Diffusion Policy Policy Optimization

0
Sign in to get full access
Overview
- This paper introduces a novel policy optimization algorithm called Diffusion Policy Policy Optimization (DPPO) for learning complex behaviors from scratch.
- DPPO combines ideas from diffusion models and reinforcement learning to enable sample-efficient exploration and learning of diverse behaviors.
- The authors demonstrate DPPO on several challenging robotic control tasks, showing it can learn complex multi-modal behaviors more efficiently than prior methods.
Plain English Explanation
The research paper presents a new approach for training artificial intelligence (AI) systems, called Diffusion Policy Policy Optimization (DPPO), that can learn complex behaviors more efficiently than previous methods. The key insight is to combine two powerful AI techniques - diffusion models and reinforcement learning.
Diffusion models are a type of generative AI that can create diverse and realistic outputs, like images or audio, by learning the natural "diffusion" process of how data is generated. Reinforcement learning, on the other hand, is a way of training AI systems to take actions that maximize some reward signal, like winning a game.
By blending these two approaches, DPPO is able to learn complex multi-modal behaviors more effectively. The diffusion aspect helps the AI system explore a wide range of possible behaviors, while the reinforcement learning component allows it to zero in on the most rewarding ones.
The researchers demonstrate DPPO on several challenging robotic control tasks, like getting a robot to walk in a natural way or controlling a virtual character. They show that DPPO can learn these complex behaviors much more efficiently than previous reinforcement learning methods, which struggle to explore the full space of possibilities.
Technical Explanation
The core innovation of the Diffusion Policy Policy Optimization (DPPO) algorithm is the combination of diffusion models and reinforcement learning for policy optimization. Diffusion models are a type of generative model that learn to gradually "diffuse" or transform simple noise into complex, realistic data distributions. By leveraging this diffusion process, DPPO can efficiently explore a wide range of possible behaviors during the reinforcement learning process.
The DPPO algorithm works as follows:
- The policy network (which maps observations to actions) is initialized with random weights.
- Noise is gradually "diffused" through the policy network, generating a diverse set of candidate behaviors.
- These candidate behaviors are then evaluated using the reinforcement learning reward signal, and the policy network is updated to increase the likelihood of the most rewarding behaviors.
- The process then repeats, with the policy network gradually refining its behavior through the interplay of diffusion and reinforcement learning.
The authors demonstrate DPPO on several challenging robotic control tasks, including locomotion, character animation, and multi-modal behavior learning. Across these tasks, DPPO is shown to learn complex behaviors more efficiently than prior reinforcement learning approaches, which struggle to explore the full space of possibilities.
Critical Analysis
The paper provides a compelling demonstration of the benefits of combining diffusion models and reinforcement learning for policy optimization. By leveraging the exploration capabilities of diffusion, DPPO is able to learn diverse and complex behaviors more efficiently than traditional reinforcement learning methods.
