Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation

0

Sign in to get full access
Overview
- This paper presents a novel method called "Generative Inbetweening" that adapts existing image-to-video models for the task of keyframe interpolation.
- Keyframe interpolation is the process of generating intermediate frames between two or more keyframes, which is an important task in animation and video editing.
- The proposed approach leverages the impressive capabilities of modern image-to-video models, such as I2V-Edit and Flexible Motion Betweening, to perform high-quality keyframe interpolation.
Plain English Explanation
The paper describes a way to use powerful AI models that can generate video from images to also generate in-between frames in an animation or video. This is called "keyframe interpolation" and is an important task in creating smooth, high-quality animations and videos.
The key insight is that these advanced image-to-video models, like I2V-Edit and Flexible Motion Betweening, can be adapted to generate the in-between frames, rather than relying on traditional interpolation methods. This allows for much more realistic and natural-looking in-between frames, improving the overall quality of the animation or video.
Technical Explanation
The paper proposes a Generative Inbetweening approach that adapts existing image-to-video models, such as I2V-Edit and Flexible Motion Betweening, to perform keyframe interpolation. Keyframe interpolation is the process of generating intermediate frames between two or more keyframes, which is a critical task in animation and video editing.
The key insight is that these advanced image-to-video models, trained on large datasets of video data, have learned powerful representations and generative capabilities that can be leveraged for the keyframe interpolation task. By adapting these models, the authors are able to generate high-quality in-between frames that capture the nuanced motion and appearance changes between keyframes, outperforming traditional interpolation methods.
The paper also explores motion-aware latent diffusion models (Motion-Aware Latent Diffusion Models) and zero-shot diffusion model adaptation (ZeroSMooth) as alternative approaches to keyframe interpolation, demonstrating the versatility and potential of the Generative Inbetweening framework.
Critical Analysis
The paper presents a promising approach to keyframe interpolation, leveraging the impressive capabilities of modern image-to-video models. However, the authors acknowledge several limitations and areas for further research:
-
Computational Complexity: The adapted image-to-video models may be computationally intensive, which could limit their practical application in real-time or resource-constrained environments.
-
Generalization Ability: The performance of the Generative Inbetweening approach may be dependent on the quality and diversity of the training data for the underlying image-to-video models. Further research is needed to understand the limits of generalization.
-
Evaluation Metrics: The paper primarily uses subjective human evaluation to assess the quality of the generated in-between frames. Developing more objective and comprehensive evaluation metrics could strengthen the research.
-
Artistic Control: While the Generative Inbetweening approach produces high-quality results, it may lack the fine-grained artistic control that some animators and video editors desire. Exploring ways to incorporate user input and guidance could be a valuable direction for future work.
Overall, the Generative Inbetweening method represents an exciting advancement in keyframe interpolation, leveraging the power of modern image-to-video models. The critical analysis highlights areas for further research and improvement, which could enhance the practical applicability and artistic control of the approach.
Conclusion
This paper presents a novel Generative Inbetweening method that adapts existing image-to-video models for the task of keyframe interpolation. By leveraging the impressive capabilities of these advanced models, the approach is able to generate high-quality in-between frames that capture the nuanced motion and appearance changes between keyframes, outperforming traditional interpolation methods.
The work demonstrates the versatility of image-to-video models and their potential to be applied to a wider range of video-related tasks, such as keyframe interpolation. While the approach has some limitations, the critical analysis highlights areas for further research and improvement, which could lead to even more powerful and practical tools for animation and video editing.
Overall, the Generative Inbetweening method represents an exciting advancement in the field of video generation and processing, with the promise of enhancing the quality and efficiency of various video-related workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Xiaojuan Wang, Boyang Zhou, Brian Curless, Ira Kemelmacher-Shlizerman, Aleksander Holynski, Steven M. Seitz
We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Read more8/28/2024

