DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level

0

Sign in to get full access
Overview
- This research paper proposes a novel approach called DRE (Data-level Recommendation Explanation) for generating explanations for recommendations made by large language models.
- The key idea is to align large language models at the data level, allowing them to generate explanations that are directly grounded in the recommendation data.
- The authors demonstrate the effectiveness of DRE on various recommendation tasks and show that it outperforms existing explanation methods.
Plain English Explanation
Recommendation systems are algorithms that suggest products, services, or content that users might be interested in. However, these systems are often like black boxes - it's not always clear why they made a particular recommendation. The DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level research aims to make these recommendations more transparent by generating explanations that are directly tied to the data the recommendation is based on.
The core insight is that large language models, which are powerful AI systems trained on vast amounts of text data, can be used to generate these explanations. However, typically these language models are not well-aligned with the specific recommendation data. The DRE approach solves this by aligning the language model with the recommendation data at a deep, "data-level" rather than just on the surface. This allows the language model to generate explanations that are grounded in the actual reasons behind the recommendation.
For example, if a recommendation system suggests a certain product, the DRE approach can generate an explanation like "We recommend this product because it has similar features to other products you have purchased and reviewed positively in the past." This explanation is directly tied to the user's historical data, rather than just generic information about the product.
The researchers show that this DRE approach outperforms other explanation methods across a variety of recommendation tasks. This suggests that aligning large language models with recommendation data at a deep level can be a powerful way to make these systems more transparent and trustworthy.
Technical Explanation
The DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level paper proposes a novel framework called DRE (Data-level Recommendation Explanation) for generating explanations for recommendations made by large language models.
The key innovation is the idea of aligning large language models with the specific data used for a recommendation, rather than just using the language model to generate generic explanations. This "data-level alignment" is achieved through a multi-task learning approach, where the language model is trained not only on the standard language modeling objective, but also on predicting attributes of the recommendation data.
For example, in a product recommendation scenario, the language model would be trained to not only generate fluent text, but also predict product features, user preferences, and other relevant data points that underlie the recommendation. This allows the language model to generate explanations that are grounded in the actual reasons behind the recommendation.
The authors demonstrate the effectiveness of DRE on several recommendation tasks, including movie, book, and job recommendations. They show that DRE outperforms existing state-of-the-art explanation methods in terms of both the quality and faithfulness of the generated explanations.
One key insight from the paper is that this data-level alignment is crucial for generating high-quality explanations. Simply using a language model to generate text about a recommendation, without aligning it to the underlying data, results in explanations that are generic and not directly linked to the reasons for the recommendation.
Overall, the DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level paper presents an innovative approach to making recommendation systems more transparent and trustworthy by leveraging the power of large language models in a novel way.
Critical Analysis
The DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level paper presents a compelling approach to generating high-quality explanations for recommendations made by large language models. The key idea of aligning the language model with the underlying recommendation data is a novel and promising direction.
One potential limitation of the approach is the complexity of the multi-task training process, which involves jointly optimizing the language modeling objective and the recommendation data prediction tasks. This could make the training process computationally expensive and potentially unstable. The authors do not provide a detailed analysis of the training dynamics and convergence properties of their approach.
Additionally, the paper focuses on relatively standard recommendation tasks, such as movie, book, and job recommendations. It would be interesting to see how well the DRE approach generalizes to more complex or domain-specific recommendation scenarios, where the underlying data may be more heterogeneous and harder to align with a language model.
Another area for further research could be exploring ways to make the data-level alignment more interpretable and transparent to users. While the DRE-generated explanations are more grounded in the data than traditional approaches, they may still be opaque to end-users who are not familiar with the intricacies of the model.
Overall, the DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level paper presents a promising direction for improving the transparency and trustworthiness of recommendation systems. The authors have demonstrated the effectiveness of their approach, and further research in this area could lead to even more robust and user-friendly explanation generation techniques.
Conclusion
The DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level research paper introduces a novel approach called DRE for generating high-quality explanations for recommendations made by large language models. The key innovation is the idea of aligning the language model with the underlying recommendation data at a deep, "data-level" rather than just on the surface.
