Latent Distance Guided Alignment Training for Large Language Models
2404.06390
0
0
🏋️
Abstract
Ensuring alignment with human preferences is a crucial characteristic of large language models (LLMs). Presently, the primary alignment methods, RLHF and DPO, require extensive human annotation, which is expensive despite their efficacy. The significant expenses associated with current alignment techniques motivate researchers to investigate the development of annotation-free alignment training methods. In pursuit of improved alignment without relying on external annotation, we introduce Latent Distance Guided Alignment Training (LD-Align). This approach seeks to align the model with a high-quality supervised fine-tune dataset using guidance from a latent space. The latent space is generated through sample reconstruction, akin to auto-encoding. Consequently, we utilize the distance between sample pairs in the latent space to guide DPO-based alignment training. Extensive experimentation and evaluation show the efficacy of our proposed method in achieving notable alignment.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel training method called "Latent Distance Guided Alignment Training" (LDGAT) for aligning large language models (LLMs) with human preferences.
- LDGAT aims to address the challenge of training LLMs to generate text that is coherent, relevant, and aligned with human values, without sacrificing the models' broad capabilities.
- The key idea behind LDGAT is to use a latent distance metric to guide the model's training, encouraging it to generate text that is semantically close to the target output while maintaining its overall fluency and coherence.
Plain English Explanation
Aligning AI Models with Human Preferences Training large language models (LLMs) to generate text that is not only grammatically correct, but also aligned with human values and preferences, is a significant challenge. The paper introduces a new training method called "Latent Distance Guided Alignment Training" (LDGAT) that aims to address this challenge.
The core idea behind LDGAT is to use a "latent distance" metric to guide the model's training. This means the model is encouraged to generate text that is semantically similar to the desired output, without compromising the overall fluency and coherence of the generated text. In other words, the model learns to produce text that is both relevant and aligned with human preferences.
This is an important advancement, as it allows LLMs to maintain their broad capabilities while also being more closely aligned with human values. This builds on previous research in the field, such as the work on understanding learning dynamics for alignment with human feedback, aligning language models with tailored synthetic data, and RLHF practices for aligning large language models.
Technical Explanation
The key innovation of the LDGAT method is the use of a latent distance metric to guide the model's training. Specifically, the authors introduce a "latent distance loss" that encourages the model to generate text that is semantically close to the target output, as measured in the model's own latent representation space.
This latent distance loss is combined with the standard language modeling objective, which ensures the generated text maintains fluency and coherence. The authors demonstrate that this approach leads to significant improvements in the alignment of the generated text with human preferences, without compromising the model's overall performance on a range of language tasks.
The authors evaluate LDGAT on several benchmark datasets and tasks, including direct preference optimization for video and large multimodal models and speech alignment with human preferences. The results show that LDGAT outperforms previous alignment approaches, while also maintaining the model's broad capabilities.
Critical Analysis
The LDGAT method represents an important step forward in the field of aligning large language models with human preferences. By leveraging the model's own latent space, the approach is able to achieve strong alignment without sacrificing the model's overall fluency and coherence.
However, the paper acknowledges several limitations and areas for further research. For example, the authors note that the latent distance metric may not capture all aspects of human preference, and that additional techniques may be needed to fully align the model with complex human values.
Additionally, the paper does not address potential biases or unintended consequences that may arise from the alignment process. Further research is needed to ensure that LDGAT and similar techniques are developed and deployed responsibly, with careful consideration of their societal impact.
Conclusion
The LDGAT method introduced in this paper represents an important advancement in the field of aligning large language models with human preferences. By using a latent distance metric to guide the training process, the approach is able to produce text that is both coherent and aligned with human values, without sacrificing the model's broad capabilities.
While the paper highlights the potential of this technique, it also underscores the need for continued research and development in this area. As LLMs become increasingly powerful and ubiquitous, it is crucial that they are trained and deployed in a way that is aligned with human values and promotes the greater good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024

Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
0
0
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
4/16/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Amir Saeidi, Shivanshu Verma, Chitta Baral
0
0
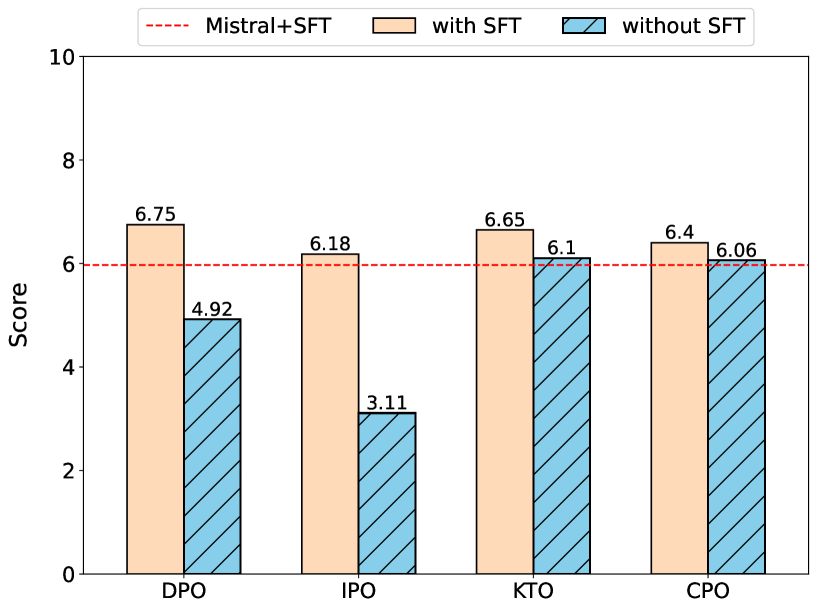
Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
4/24/2024