0
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Read more5/28/2024

0
Flexible Motion In-betweening with Diffusion Models
Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne
Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
Read more5/27/2024
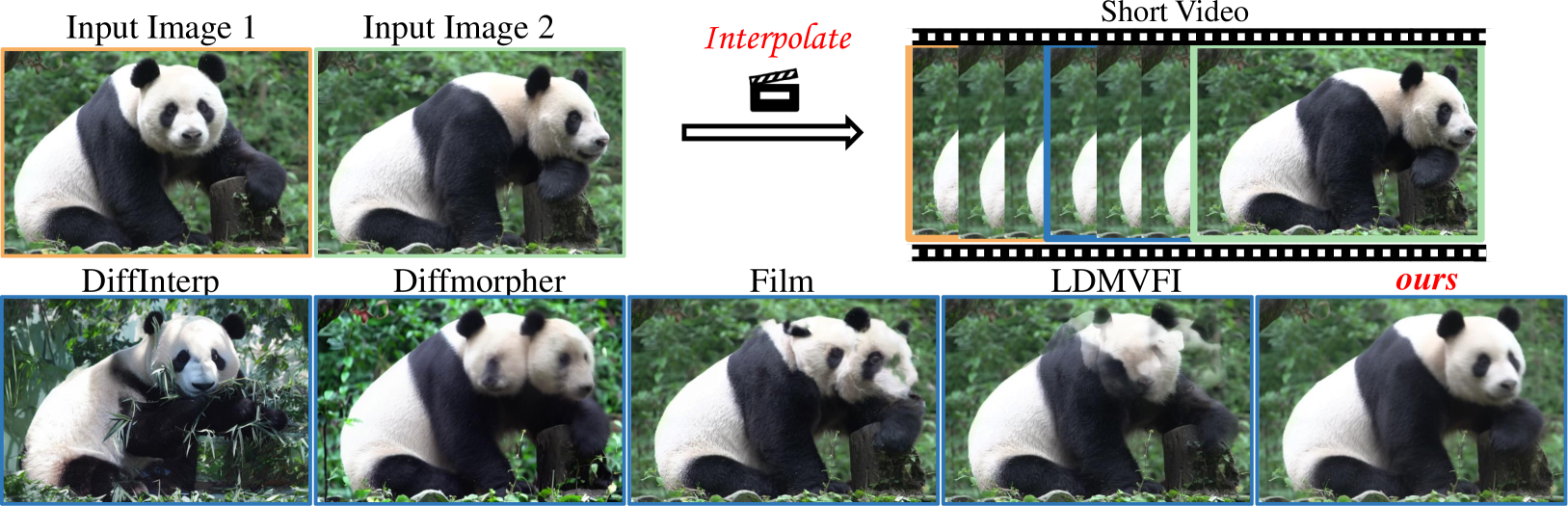
0
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion
Liao Shen, Tianqi Liu, Huiqiang Sun, Xinyi Ye, Baopu Li, Jianming Zhang, Zhiguo Cao
We study the problem of generating intermediate images from image pairs with large motion while maintaining semantic consistency. Due to the large motion, the intermediate semantic information may be absent in input images. Existing methods either limit to small motion or focus on topologically similar objects, leading to artifacts and inconsistency in the interpolation results. To overcome this challenge, we delve into pre-trained image diffusion models for their capabilities in semantic cognition and representations, ensuring consistent expression of the absent intermediate semantic representations with the input. To this end, we propose DreamMover, a novel image interpolation framework with three main components: 1) A natural flow estimator based on the diffusion model that can implicitly reason about the semantic correspondence between two images. 2) To avoid the loss of detailed information during fusion, our key insight is to fuse information in two parts, high-level space and low-level space. 3) To enhance the consistency between the generated images and input, we propose the self-attention concatenation and replacement approach. Lastly, we present a challenging benchmark dataset InterpBench to evaluate the semantic consistency of generated results. Extensive experiments demonstrate the effectiveness of our method. Our project is available at https://dreamm0ver.github.io .
Read more9/19/2024