This data-level alignment allows the language model to generate explanations that are directly grounded in the reasons behind the recommendation, rather than just generic information. The authors demonstrate the effectiveness of DRE on various recommendation tasks and show that it outperforms existing explanation methods.
While the paper presents a compelling approach, there are also some potential limitations and areas for further research, such as the complexity of the training process, the generalization to more diverse recommendation scenarios, and the interpretability of the generated explanations.
Overall, the DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level paper represents an important step towards making recommendation systems more transparent and trustworthy by leveraging the power of large language models in a novel way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level
Shen Gao, Yifan Wang, Jiabao Fang, Lisi Chen, Peng Han, Shuo Shang
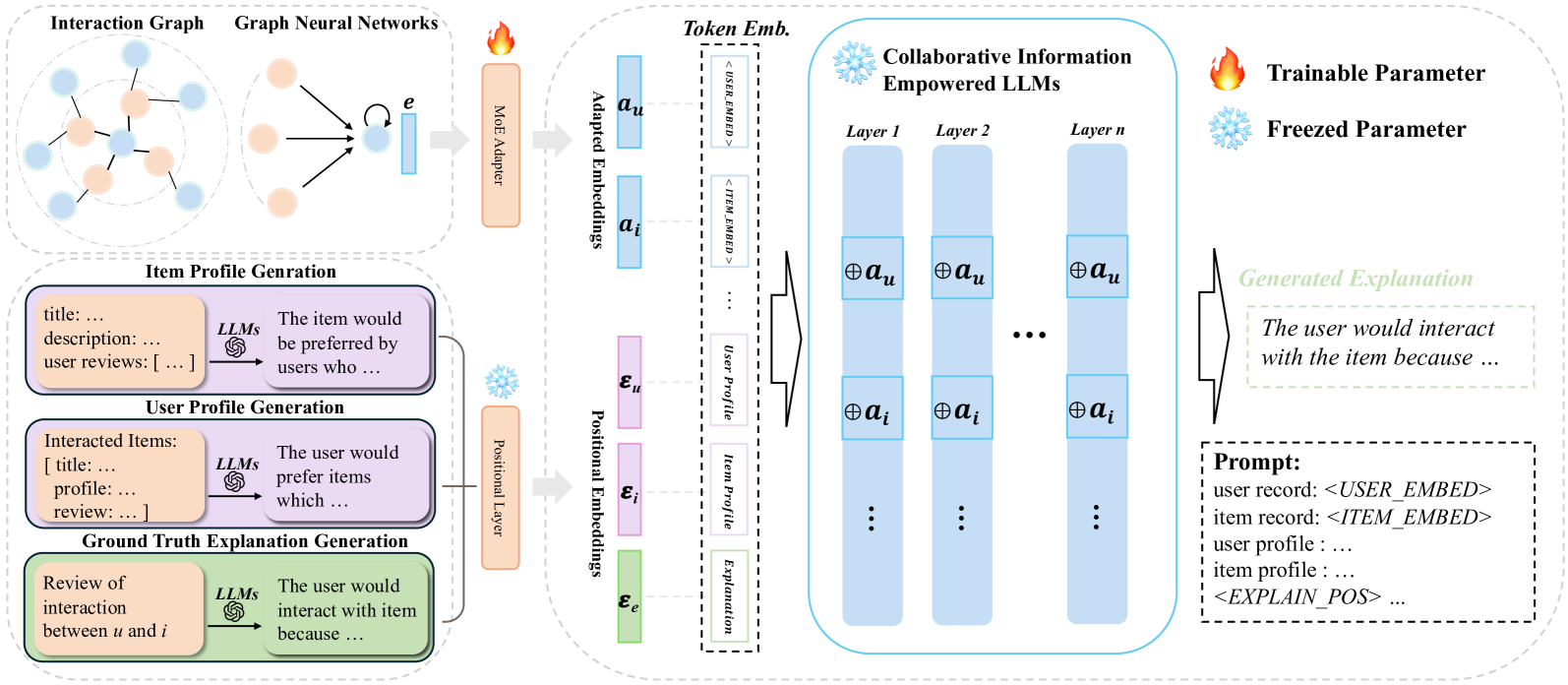
Recommendation systems play a crucial role in various domains, suggesting items based on user behavior.However, the lack of transparency in presenting recommendations can lead to user confusion. In this paper, we introduce Data-level Recommendation Explanation (DRE), a non-intrusive explanation framework for black-box recommendation models.Different from existing methods, DRE does not require any intermediary representations of the recommendation model or latent alignment training, mitigating potential performance issues.We propose a data-level alignment method, leveraging large language models to reason relationships between user data and recommended items.Additionally, we address the challenge of enriching the details of the explanation by introducing target-aware user preference distillation, utilizing item reviews. Experimental results on benchmark datasets demonstrate the effectiveness of the DRE in providing accurate and user-centric explanations, enhancing user engagement with recommended item.
