DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models
2403.10081
0
0
Abstract
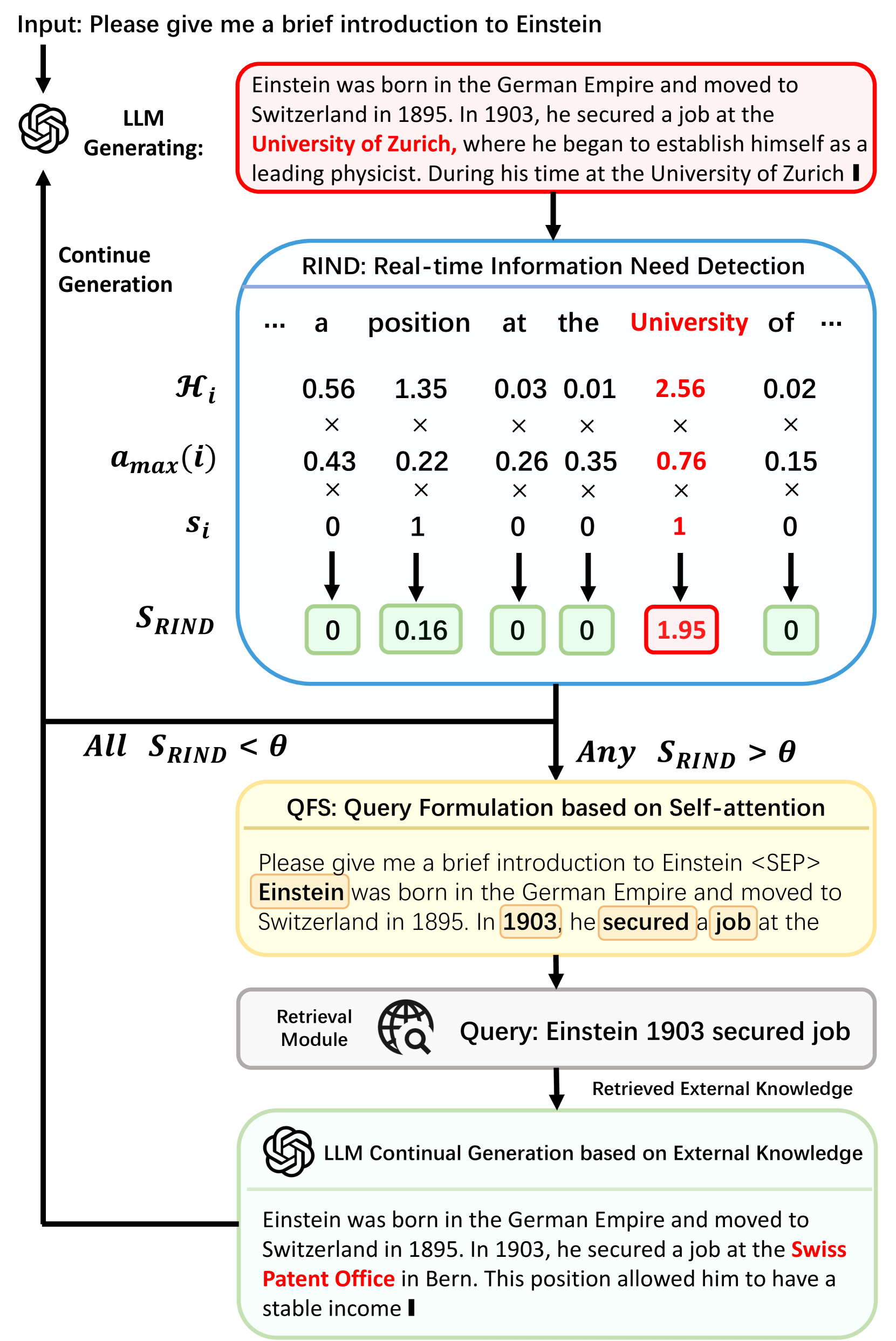
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the retrieval module (deciding when to retrieve) and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods fall short in both aspects. Firstly, the strategies for deciding when to retrieve often rely on static rules. Moreover, the strategies for deciding what to retrieve typically limit themselves to the LLM's most recent sentence or the last few tokens, while the LLM's real-time information needs may span across the entire context. To overcome these limitations, we introduce a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation based on the real-time Information Needs of LLMs. Our framework is specifically designed to make decisions on when and what to retrieve based on the LLM's real-time information needs during the text generation process. We evaluate DRAGIN along with existing methods comprehensively over 4 knowledge-intensive generation datasets. Experimental results show that DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of our method. We have open-sourced all the code, data, and models in GitHub: https://github.com/oneal2000/DRAGIN/tree/main
Create account to get full access
Overview
- The paper introduces DRAGIN, a system that dynamically retrieves information from external sources to augment the generation capabilities of large language models (LLMs) in real-time.
