DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion

0
Sign in to get full access
Overview
- Introduces a new method called "DreamMover" for image interpolation with large motion
- Leverages the prior of diffusion models to generate in-between frames with semantic consistency
- Aims to improve upon existing methods for short-video generation and image editing
Plain English Explanation
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion presents a new technique for interpolating images with large motion. The key idea is to harness the powerful prior learned by diffusion models - a type of generative AI model - to generate realistic in-between frames that maintain semantic consistency.
Existing methods for tasks like short-video generation and image editing can struggle with large motions, often producing unrealistic or distorted results. DreamMover aims to address this by using the knowledge encoded in diffusion models to guide the interpolation process. This allows it to generate smooth, semantically coherent transitions even for dramatic changes between input images.
The paper demonstrates DreamMover's effectiveness on a range of benchmarks, showing that it outperforms prior approaches for large-motion image interpolation. This has implications for applications like video editing, animation, and visual effects, where smooth, realistic transitions are crucial.
Technical Explanation
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion proposes a new method for image interpolation that leverages the power of diffusion models. Diffusion models are a type of generative AI model that have shown impressive results in tasks like image synthesis and text-to-image generation.
The key insight behind DreamMover is that the powerful prior learned by diffusion models can be harnessed to guide the interpolation process, producing semantically consistent and visually realistic in-between frames. The authors design a novel architecture that integrates diffusion models with a motion-aware component, allowing it to handle large motions between input images.
Experiments on a range of benchmarks demonstrate that DreamMover outperforms prior approaches for image interpolation, especially in cases involving large motion. The authors attribute this to the model's ability to maintain semantic consistency by drawing on the strong prior learned by the diffusion component.
Critical Analysis
The paper presents a compelling approach to image interpolation, but there are a few potential limitations and areas for further research:
-
The authors focus primarily on evaluating DreamMover on static image interpolation tasks. It would be interesting to see how the method performs on video-to-video or animation-related applications, where the temporal consistency of the generated frames is crucial.
-
The paper does not provide a detailed analysis of the computational complexity or inference time of DreamMover compared to other methods. This information would be helpful for understanding the practical tradeoffs and potential deployment scenarios.
-
While the authors demonstrate semantic consistency in the generated frames, it would be valuable to further investigate the model's ability to preserve fine-grained details and handle challenging edge cases, such as occlusions or out-of-distribution motions.
Overall, DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion presents an innovative approach that leverages the power of diffusion models to address the challenging problem of large-motion image interpolation. The results are promising, and further research could explore the method's broader applications and limitations.
Conclusion
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion introduces a novel technique for image interpolation that harnesses the strong prior learned by diffusion models. By integrating diffusion models with a motion-aware component, the method is able to generate visually realistic and semantically consistent in-between frames, even for large motions between input images.
The paper demonstrates the effectiveness of DreamMover on a range of benchmarks, outperforming prior approaches. This has significant implications for applications like video editing, animation, and visual effects, where smooth, realistic transitions are crucial. While the method shows promise, further research is needed to explore its broader applications and potential limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion
Liao Shen, Tianqi Liu, Huiqiang Sun, Xinyi Ye, Baopu Li, Jianming Zhang, Zhiguo Cao
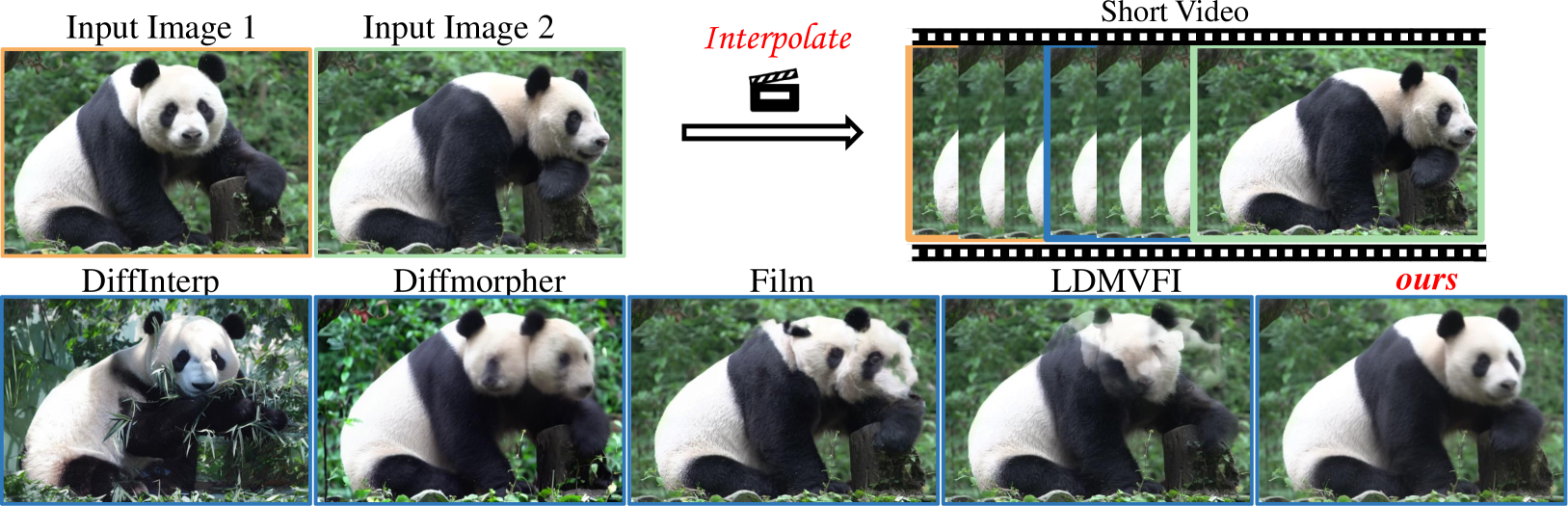
We study the problem of generating intermediate images from image pairs with large motion while maintaining semantic consistency. Due to the large motion, the intermediate semantic information may be absent in input images. Existing methods either limit to small motion or focus on topologically similar objects, leading to artifacts and inconsistency in the interpolation results. To overcome this challenge, we delve into pre-trained image diffusion models for their capabilities in semantic cognition and representations, ensuring consistent expression of the absent intermediate semantic representations with the input. To this end, we propose DreamMover, a novel image interpolation framework with three main components: 1) A natural flow estimator based on the diffusion model that can implicitly reason about the semantic correspondence between two images. 2) To avoid the loss of detailed information during fusion, our key insight is to fuse information in two parts, high-level space and low-level space. 3) To enhance the consistency between the generated images and input, we propose the self-attention concatenation and replacement approach. Lastly, we present a challenging benchmark dataset InterpBench to evaluate the semantic consistency of generated results. Extensive experiments demonstrate the effectiveness of our method. Our project is available at https://dreamm0ver.github.io .
Read more9/19/2024

