DrEureka: Language Model Guided Sim-To-Real Transfer
2406.01967
0
0

Abstract
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
Create account to get full access
Overview
- This paper introduces DrEureka, a novel approach for language model-guided sim-to-real transfer learning.
- DrEureka leverages large language models to bridge the gap between simulation and real-world environments, enabling more efficient learning of robot skills.
- The method combines language grounding, domain randomization, and skill transfer to improve the transfer of policies learned in simulation to the physical world.
Plain English Explanation
DrEureka: Language Model Guided Sim-To-Real Transfer is a new technique that helps robots learn skills in simulation and then apply those skills in the real world more effectively.
The key idea is to use large language models, which are AI systems trained on vast amounts of text data, to help bridge the gap between the simulated and real-world environments. Natural language can help bridge the sim-to-real gap by providing a common "language" that the robot can use to understand and interpret both the simulated and physical worlds.
By learning reward and robot skills using large language models, the robot can develop a deeper understanding of the task at hand and how to accomplish it, even when the simulation doesn't perfectly match the real world. This allows the robot to transfer skills from simulation to the real world more effectively.
The researchers demonstrate that DrEureka can help robots learn complex manipulation tasks in simulation and then apply those skills in the physical world with better performance than previous methods. This could lead to more efficient and capable robots that can seamlessly transition from simulation to the real world.
Technical Explanation
DrEureka: Language Model Guided Sim-To-Real Transfer proposes a novel approach for bridging the sim-to-real gap in robotic learning. The key components of the method are:
-
Language Grounding: The researchers use a large pre-trained language model to ground the robot's understanding of the task and environment in natural language. This allows the robot to better interpret the simulated and real-world contexts.
-
Domain Randomization: The simulation environment is randomized across various parameters, such as object shapes, textures, and lighting, to increase the diversity of experiences the robot encounters during training.
-
Skill Transfer: The robot first learns skills in the randomized simulation environment, and then those skills are transferred to the real-world setting using various techniques, such as fine-tuning and domain adaptation.
The researchers evaluate DrEureka on several challenging manipulation tasks, including block stacking, block sorting, and tool use. They demonstrate that DrEureka outperforms previous sim-to-real transfer learning methods, enabling the robot to more effectively apply skills learned in simulation to the physical world.
Critical Analysis
The paper presents a promising approach for improving sim-to-real transfer learning, but it also acknowledges several limitations and areas for further research:
-
The language model used in DrEureka is pre-trained on general text data, which may not capture all the nuances of the specific robotic tasks and environments. Exploring ways to further customize or fine-tune the language model could potentially improve performance.
-
The domain randomization technique, while effective, may not be sufficient to capture all the complexities of the real world. Incorporating more realistic simulations or using other techniques, such as meta-learning, could help further bridge the sim-to-real gap.
-
The paper focuses on manipulation tasks, and it's unclear how well the DrEureka approach would generalize to other types of robotic applications, such as navigation or multi-agent coordination. Expanding the evaluation to a wider range of tasks would be valuable.
Overall, the DrEureka method represents an exciting step forward in sim-to-real transfer learning, leveraging the power of large language models to enhance the robot's understanding and adaptation to the real world. Further research and refinement of the approach could lead to even more capable and adaptable robotic systems.
Conclusion
DrEureka: Language Model Guided Sim-To-Real Transfer presents a novel framework for bridging the gap between simulation and the real world in robotic learning. By integrating language grounding, domain randomization, and skill transfer, the method enables more efficient and effective transfer of skills learned in simulation to physical environments.
The results demonstrate the potential of leveraging large language models to enhance the robot's understanding and adaptation capabilities, leading to improved performance in complex manipulation tasks. While the current approach has some limitations, the overall concept of using large language models as generalizable policies for embodied agents is an exciting direction that could have significant implications for the future of robotics and embodied AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
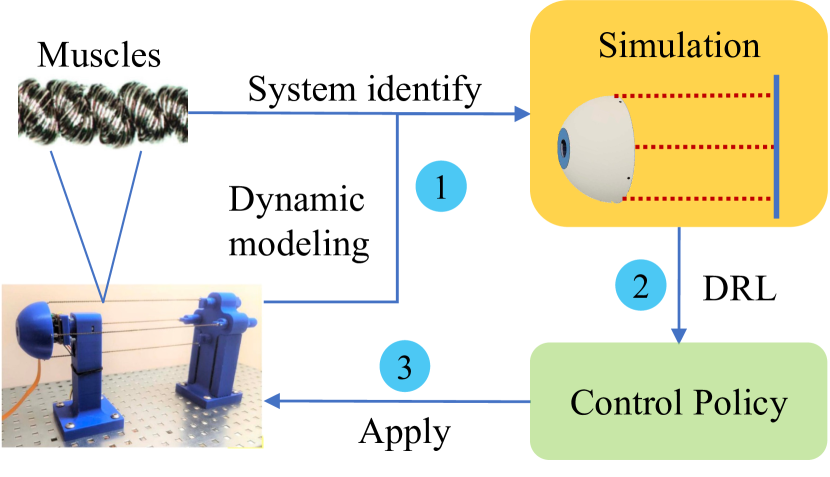
An Efficient Learning Control Framework With Sim-to-Real for String-Type Artificial Muscle-Driven Robotic Systems
Jiyue Tao, Yunsong Zhang, Sunil Kumar Rajendran, Feitian Zhang, Dexin Zhao, Tongsheng Shen
0
0
Robotic systems driven by artificial muscles present unique challenges due to the nonlinear dynamics of actuators and the complex designs of mechanical structures. Traditional model-based controllers often struggle to achieve desired control performance in such systems. Deep reinforcement learning (DRL), a trending machine learning technique widely adopted in robot control, offers a promising alternative. However, integrating DRL into these robotic systems faces significant challenges, including the requirement for large amounts of training data and the inevitable sim-to-real gap when deployed to real-world robots. This paper proposes an efficient reinforcement learning control framework with sim-to-real transfer to address these challenges. Bootstrap and augmentation enhancements are designed to improve the data efficiency of baseline DRL algorithms, while a sim-to-real transfer technique, namely randomization of muscle dynamics, is adopted to bridge the gap between simulation and real-world deployment. Extensive experiments and ablation studies are conducted utilizing two string-type artificial muscle-driven robotic systems including a two degree-of-freedom robotic eye and a parallel robotic wrist, the results of which demonstrate the effectiveness of the proposed learning control strategy.
