Motion-aware Latent Diffusion Models for Video Frame Interpolation
2404.13534
0
0
Abstract
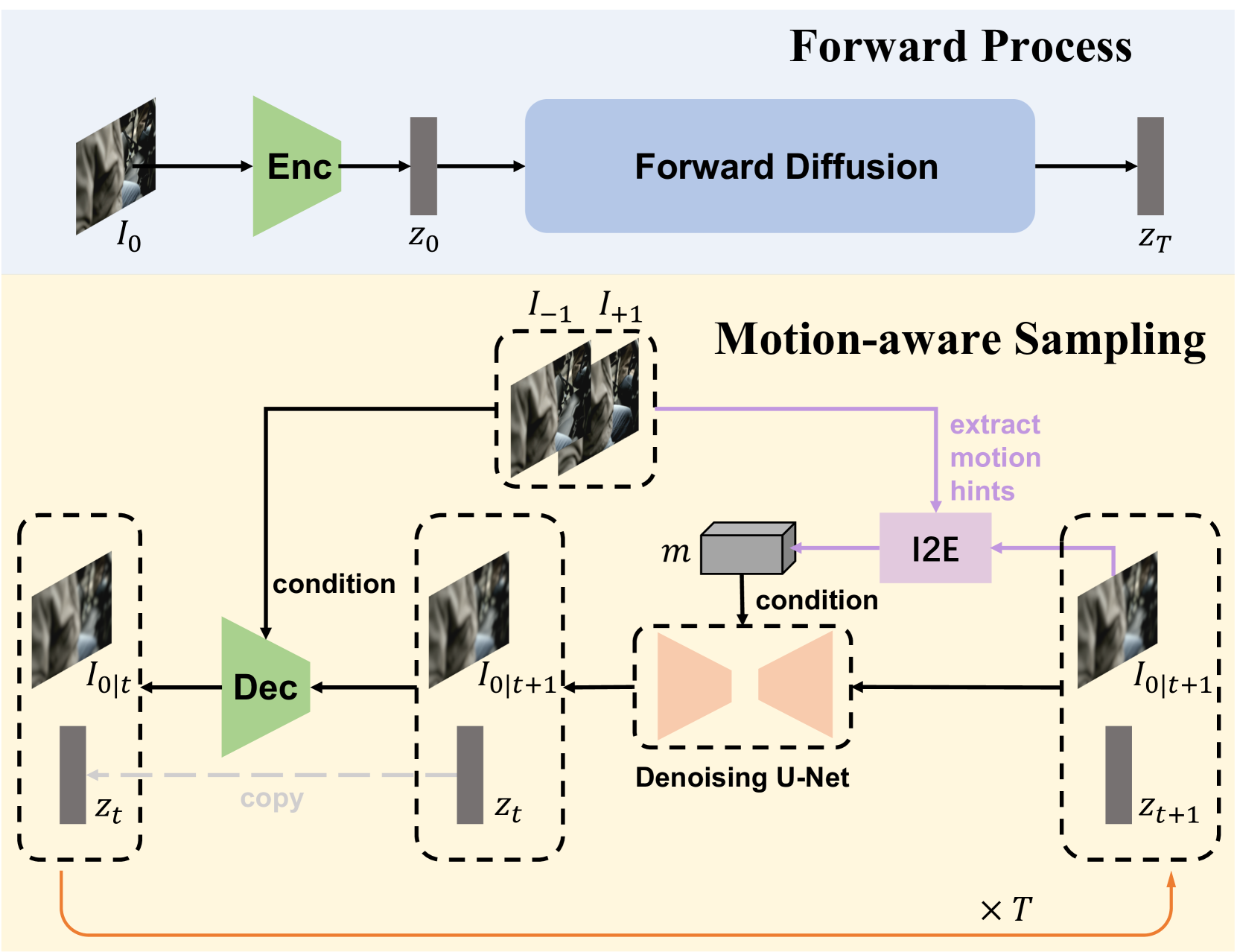
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Create account to get full access
Overview
- This paper proposes a motion-aware latent diffusion model for video frame interpolation, a technique that generates intermediate frames between existing frames to create smoother video playback.
- The model leverages a novel motion-aware latent diffusion architecture to capture and preserve motion information during the frame generation process.
- The authors demonstrate the effectiveness of their approach through extensive experiments, showing improvements over state-of-the-art video frame interpolation methods.