0
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Xiaojuan Wang, Boyang Zhou, Brian Curless, Ira Kemelmacher-Shlizerman, Aleksander Holynski, Steven M. Seitz
We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Read more8/28/2024
0
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Zhilin Huang, Yijie Yu, Ling Yang, Chujun Qin, Bing Zheng, Xiawu Zheng, Zikun Zhou, Yaowei Wang, Wenming Yang
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Read more8/6/2024

0
Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Yuan-Fang Li, Cunjian Chen, Yu Qiao
Diffusion models have achieved great progress in image animation due to powerful generative capabilities. However, maintaining spatio-temporal consistency with detailed information from the input static image over time (e.g., style, background, and object of the input static image) and ensuring smoothness in animated video narratives guided by textual prompts still remains challenging. In this paper, we introduce Cinemo, a novel image animation approach towards achieving better motion controllability, as well as stronger temporal consistency and smoothness. In general, we propose three effective strategies at the training and inference stages of Cinemo to accomplish our goal. At the training stage, Cinemo focuses on learning the distribution of motion residuals, rather than directly predicting subsequent via a motion diffusion model. Additionally, a structural similarity index-based strategy is proposed to enable Cinemo to have better controllability of motion intensity. At the inference stage, a noise refinement technique based on discrete cosine transformation is introduced to mitigate sudden motion changes. Such three strategies enable Cinemo to produce highly consistent, smooth, and motion-controllable results. Compared to previous methods, Cinemo offers simpler and more precise user controllability. Extensive experiments against several state-of-the-art methods, including both commercial tools and research approaches, across multiple metrics, demonstrate the effectiveness and superiority of our proposed approach.
Read more7/24/2024