Natural Language Can Help Bridge the Sim2Real Gap
2405.10020
0
0
Abstract
The main challenge in learning image-conditioned robotic policies is acquiring a visual representation conducive to low-level control. Due to the high dimensionality of the image space, learning a good visual representation requires a considerable amount of visual data. However, when learning in the real world, data is expensive. Sim2Real is a promising paradigm for overcoming data scarcity in the real-world target domain by using a simulator to collect large amounts of cheap data closely related to the target task. However, it is difficult to transfer an image-conditioned policy from sim to real when the domains are very visually dissimilar. To bridge the sim2real visual gap, we propose using natural language descriptions of images as a unifying signal across domains that captures the underlying task-relevant semantics. Our key insight is that if two image observations from different domains are labeled with similar language, the policy should predict similar action distributions for both images. We demonstrate that training the image encoder to predict the language description or the distance between descriptions of a sim or real image serves as a useful, data-efficient pretraining step that helps learn a domain-invariant image representation. We can then use this image encoder as the backbone of an IL policy trained simultaneously on a large amount of simulated and a handful of real demonstrations. Our approach outperforms widely used prior sim2real methods and strong vision-language pretraining baselines like CLIP and R3M by 25 to 40%.
Create account to get full access
Overview
- This paper explores how natural language can help bridge the simulation-to-reality (sim2real) gap in robotics and AI
- It proposes using natural language as a shared representation to connect simulated and real-world environments
- The approach aims to enable more effective transfer of skills and policies learned in simulation to the real world
Plain English Explanation
The sim2real gap is a challenge in robotics and AI where systems trained in simulation often struggle to perform well in the real world. This paper explores a novel approach to address this problem by using natural language as a common interface between simulated and real-world environments.
The key idea is to use natural language as a "policy" that can be executed in both the simulated and real-world settings. This allows skills and behaviors learned in simulation to be more effectively transferred to the real world, since the natural language representation acts as a shared "bridge" between the two domains.
By grounding the policies in natural language, the system can leverage the richness and flexibility of human language to describe and communicate complex behaviors. This provides a more intuitive and generalizable way to specify tasks compared to traditional low-level control signals or reward functions.
The paper presents experiments demonstrating how this natural language policy approach can improve sim2real transfer in areas like robotic manipulation and autonomous driving. The results suggest this framework could be a promising direction for making AI systems more robust and adaptable when moving from simulation to the real world.
Technical Explanation
The paper proposes a framework that uses natural language as a shared representation to bridge the sim2real gap. The key idea is to learn policies that are expressed in natural language, which can then be executed in both simulated and real-world environments.
This is achieved by training a neural network model that can map between natural language instructions and the corresponding control policies. The model is trained on paired data of language descriptions and control sequences, allowing it to learn a bidirectional mapping between the two domains.
At deployment time, the natural language policy can be used to control both the simulated and real-world agents. This enables skills and behaviors learned in simulation to be more effectively transferred, since the language representation acts as a common "currency" between the two environments.
The paper evaluates this approach on several tasks, including robotic manipulation and autonomous driving. The results show that the natural language policies can outperform baseline methods that rely on low-level control signals or reward functions alone. The language-based policies demonstrate better generalization and sim2real transfer compared to the alternatives.
Critical Analysis
The paper presents a promising new direction for addressing the sim2real challenge in robotics and AI. The core idea of using natural language as a shared representation between simulated and real-world environments is well-motivated and has the potential to unlock more effective skill and policy transfer.
One limitation discussed in the paper is the need for large datasets of language-policy pairs to train the mapping model effectively. Acquiring such datasets may be a significant challenge, especially for more complex robotic tasks. The authors note that techniques like few-shot learning or language model fine-tuning could help mitigate this issue.
Additionally, the paper does not delve into the potential challenges of grounding natural language in the real world, where perceptual uncertainty and dynamic environments may complicate the execution of language-based policies. Further research would be needed to understand the robustness of this approach in the face of such real-world complexities.
Despite these caveats, the paper's central insight of leveraging natural language as a common interface between simulation and the real world is a compelling one. If the technical challenges can be addressed, this could lead to significant advances in the field of sim2real transfer, with important implications for the development of more capable and adaptable robotic systems.
Conclusion
This paper presents a novel approach to bridging the sim2real gap in robotics and AI by using natural language as a shared representation between simulated and real-world environments. The key idea is to learn policies that are expressed in natural language, which can then be executed in both simulated and real-world settings.
This language-based policy framework aims to enable more effective transfer of skills and behaviors learned in simulation to the real world, by providing a common "currency" that can connect the two domains. Experiments on tasks like robotic manipulation and autonomous driving suggest this approach can outperform traditional methods that rely on low-level control signals or reward functions alone.