Plain English Explanation
Video frame interpolation is the process of generating new frames between existing ones to create a smoother video playback experience. This is particularly useful for high-speed or low-frame-rate videos, where the jumps between frames can be jarring.
The key challenge in video frame interpolation is to accurately capture and preserve the motion information between frames, as this is crucial for generating realistic-looking intermediate frames.
The researchers in this paper have developed a new model that uses a motion-aware latent diffusion architecture to address this challenge. Latent diffusion is a type of machine learning model that can generate new images by learning the underlying patterns in a dataset.
By incorporating motion awareness into the latent diffusion model, the researchers were able to better capture the movement and dynamics between video frames. This allowed their model to generate high-quality intermediate frames that smoothly connect the original frames, resulting in a more seamless and natural-looking video.
Through extensive testing, the researchers demonstrated that their motion-aware latent diffusion model outperforms other state-of-the-art video frame interpolation techniques, as measured by various image quality metrics. This suggests that their innovative approach to incorporating motion information is a significant advancement in the field of video frame interpolation.
Technical Explanation
The researchers propose a motion-aware latent diffusion model for video frame interpolation, which builds upon the success of diffusion models in generating high-quality images.
The key innovation is the introduction of a motion-aware module that is integrated into the latent diffusion architecture. This module learns to capture and preserve the motion information between video frames, which is crucial for generating realistic-looking intermediate frames.
The motion-aware module operates on the latent representations of the video frames, modeling the temporal dynamics and motion patterns. This allows the overall model to generate new frames that seamlessly connect the original frames, while preserving the essential motion characteristics.
To train and evaluate their model, the researchers conducted extensive experiments using various video datasets and compared their approach to state-of-the-art video frame interpolation methods. The results demonstrate that their motion-aware latent diffusion model consistently outperforms the competition in terms of objective image quality metrics and subjective human evaluations.
Critical Analysis
The researchers acknowledge several limitations and areas for future research in their paper:
- The current model is designed for generating intermediate video frames, and it may not be directly applicable to other video processing tasks, such as frame extrapolation or video super-resolution.
- The model's performance is still dependent on the quality of the input frames, and it may struggle with low-quality or highly distorted video inputs.
- The training and inference processes can be computationally intensive, which may limit the model's deployment in real-time or resource-constrained applications.
Furthermore, the paper does not delve into the potential ethical implications of their work, such as the use of video frame interpolation for deepfake generation or the impact on the visual effects industry.
Overall, the researchers have made a significant contribution to the field of video frame interpolation by introducing a novel motion-aware latent diffusion model. However, there are still opportunities for further research and development to address the identified limitations and explore the broader societal implications of this technology.
Conclusion
The proposed motion-aware latent diffusion model for video frame interpolation demonstrates a notable advancement in the field by effectively capturing and preserving motion information during the frame generation process. The researchers' extensive experiments show that their approach outperforms state-of-the-art methods, suggesting that the integration of motion awareness into latent diffusion architectures is a promising direction for improving video processing capabilities.
While the paper identifies some limitations and areas for future work, the core contribution of this research is the introduction of a novel and effective solution for generating high-quality intermediate frames in video, which has the potential to enhance the viewing experience for a wide range of applications, from entertainment to surveillance and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Frame Interpolation with Consecutive Brownian Bridge Diffusion
Zonglin Lyu, Ming Li, Jianbo Jiao, Chen Chen
0
0
Recent work in Video Frame Interpolation (VFI) tries to formulate VFI as a diffusion-based conditional image generation problem, synthesizing the intermediate frame given a random noise and neighboring frames. Due to the relatively high resolution of videos, Latent Diffusion Models (LDMs) are employed as the conditional generation model, where the autoencoder compresses images into latent representations for diffusion and then reconstructs images from these latent representations. Such a formulation poses a crucial challenge: VFI expects that the output is deterministically equal to the ground truth intermediate frame, but LDMs randomly generate a diverse set of different images when the model runs multiple times. The reason for the diverse generation is that the cumulative variance (variance accumulated at each step of generation) of generated latent representations in LDMs is large. This makes the sampling trajectory random, resulting in diverse rather than deterministic generations. To address this problem, we propose our unique solution: Frame Interpolation with Consecutive Brownian Bridge Diffusion. Specifically, we propose consecutive Brownian Bridge diffusion that takes a deterministic initial value as input, resulting in a much smaller cumulative variance of generated latent representations. Our experiments suggest that our method can improve together with the improvement of the autoencoder and achieve state-of-the-art performance in VFI, leaving strong potential for further enhancement.