6/10/2024
Natural Language Can Help Bridge the Sim2Real Gap
Albert Yu, Adeline Foote, Raymond Mooney, Roberto Mart'in-Mart'in
0
0
The main challenge in learning image-conditioned robotic policies is acquiring a visual representation conducive to low-level control. Due to the high dimensionality of the image space, learning a good visual representation requires a considerable amount of visual data. However, when learning in the real world, data is expensive. Sim2Real is a promising paradigm for overcoming data scarcity in the real-world target domain by using a simulator to collect large amounts of cheap data closely related to the target task. However, it is difficult to transfer an image-conditioned policy from sim to real when the domains are very visually dissimilar. To bridge the sim2real visual gap, we propose using natural language descriptions of images as a unifying signal across domains that captures the underlying task-relevant semantics. Our key insight is that if two image observations from different domains are labeled with similar language, the policy should predict similar action distributions for both images. We demonstrate that training the image encoder to predict the language description or the distance between descriptions of a sim or real image serves as a useful, data-efficient pretraining step that helps learn a domain-invariant image representation. We can then use this image encoder as the backbone of an IL policy trained simultaneously on a large amount of simulated and a handful of real demonstrations. Our approach outperforms widely used prior sim2real methods and strong vision-language pretraining baselines like CLIP and R3M by 25 to 40%.
5/17/2024
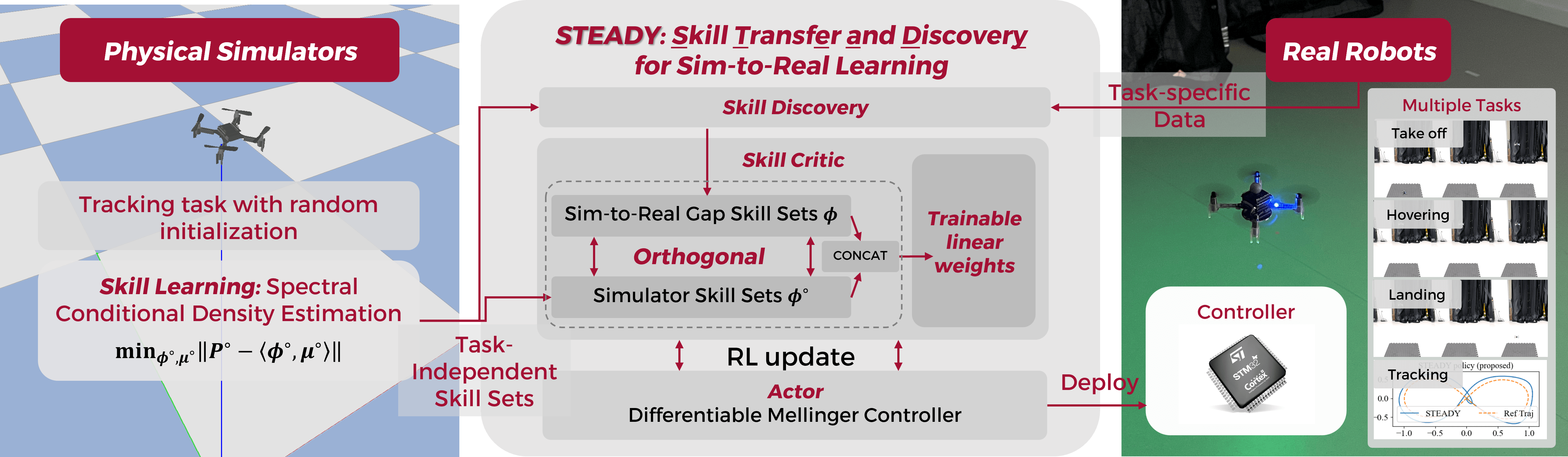
Skill Transfer and Discovery for Sim-to-Real Learning: A Representation-Based Viewpoint
Haitong Ma, Zhaolin Ren, Bo Dai, Na Li
0
0
We study sim-to-real skill transfer and discovery in the context of robotics control using representation learning. We draw inspiration from spectral decomposition of Markov decision processes. The spectral decomposition brings about representation that can linearly represent the state-action value function induced by any policies, thus can be regarded as skills. The skill representations are transferable across arbitrary tasks with the same transition dynamics. Moreover, to handle the sim-to-real gap in the dynamics, we propose a skill discovery algorithm that learns new skills caused by the sim-to-real gap from real-world data. We promote the discovery of new skills by enforcing orthogonal constraints between the skills to learn and the skills from simulators, and then synthesize the policy using the enlarged skill sets. We demonstrate our methodology by transferring quadrotor controllers from simulators to Crazyflie 2.1 quadrotors. We show that we can learn the skill representations from a single simulator task and transfer these to multiple different real-world tasks including hovering, taking off, landing and trajectory tracking. Our skill discovery approach helps narrow the sim-to-real gap and improve the real-world controller performance by up to 30.2%.
4/9/2024
💬
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
0
0
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
5/17/2024