While the paper identifies some technical challenges that would need to be addressed, the overall concept of using natural language as a bridge for sim2real transfer is a promising direction that could have significant implications for the development of more capable and adaptable AI and robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DrEureka: Language Model Guided Sim-To-Real Transfer
Yecheng Jason Ma, William Liang, Hung-Ju Wang, Sam Wang, Yuke Zhu, Linxi Fan, Osbert Bastani, Dinesh Jayaraman
0
0
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
6/5/2024
Natural Language as Policies: Reasoning for Coordinate-Level Embodied Control with LLMs
Yusuke Mikami, Andrew Melnik, Jun Miura, Ville Hautamaki
0
0
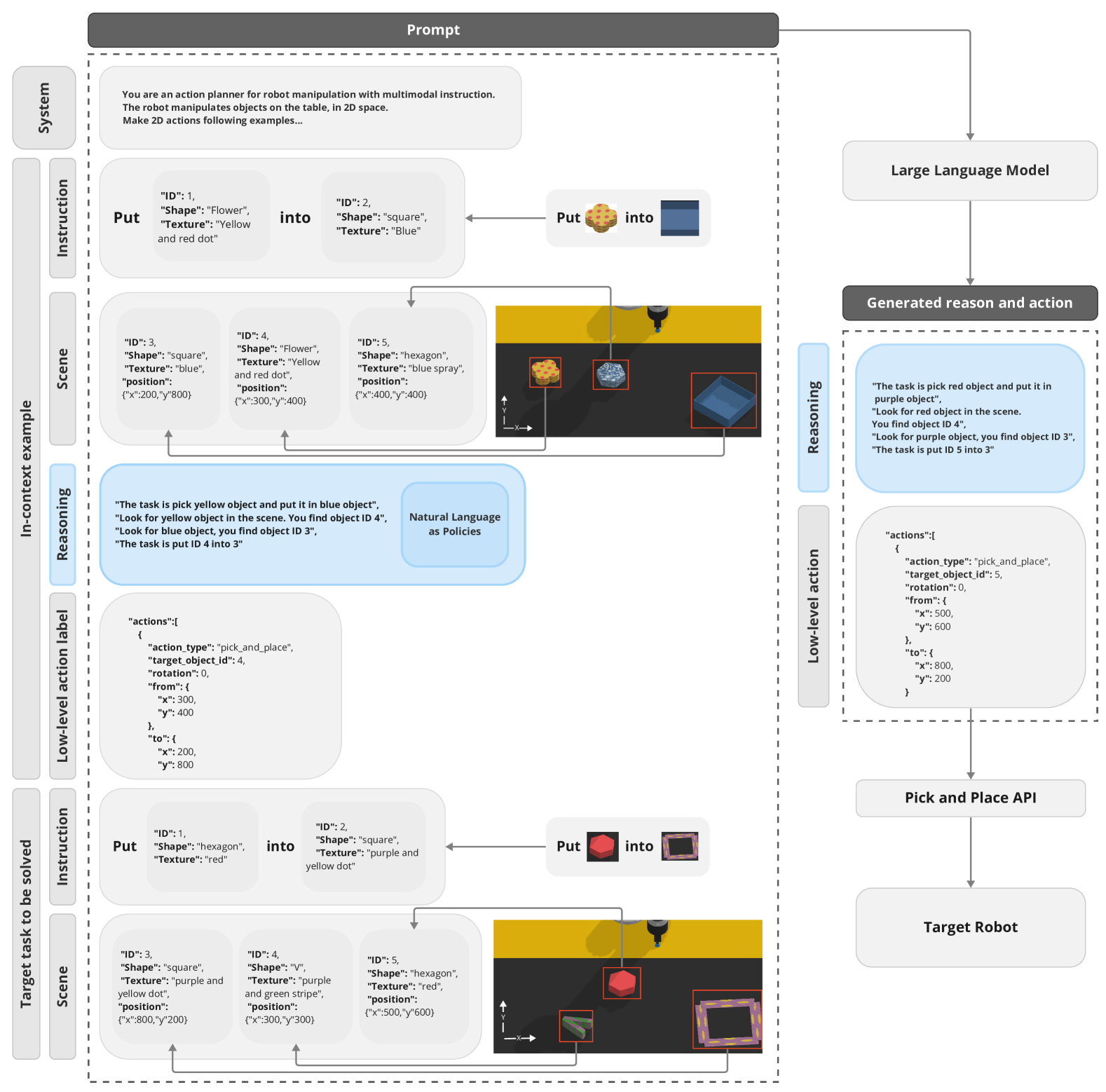
We demonstrate experimental results with LLMs that address robotics task planning problems. Recently, LLMs have been applied in robotics task planning, particularly using a code generation approach that converts complex high-level instructions into mid-level policy codes. In contrast, our approach acquires text descriptions of the