 2x settings), and a remarkably faster convergence speed (over 40% AP with only 2 training epochs) than existing DETR detectors on COCO val2017. Moreover, the proposed relation encoder serves as a universal plug-in-and-play component, bringing clear improvements for theoretically any DETR-like methods. Furthermore, we introduce a class-agnostic detection dataset, SA-Det-100k. The experimental results on the dataset illustrate that the proposed explicit position relation achieves a clear improvement of 1.3% AP, highlighting its potential towards universal object detection. The code and dataset are available at https://github.com/xiuqhou/Relation-DETR.
Read more7/17/2024
0
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
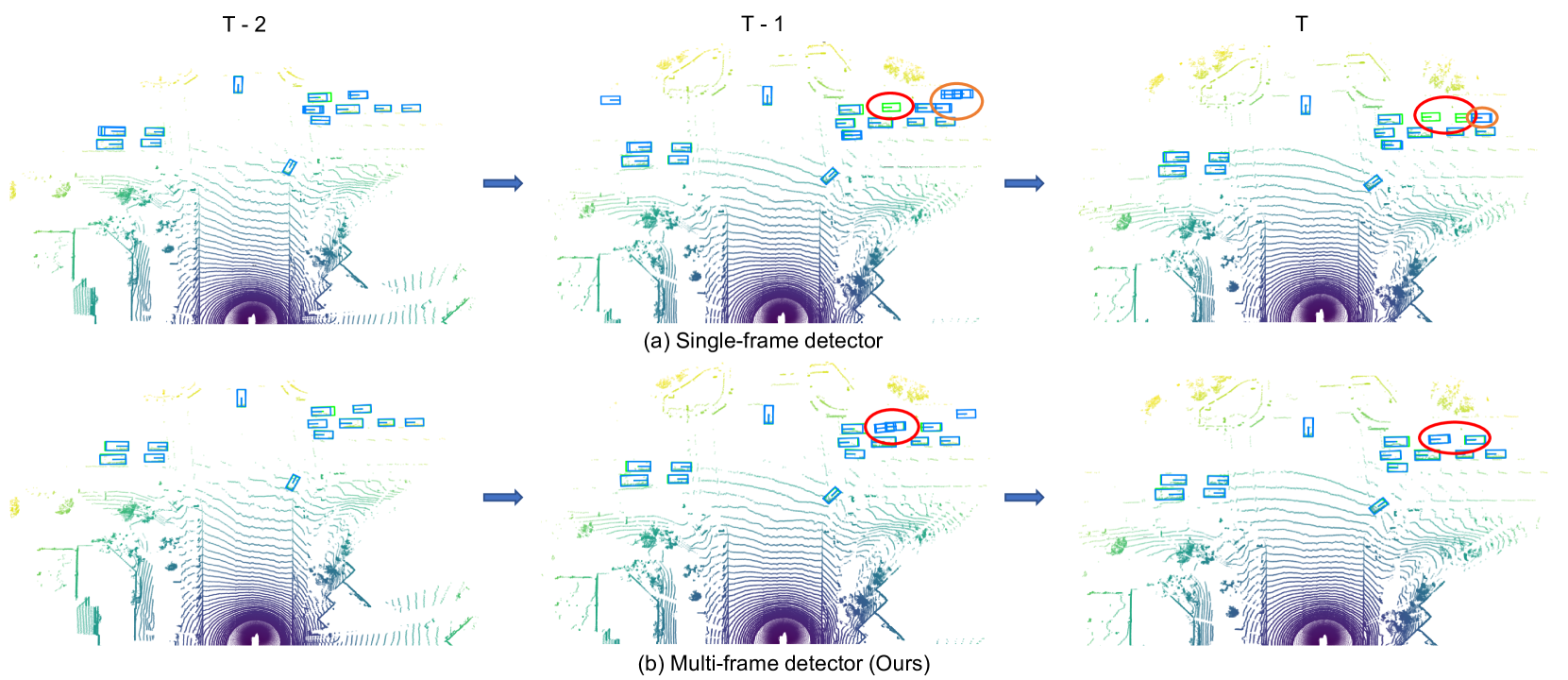
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024

0
DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection
Junjie Guo, Chenqiang Gao, Fangcen Liu, Deyu Meng
Infrared-visible object detection aims to achieve robust object detection by leveraging the complementary information of infrared and visible image pairs. However, the commonly existing modality misalignment problem presents two challenges: fusing misalignment complementary features is difficult, and current methods cannot accurately locate objects in both modalities under misalignment conditions. In this paper, we propose a Decoupled Position Detection Transformer (DPDETR) to address these problems. Specifically, we explicitly formulate the object category, visible modality position, and infrared modality position to enable the network to learn the intrinsic relationships and output accurate positions of objects in both modalities. To fuse misaligned object features accurately, we propose a Decoupled Position Multispectral Cross-attention module that adaptively samples and aggregates multispectral complementary features with the constraint of infrared and visible reference positions. Additionally, we design a query-decoupled Multispectral Decoder structure to address the optimization gap among the three kinds of object information in our task and propose a Decoupled Position Contrastive DeNosing Training strategy to enhance the DPDETR's ability to learn decoupled positions. Experiments on DroneVehicle and KAIST datasets demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DPDETR.
Read more8/13/2024
🎯
0
Enhancing DETRs Variants through Improved Content Query and Similar Query Aggregation
Yingying Zhang, Chuangji Shi, Xin Guo, Jiangwei Lao, Jian Wang, Jiaotuan Wang, Jingdong Chen
The design of the query is crucial for the performance of DETR and its variants. Each query consists of two components: a content part and a positional one. Traditionally, the content query is initialized with a zero or learnable embedding, lacking essential content information and resulting in sub-optimal performance. In this paper, we introduce a novel plug-and-play module, Self-Adaptive Content Query (SACQ), to address this limitation. The SACQ module utilizes features from the transformer encoder to generate content queries via self-attention pooling. This allows candidate queries to adapt to the input image, resulting in a more comprehensive content prior and better focus on target objects. However, this improved concentration poses a challenge for the training process that utilizes the Hungarian matching, which selects only a single candidate and suppresses other similar ones. To overcome this, we propose a query aggregation strategy to cooperate with SACQ. It merges similar predicted candidates from different queries, easing the optimization. Our extensive experiments on the COCO dataset demonstrate the effectiveness of our proposed approaches across six different DETR's variants with multiple configurations, achieving an average improvement of over 1.0 AP.
Read more5/7/2024