- DRAGIN addresses the information needs of LLMs by selectively retrieving relevant information from the web or other sources, rather than relying solely on the model's own knowledge.
- The system aims to improve the accuracy, coherence, and usefulness of LLM-generated outputs by providing timely and relevant supplementary information.
Plain English Explanation
DRAGIN is a new system that helps large language models (LLMs) like GPT-3 or BERT get better at generating useful text. LLMs are powerful, but they don't always have all the information they need to answer questions or write about a topic.
DRAGIN solves this by dynamically retrieving relevant information from the internet or other sources and adding it to the LLM's output. This allows the LLM to generate more accurate, coherent, and helpful responses, because it has access to timely and relevant facts and details.
For example, if you asked an LLM to write about the history of the Eiffel Tower, DRAGIN would automatically find and incorporate information from reliable online sources to enrich the LLM's response with key dates, facts, and context about the famous landmark. [Link to EMPOWERING LARGE LANGUAGE MODELS TO SET UP...]
This approach is different from previous [Link to IMPROVING RETRIEVAL-RAG BASED QUESTION ANSWERING MODELS] systems that only retrieve information once, before the LLM generates its output. DRAGIN continuously monitors the LLM's information needs and retrieves new data as needed, in real-time.
Technical Explanation
DRAGIN works by integrating a dynamic retrieval module with a large language model. As the LLM is generating text, DRAGIN continuously assesses its information needs and queries external sources, such as the web or structured databases, to find relevant supplementary information.
This retrieved information is then seamlessly incorporated into the LLM's output, enhancing the final result. DRAGIN uses advanced natural language processing and information retrieval techniques to efficiently identify and extract the most relevant content. [Link to SURVEY OF RAG MEETS LLMS TOWARDS RETRIEVAL AUGMENTED...]
The authors evaluate DRAGIN on a range of language tasks, including question answering, text summarization, and open-ended generation. Their results show that DRAGIN consistently outperforms LLMs that do not have access to dynamic retrieval, as well as previous [Link to IRAG: INCREMENTAL RETRIEVAL-AUGMENTED GENERATION SYSTEM FOR VIDEOS] retrieval-augmented generation approaches.
Critical Analysis
The DRAGIN paper makes a compelling case for the benefits of dynamically retrieving information to enhance large language models. The authors provide thorough experiments and analysis to demonstrate the system's effectiveness across several important NLP tasks.
However, the paper does not extensively discuss potential limitations or drawbacks of the DRAGIN approach. For example, the reliance on external data sources could introduce biases or inaccuracies if the retrieved information is of poor quality or lacks context. Additionally, the computational overhead of the continuous retrieval process may impact the efficiency and latency of the language model.
Further research could explore ways to mitigate these issues, such as by developing more robust retrieval mechanisms or incorporating quality control measures. It would also be valuable to investigate how DRAGIN performs on specialized or domain-specific tasks, where the availability and relevance of external information may differ.
Overall, the DRAGIN paper presents an innovative and promising approach to improving the capabilities of large language models. By dynamically supplementing their knowledge, the system has the potential to make LLMs more reliable, informative, and useful in a wide range of real-world applications.
Conclusion
The DRAGIN system introduced in this paper represents a significant advancement in the field of retrieval-augmented generation for large language models. By continuously monitoring the information needs of LLMs and dynamically retrieving relevant supplementary data, DRAGIN is able to generate more accurate, coherent, and useful outputs across a variety of language tasks.