task and scene objects, then formulates task planning through natural language reasoning, and outputs coordinate level control commands, thus reducing the necessity for intermediate representation code as policies with pre-defined APIs. Our approach is evaluated on a multi-modal prompt simulation benchmark, demonstrating that our prompt engineering experiments with natural language reasoning significantly enhance success rates compared to its absence. Furthermore, our approach illustrates the potential for natural language descriptions to transfer robotics skills from known tasks to previously unseen tasks. The project website: https://natural-language-as-policies.github.io/
4/9/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024
Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics
Minttu Alakuijala, Reginald McLean, Isaac Woungang, Nariman Farsad, Samuel Kaski, Pekka Marttinen, Kai Yuan
0
0
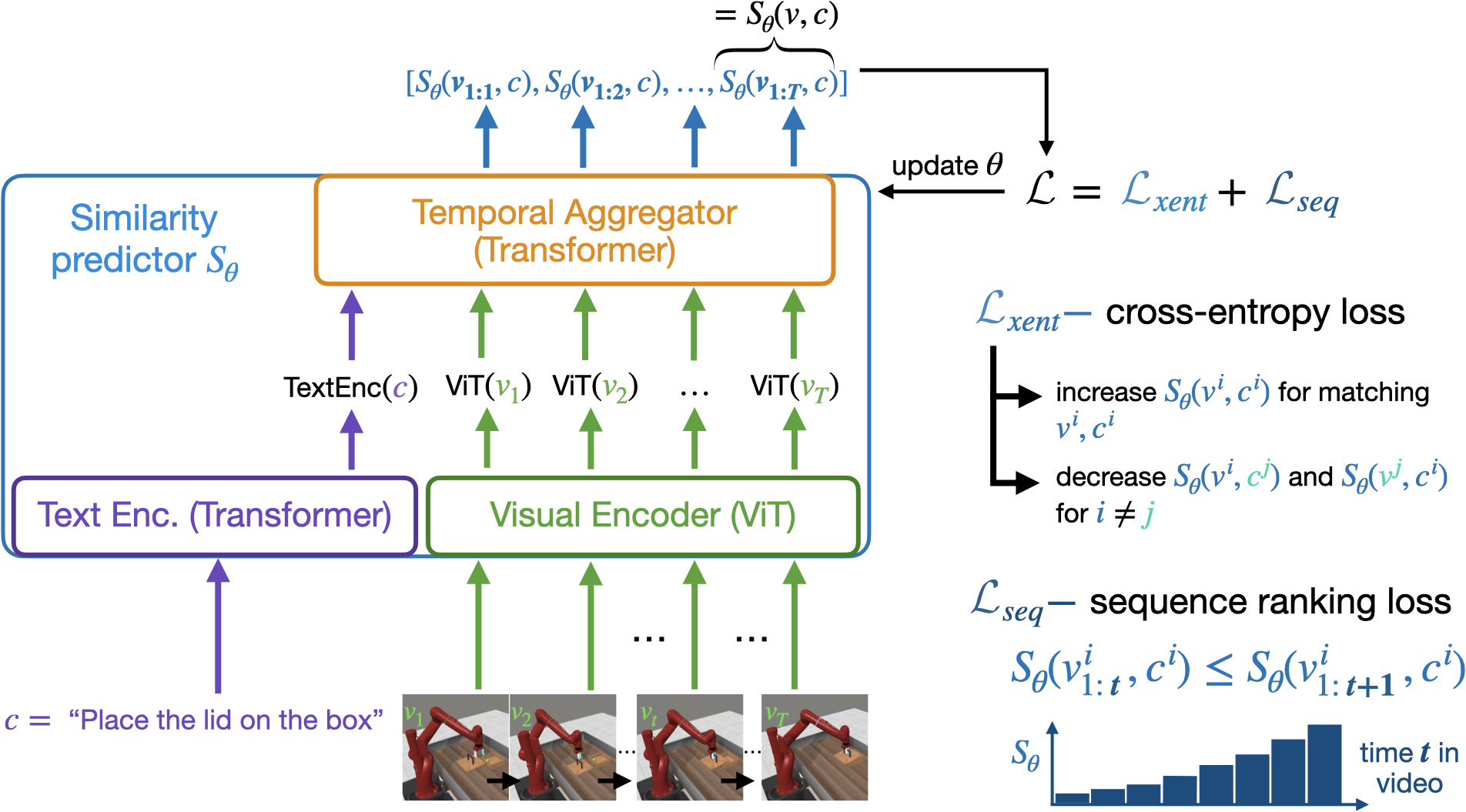
Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate reinforcement learning actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.
5/31/2024