However, the paper does not address several potential limitations and areas for further research. For example, the authors do not discuss the computational and memory requirements of DPPO, which could be significant due to the need to train both a diffusion model and a policy network. Additionally, the paper does not explore the generalization capabilities of the learned policies, or how DPPO might perform on tasks with sparse or delayed rewards.
Further research could also investigate ways to integrate DPPO with other reinforcement learning techniques, such as hierarchical or multi-task learning, to further enhance its sample efficiency and expressive power. Exploring the application of DPPO to other domains beyond robotics, such as game AI or virtual character control, could also yield interesting insights.
Conclusion
The Diffusion Policy Policy Optimization (DPPO) algorithm presented in this paper represents an exciting advancement in the field of reinforcement learning, combining the exploration capabilities of diffusion models with the reward-driven optimization of traditional RL. By enabling more efficient learning of complex, multi-modal behaviors, DPPO has the potential to significantly enhance the capabilities of autonomous systems and open up new applications in robotics, animation, and beyond.
As the authors demonstrate, DPPO can outperform prior RL methods on challenging control tasks, suggesting it could be a valuable tool for training AI systems to tackle a wide range of real-world challenges. While further research is needed to address potential limitations, DPPO represents an important step forward in the quest to develop more capable and adaptable artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
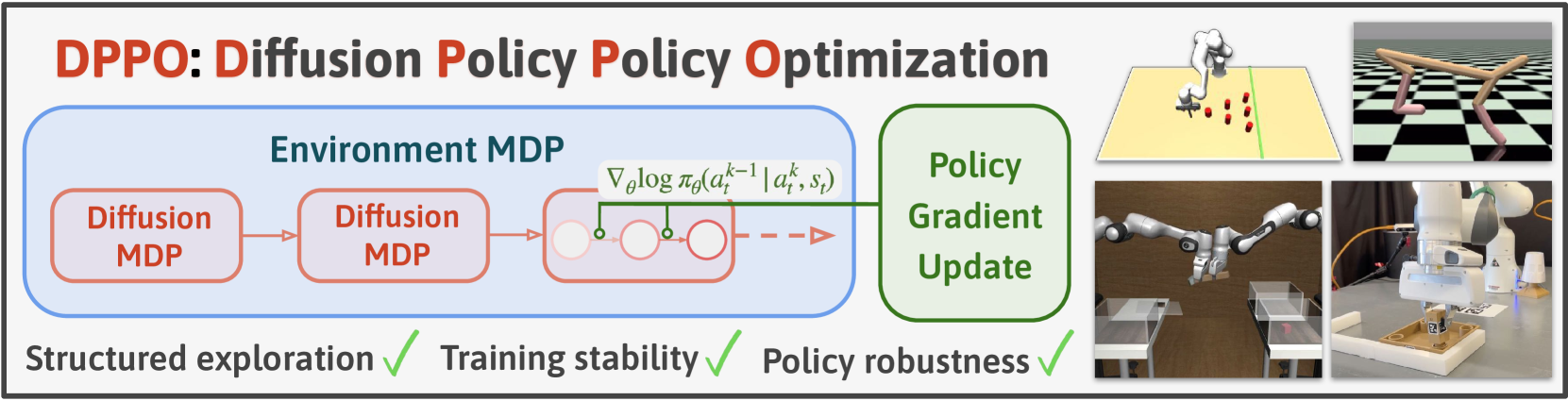
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024
🏅
0
Enhancing Sample Efficiency and Exploration in Reinforcement Learning through the Integration of Diffusion Models and Proximal Policy Optimization
Gao Tianci, Dmitriev D. Dmitry, Konstantin A. Neusypin, Yang Bo, Rao Shengren
Recent advancements in reinforcement learning (RL) have been fueled by large-scale data and deep neural networks, particularly for high-dimensional and complex tasks. Online RL methods like Proximal Policy Optimization (PPO) are effective in dynamic scenarios but require substantial real-time data, posing challenges in resource-constrained or slow simulation environments. Offline RL addresses this by pre-learning policies from large datasets, though its success depends on the quality and diversity of the data. This work proposes a framework that enhances PPO algorithms by incorporating a diffusion model to generate high-quality virtual trajectories for offline datasets. This approach improves exploration and sample efficiency, leading to significant gains in cumulative rewards, convergence speed, and strategy stability in complex tasks. Our contributions are threefold: we explore the potential of diffusion models in RL, particularly for offline datasets, extend the application of online RL to offline environments, and experimentally validate the performance improvements of PPO with diffusion models. These findings provide new insights and methods for applying RL to high-dimensional, complex tasks. Finally, we open-source our code at https://github.com/TianciGao/DiffPPO
Read more9/17/2024

0
Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki
Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
Read more6/4/2024

0
DPO: Differential reinforcement learning with application to optimal configuration search
Chandrajit Bajaj, Minh Nguyen
Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with the best current theoretical derivation. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems with continuous state and action spaces, and which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
Read more8/14/2024