Read more4/10/2024
0
XRec: Large Language Models for Explainable Recommendation
Qiyao Ma, Xubin Ren, Chao Huang
Recommender systems help users navigate information overload by providing personalized recommendations aligned with their preferences. Collaborative Filtering (CF) is a widely adopted approach, but while advanced techniques like graph neural networks (GNNs) and self-supervised learning (SSL) have enhanced CF models for better user representations, they often lack the ability to provide explanations for the recommended items. Explainable recommendations aim to address this gap by offering transparency and insights into the recommendation decision-making process, enhancing users' understanding. This work leverages the language capabilities of Large Language Models (LLMs) to push the boundaries of explainable recommender systems. We introduce a model-agnostic framework called XRec, which enables LLMs to provide comprehensive explanations for user behaviors in recommender systems. By integrating collaborative signals and designing a lightweight collaborative adaptor, the framework empowers LLMs to understand complex patterns in user-item interactions and gain a deeper understanding of user preferences. Our extensive experiments demonstrate the effectiveness of XRec, showcasing its ability to generate comprehensive and meaningful explanations that outperform baseline approaches in explainable recommender systems. We open-source our model implementation at https://github.com/HKUDS/XRec.
Read more9/24/2024
💬
0
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models
Yuxuan Lei, Jianxun Lian, Jing Yao, Xu Huang, Defu Lian, Xing Xie
Recommender systems are widely used in online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often function as a black box, making them less transparent and reliable for both users and developers. Recently, large language models (LLMs) have demonstrated remarkable intelligence in understanding, reasoning, and instruction following. This paper presents the initial exploration of using LLMs as surrogate models to explaining black-box recommender models. The primary concept involves training LLMs to comprehend and emulate the behavior of target recommender models. By leveraging LLMs' own extensive world knowledge and multi-step reasoning abilities, these aligned LLMs can serve as advanced surrogates, capable of reasoning about observations. Moreover, employing natural language as an interface allows for the creation of customizable explanations that can be adapted to individual user preferences. To facilitate an effective alignment, we introduce three methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to mimic the target model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces. Comprehensive experiments conducted on three public datasets show that our approach yields promising results in understanding and mimicking target models, producing high-quality, high-fidelity, and distinct explanations. Our code is available at https://github.com/microsoft/RecAI.