6/12/2024
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Guangyang Wu, Xin Tao, Changlin Li, Wenyi Wang, Xiaohong Liu, Qingqing Zheng
0
0
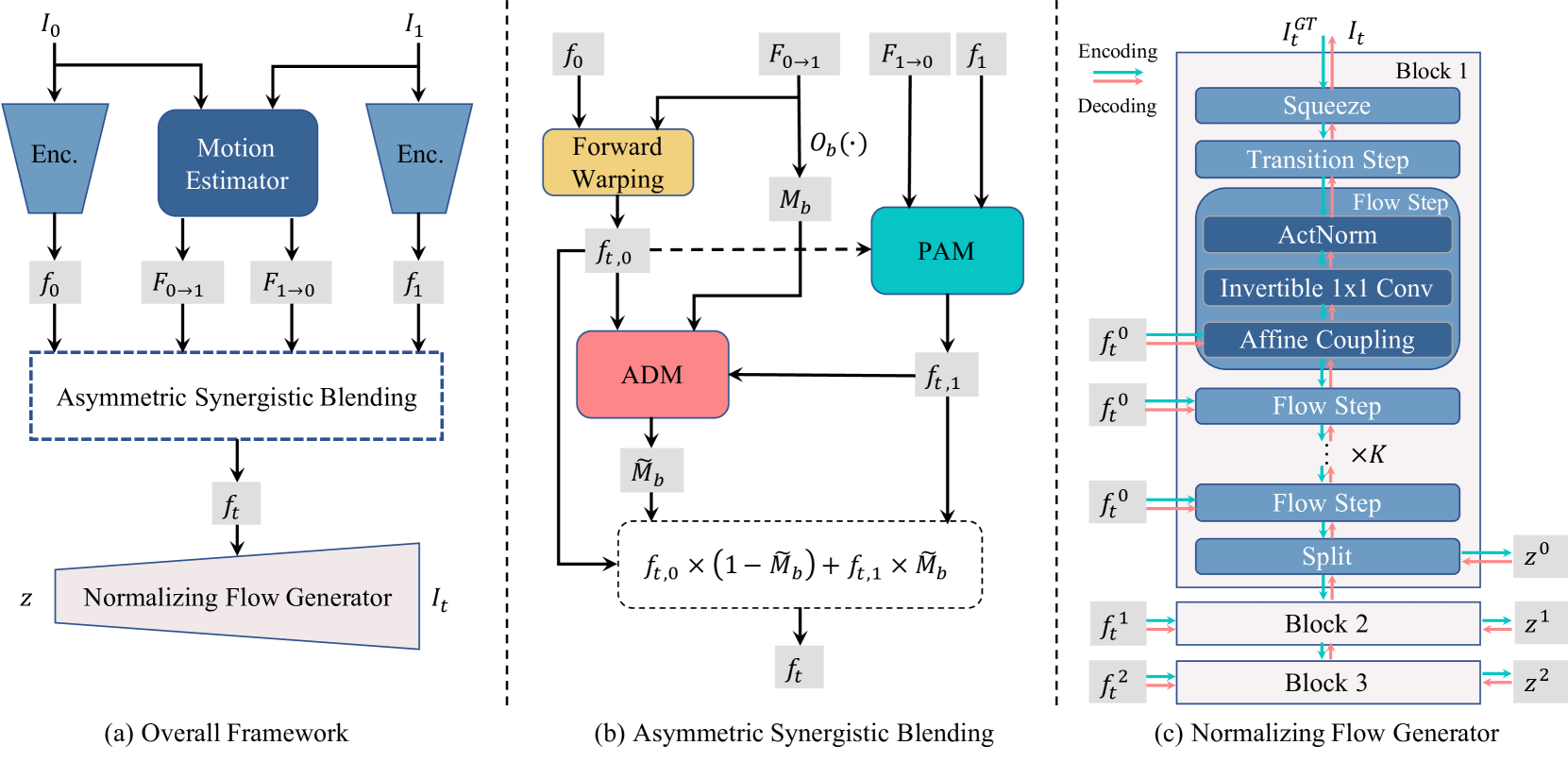
Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at url{https://github.com/mulns/PerVFI}
4/11/2024

Flexible Motion In-betweening with Diffusion Models
Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne
0
0
Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
5/27/2024
🏋️
Video Diffusion Models are Training-free Motion Interpreter and Controller
Zeqi Xiao, Yifan Zhou, Shuai Yang, Xingang Pan
0
0
Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
5/24/2024