The authors' thorough experimentation and analysis demonstrate the effectiveness of this approach, which has the potential to enhance the capabilities of LLMs and enable them to better serve the real-world information needs of users. As large language models continue to play an increasingly prominent role in various applications, systems like DRAGIN will be crucial in ensuring their outputs are well-informed, reliable, and contextually appropriate.
Further research and development in this area could lead to even more sophisticated retrieval-augmented generation techniques, ultimately driving progress in natural language processing and strengthening the practical utility of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
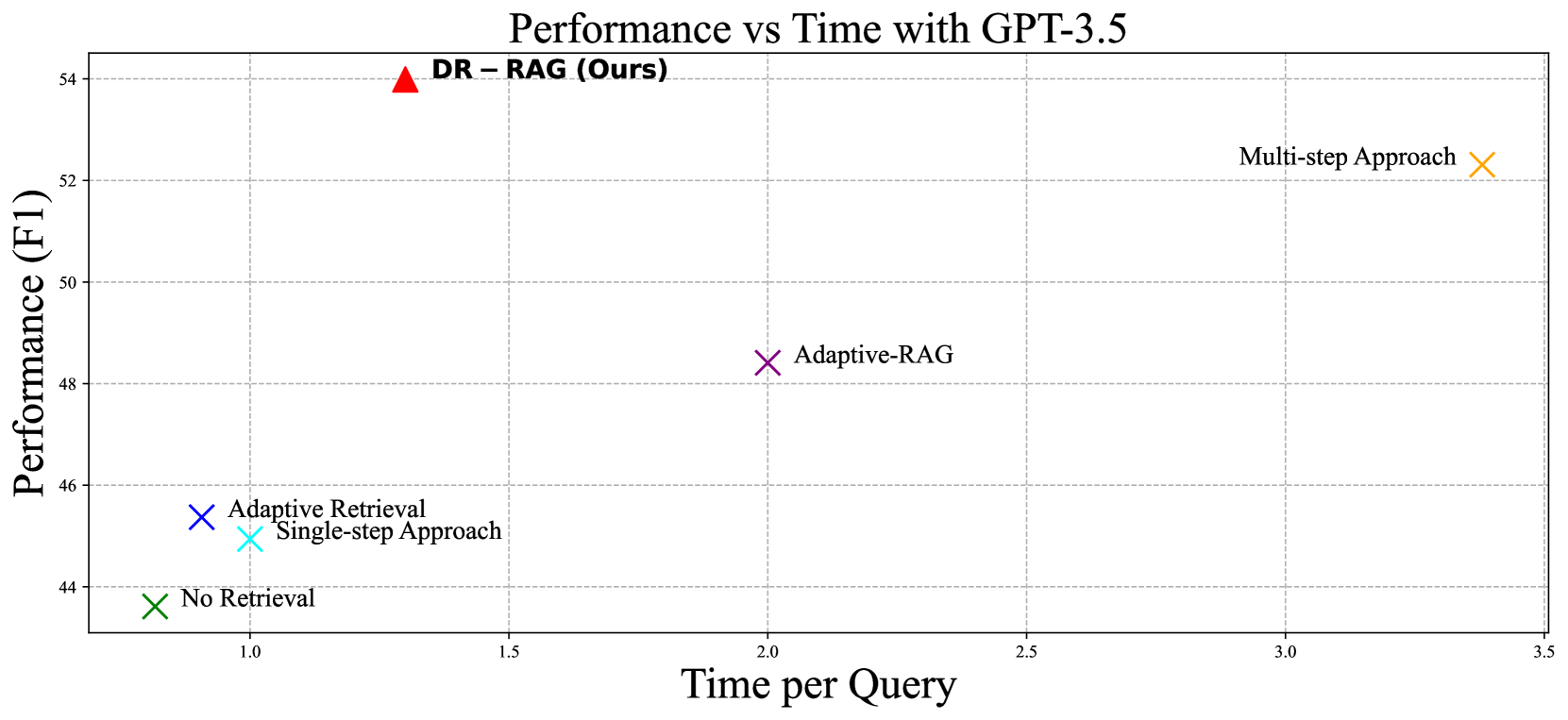
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024

R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Fuda Ye, Shuangyin Li, Yongqi Zhang, Lei Chen
0
0
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
6/21/2024