Read more6/26/2024
0
LANE: Logic Alignment of Non-tuning Large Language Models and Online Recommendation Systems for Explainable Reason Generation
Hongke Zhao, Songming Zheng, Likang Wu, Bowen Yu, Jing Wang
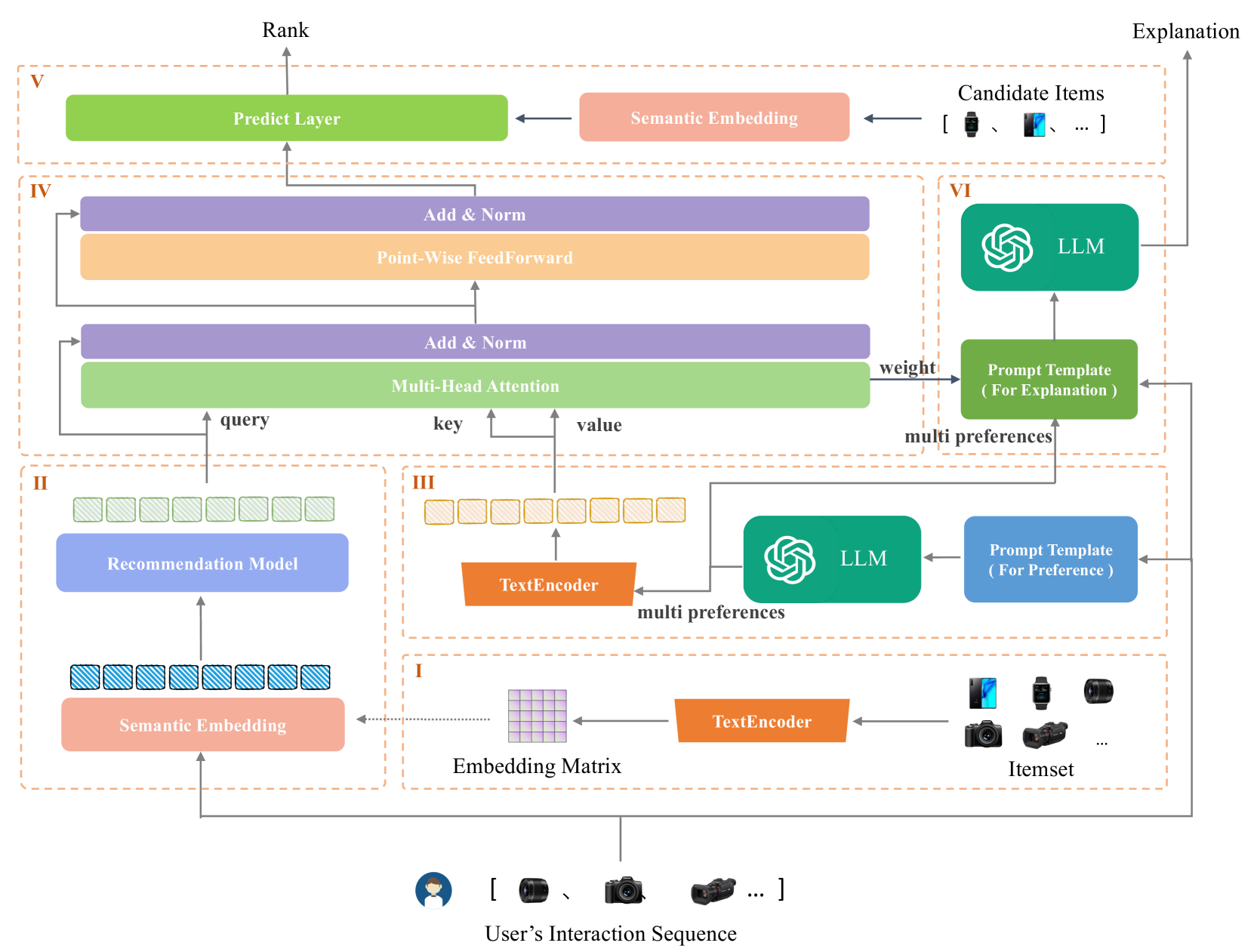
The explainability of recommendation systems is crucial for enhancing user trust and satisfaction. Leveraging large language models (LLMs) offers new opportunities for comprehensive recommendation logic generation. However, in existing related studies, fine-tuning LLM models for recommendation tasks incurs high computational costs and alignment issues with existing systems, limiting the application potential of proven proprietary/closed-source LLM models, such as GPT-4. In this work, our proposed effective strategy LANE aligns LLMs with online recommendation systems without additional LLMs tuning, reducing costs and improving explainability. This innovative approach addresses key challenges in integrating language models with recommendation systems while fully utilizing the capabilities of powerful proprietary models. Specifically, our strategy operates through several key components: semantic embedding, user multi-preference extraction using zero-shot prompting, semantic alignment, and explainable recommendation generation using Chain of Thought (CoT) prompting. By embedding item titles instead of IDs and utilizing multi-head attention mechanisms, our approach aligns the semantic features of user preferences with those of candidate items, ensuring coherent and user-aligned recommendations. Sufficient experimental results including performance comparison, questionnaire voting, and visualization cases prove that our method can not only ensure recommendation performance, but also provide easy-to-understand and reasonable recommendation logic.
Read more7/4/2024