Large Language Models as Generalizable Policies for Embodied Tasks
2310.17722
0
0
💬
Abstract
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
Create account to get full access
Overview
- The paper shows how large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks.
- The authors' approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take text instructions and visual observations as input and output actions directly in the environment.
- Using reinforcement learning, LLaRP is trained to see and act solely through environmental interactions.
- LLaRP is robust to complex paraphrases of task instructions and can generalize to new tasks that require novel optimal behavior.
- The authors release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement.
Plain English Explanation
The researchers have developed a system that allows large language models (LLMs) to be used for embodied visual tasks, such as navigating and manipulating objects in a virtual environment. Their approach, called LLaRP, takes a pre-trained LLM and fine-tunes it using reinforcement learning to directly output actions based on text instructions and visual observations from the environment.
This is significant because it allows LLMs, which are typically trained on text-only data, to be applied to more complex, interactive tasks that involve both language and visual perception. By training the model solely through environmental interactions, the researchers show that LLaRP can be robust to various ways of phrasing task instructions and can generalize to new tasks that require novel behavior.
To help the research community study this type of language-conditioned, multi-task embodied AI, the authors have also released a new benchmark called Language Rearrangement, which consists of 150,000 training tasks and 1,000 testing tasks focused on rearranging objects based on language instructions.
Technical Explanation
The paper presents the Large LAnguage model Reinforcement Learning Policy (LLaRP) approach, which adapts a pre-trained, frozen large language model (LLM) to perform embodied visual tasks. LLaRP takes as input both text instructions and egocentric visual observations from the environment, and directly outputs actions to be executed in the environment.
The researchers use reinforcement learning to train LLaRP, allowing the model to learn solely through interactions with the environment, without any ground-truth action labels. This enables LLaRP to be robust to complex paraphrases of task instructions and to generalize to new tasks that require novel optimal behavior.
Experiments show that on 1,000 unseen tasks, LLaRP achieves a 42% success rate, which is 1.7 times higher than other common learned baselines or zero-shot applications of LLMs. To facilitate further research in this area, the authors also release a new benchmark called Language Rearrangement, which consists of 150,000 training tasks and 1,000 testing tasks focused on language-conditioned object rearrangement.
Critical Analysis
The research presented in this paper is a significant step forward in adapting large language models to handle embodied, interactive tasks. By using reinforcement learning to train the LLM-based LLaRP model, the authors have shown that it is possible to create generalizable policies that can handle complex language instructions and new tasks.
However, the paper does acknowledge some limitations. The Language Rearrangement benchmark, while a valuable contribution, may not capture the full complexity of real-world embodied tasks. Additionally, the reinforcement learning training process can be computationally expensive and may not scale easily to larger-scale problems.
Further research is needed to explore ways to make the training process more efficient, as well as to evaluate the performance of LLaRP on a wider range of embodied tasks. Potential areas for improvement include incorporating additional sensory modalities (e.g., audio, haptics) and exploring hybrid approaches that combine language understanding with other AI techniques, such as knowledge-driven reinforcement learning or large-scale multi-modal learning.
Conclusion
The LLaRP approach presented in this paper represents an important step towards making large language models more versatile and applicable to real-world, embodied tasks. By training LLMs to directly output actions based on language instructions and visual observations, the researchers have shown that these powerful models can be adapted to handle complex, interactive scenarios.
The release of the Language Rearrangement benchmark is also a valuable contribution, as it will help drive further research and development in this area. As the field of embodied AI continues to evolve, techniques like natural language as policies, large language models orchestrating bimanual robots, and long-horizon locomotion and manipulation may become increasingly important for creating intelligent, language-aware systems that can seamlessly interact with the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
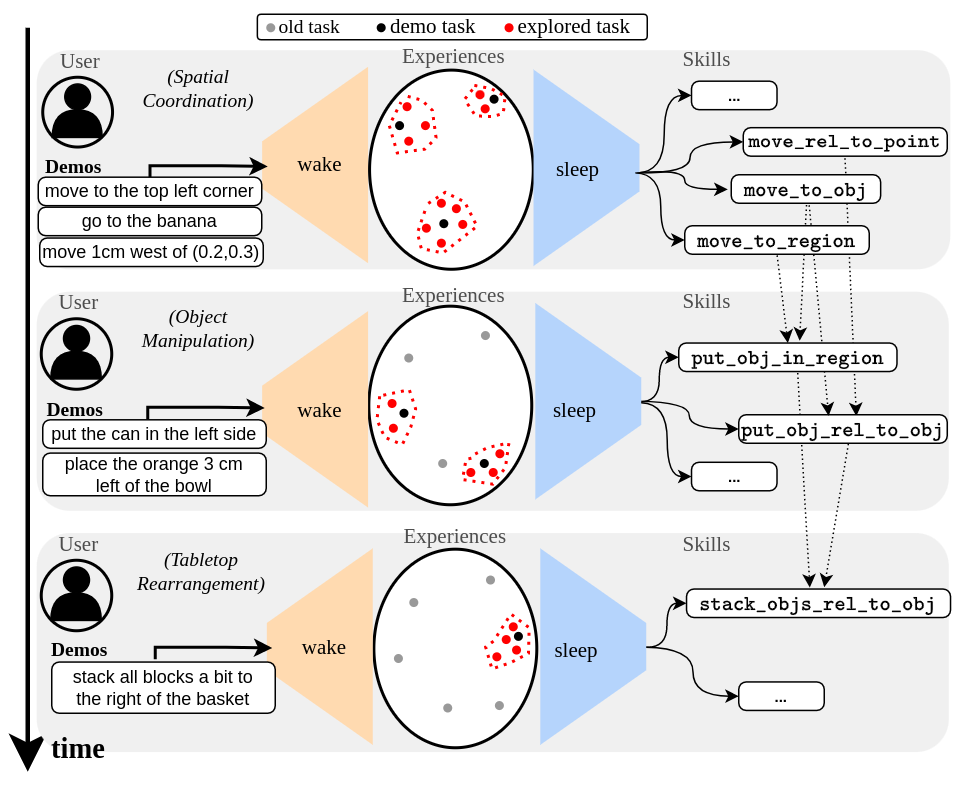
Lifelong Robot Library Learning: Bootstrapping Composable and Generalizable Skills for Embodied Control with Language Models
Georgios Tziafas, Hamidreza Kasaei
0
0
Large Language Models (LLMs) have emerged as a new paradigm for embodied reasoning and control, most recently by generating robot policy code that utilizes a custom library of vision and control primitive skills. However, prior arts fix their skills library and steer the LLM with carefully hand-crafted prompt engineering, limiting the agent to a stationary range of addressable tasks. In this work, we introduce LRLL, an LLM-based lifelong learning agent that continuously grows the robot skill library to tackle manipulation tasks of ever-growing complexity. LRLL achieves this with four novel contributions: 1) a soft memory module that allows dynamic storage and retrieval of past experiences to serve as context, 2) a self-guided exploration policy that proposes new tasks in simulation, 3) a skill abstractor that distills recent experiences into new library skills, and 4) a lifelong learning algorithm for enabling human users to bootstrap new skills with minimal online interaction. LRLL continuously transfers knowledge from the memory to the library, building composable, general and interpretable policies, while bypassing gradient-based optimization, thus relieving the learner from catastrophic forgetting. Empirical evaluation in a simulated tabletop environment shows that LRLL outperforms end-to-end and vanilla LLM approaches in the lifelong setup while learning skills that are transferable to the real world. Project material will become available at the webpage https://gtziafas.github.io/LRLL_project.
6/28/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024