MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers

0

Sign in to get full access
Overview
- This paper introduces MV-DETR, a multi-modality indoor object detection model using Multi-View Detection Transformers.
- The model leverages RGB, depth, and semantic segmentation inputs to improve indoor object detection performance.
- The authors propose a novel multi-modal fusion mechanism and training strategy to effectively combine the different data modalities.
Plain English Explanation
The MV-DETR model is designed to detect objects in indoor environments by using multiple types of sensor data. Typical object detection models only use RGB (color) images, but MV-DETR also incorporates depth information and semantic segmentation.
Depth data provides information about the 3D structure of a scene, which can be helpful for understanding the spatial relationships between objects. Semantic segmentation divides the image into different regions corresponding to distinct objects or surfaces. By combining these three modalities - RGB, depth, and segmentation - the model can gain a more comprehensive understanding of the indoor environment and the objects within it.
The key innovation in MV-DETR is the way it fuses this multi-modal data. The model uses a specialized fusion mechanism to effectively integrate the different data sources, allowing it to leverage the complementary information they provide. This multi-modal fusion strategy enables MV-DETR to outperform object detection models that only use RGB images.
Technical Explanation
The MV-DETR architecture consists of a backbone network that processes the RGB, depth, and semantic segmentation inputs, and a detection head that predicts the bounding boxes and classes of the detected objects.
The backbone network uses a Transformer-based encoder to extract features from each modality, and a multi-modal fusion module to combine these features. The fusion module applies attention mechanisms to weigh the importance of each modality and generate a unified feature representation.
The detection head then takes this fused feature map and applies a set of object queries to predict the final object detections. The authors also introduce a novel training strategy that jointly optimizes the model for all three data modalities, further enhancing the multi-modal learning process.
The experiments demonstrate that MV-DETR outperforms state-of-the-art single-modal and multi-modal object detection models on several indoor datasets. The model is able to leverage the complementary information provided by the different sensor inputs to achieve superior detection performance.
Critical Analysis
The MV-DETR paper presents a promising approach for multi-modal indoor object detection, but there are a few potential limitations and areas for further research:
- The model was evaluated on relatively small-scale indoor datasets, so its performance on larger, more diverse datasets remains to be seen. Scaling the model to real-world scenarios may require additional considerations.
- The paper does not provide much analysis on the relative importance or contributions of the different modalities (RGB, depth, segmentation). Understanding how each input type affects the model's performance could lead to further improvements.
- The multi-modal fusion mechanism, while novel, could potentially be explored further. Alternative fusion strategies or architectures may yield additional performance gains.
- The paper focuses on 2D object detection, but extending the approach to 3D object detection in indoor scenes could be an interesting direction for future work.
Overall, the MV-DETR model demonstrates the value of leveraging multi-modal sensor data for indoor object detection, and the research provides a solid foundation for future work in this area.
Conclusion
The MV-DETR paper presents a novel multi-modal object detection model for indoor environments. By combining RGB, depth, and semantic segmentation data, the model is able to achieve superior performance compared to single-modal approaches.
The key innovations include a specialized multi-modal fusion mechanism and a joint training strategy that optimizes the model for all three data modalities. The experiments show that this multi-modal approach can significantly improve indoor object detection, with potential applications in areas such as robotics, augmented reality, and smart home technology.
While the paper has some limitations, the research provides a valuable contribution to the field of multi-modal computer vision. The MV-DETR model demonstrates the potential of leveraging diverse sensor data to enhance object detection, and the work paves the way for further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Zichao Dong, Yilin Zhang, Xufeng Huang, Hang Ji, Zhan Shi, Xin Zhan, Junbo Chen
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78% AP which create new state of the art on ScanNetv2 benchmark.
Read more8/14/2024

0
LightMDETR: A Lightweight Approach for Low-Cost Open-Vocabulary Object Detection Training
Binta Sow, Bilal Faye, Hanane Azzag, Mustapha Lebbah
Object detection in computer vision traditionally involves identifying objects in images. By integrating textual descriptions, we enhance this process, providing better context and accuracy. The MDETR model significantly advances this by combining image and text data for more versatile object detection and classification. However, MDETR's complexity and high computational demands hinder its practical use. In this paper, we introduce Lightweight MDETR (LightMDETR), an optimized MDETR variant designed for improved computational efficiency while maintaining robust multimodal capabilities. Our approach involves freezing the MDETR backbone and training a sole component, the Deep Fusion Encoder (DFE), to represent image and text modalities. A learnable context vector enables the DFE to switch between these modalities. Evaluation on datasets like RefCOCO, RefCOCO+, and RefCOCOg demonstrates that LightMDETR achieves superior precision and accuracy.
Read more8/21/2024

0
DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection
Junjie Guo, Chenqiang Gao, Fangcen Liu, Deyu Meng
Infrared-visible object detection aims to achieve robust object detection by leveraging the complementary information of infrared and visible image pairs. However, the commonly existing modality misalignment problem presents two challenges: fusing misalignment complementary features is difficult, and current methods cannot accurately locate objects in both modalities under misalignment conditions. In this paper, we propose a Decoupled Position Detection Transformer (DPDETR) to address these problems. Specifically, we explicitly formulate the object category, visible modality position, and infrared modality position to enable the network to learn the intrinsic relationships and output accurate positions of objects in both modalities. To fuse misaligned object features accurately, we propose a Decoupled Position Multispectral Cross-attention module that adaptively samples and aggregates multispectral complementary features with the constraint of infrared and visible reference positions. Additionally, we design a query-decoupled Multispectral Decoder structure to address the optimization gap among the three kinds of object information in our task and propose a Decoupled Position Contrastive DeNosing Training strategy to enhance the DPDETR's ability to learn decoupled positions. Experiments on DroneVehicle and KAIST datasets demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DPDETR.
Read more8/13/2024
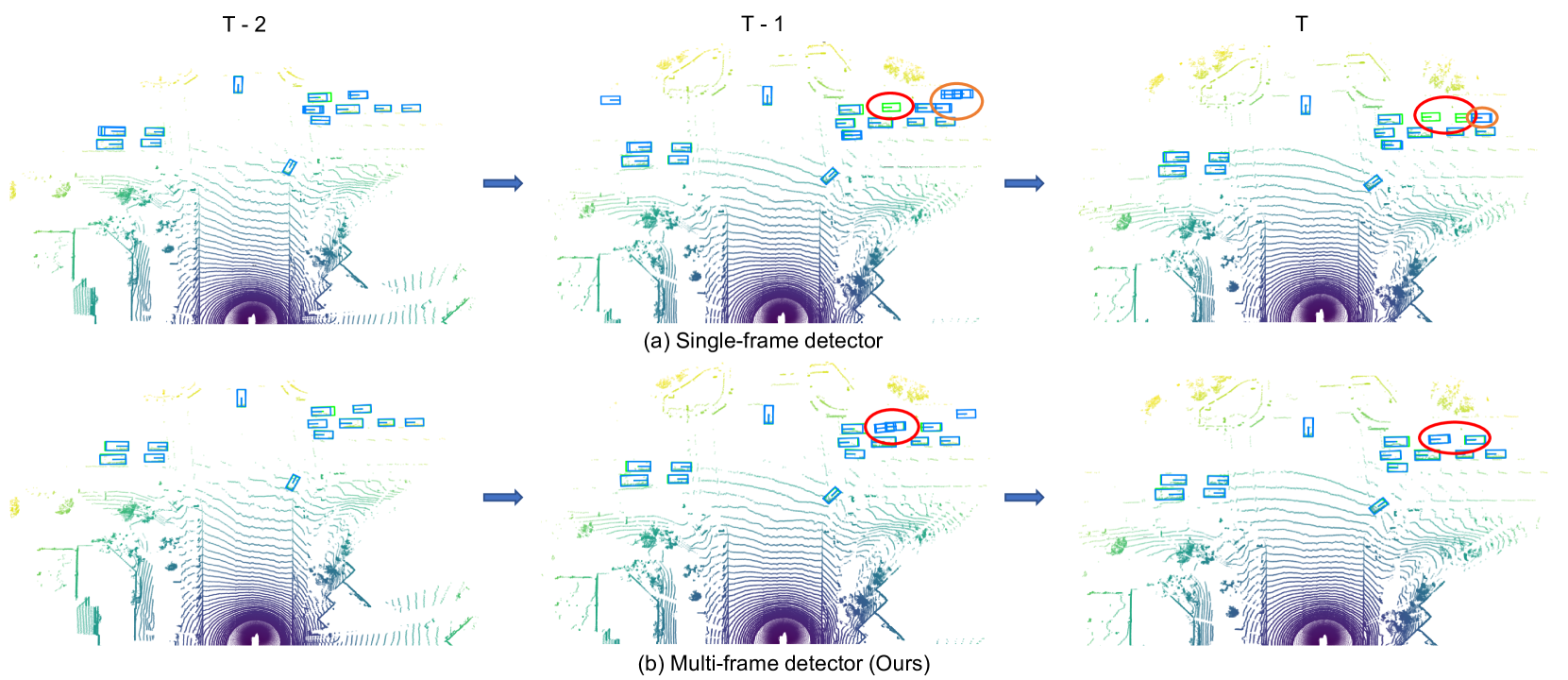
0
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024