DRIVE: Dual Gradient-Based Rapid Iterative Pruning
2404.03687
0
0
📈
Abstract
Modern deep neural networks (DNNs) consist of millions of parameters, necessitating high-performance computing during training and inference. Pruning is one solution that significantly reduces the space and time complexities of DNNs. Traditional pruning methods that are applied post-training focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training. Pruning methods, such as iterative magnitude-based pruning (IMP) achieve up to a 90% parameter reduction while retaining accuracy comparable to the original model. However, this leads to impractical runtime as it relies on multiple train-prune-reset cycles to identify and eliminate redundant parameters. In contrast, training agnostic early pruning methods, such as SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities. To bridge this gap, we present Dual Gradient-Based Rapid Iterative Pruning (DRIVE), which leverages dense training for initial epochs to counteract the randomness inherent at the initialization. Subsequently, it employs a unique dual gradient-based metric for parameter ranking. It has been experimentally demonstrated for VGG and ResNet architectures on CIFAR-10/100 and Tiny ImageNet, and ResNet on ImageNet that DRIVE consistently has superior performance over other training-agnostic early pruning methods in accuracy. Notably, DRIVE is 43$times$ to 869$times$ faster than IMP for pruning.
Create account to get full access
Overview
- Modern deep neural networks (DNNs) have millions of parameters, requiring high-performance computing during training and inference.
- Pruning is a solution that can significantly reduce the space and time complexity of DNNs.
- Traditional pruning methods focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training.
- Pruning methods like Iterative Magnitude-Based Pruning (IMP) can achieve up to 90% parameter reduction while retaining accuracy, but this leads to impractical runtime.
- Training-agnostic early pruning methods like SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities.
Plain English Explanation
Deep learning models, which are a type of artificial intelligence, can have millions of parameters, which are the values that the model learns during training. This makes it computationally intensive to train and use these models, especially on devices with limited resources.
Pruning is a technique that can reduce the number of parameters in a deep learning model, making it smaller and faster to use. Traditional pruning methods focus on making the model more efficient for final deployment, but some newer approaches try to prune the model before training it, when the model is still large and inefficient.
One pruning method called Iterative Magnitude-Based Pruning (IMP) can remove up to 90% of the parameters in a model while still maintaining its accuracy. However, this method requires repeatedly training, pruning, and resetting the model, which takes a long time.
Other pruning methods, like SNIP and SynFlow, can prune the model much faster, but they don't achieve the same high accuracy as IMP, especially when the model is pruned a lot.
Technical Explanation
The paper introduces a new pruning method called Dual Gradient-Based Rapid Iterative Pruning (DRIVE) that aims to bridge the gap between the fast but less accurate training-agnostic pruning methods and the more accurate but slower iterative pruning methods.
DRIVE leverages dense training for the initial epochs to counteract the randomness inherent at model initialization. It then employs a unique dual gradient-based metric for ranking and pruning parameters. This allows DRIVE to achieve superior performance in terms of accuracy compared to other training-agnostic early pruning methods, while being significantly faster than the iterative magnitude-based pruning (IMP) approach.
The authors have experimentally demonstrated the effectiveness of DRIVE on various deep learning architectures, including VGG and ResNet, using the CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet datasets. The results show that DRIVE is 43x to 869x faster than IMP for pruning, while still maintaining comparable or better accuracy.
Critical Analysis
The paper presents a promising approach to address the limitations of existing pruning methods. By leveraging dense training and a novel dual gradient-based metric, DRIVE is able to achieve high levels of sparsity while retaining accuracy better than other training-agnostic pruning techniques.
One potential limitation of the DRIVE method is that it still requires multiple training-pruning-reset cycles, albeit fewer than IMP. This may still lead to long runtimes, especially for large-scale models and datasets. The paper could have discussed strategies to further reduce the number of iterations or explore single-shot pruning approaches.
Additionally, the paper focuses on evaluating DRIVE on image classification tasks. It would be interesting to see how the method performs on other types of deep learning tasks, such as natural language processing or reinforcement learning, to assess its broader applicability.
Overall, the DRIVE method represents a valuable contribution to the field of model compression and acceleration. By bridging the gap between fast but less accurate pruning and slower but more accurate pruning, it provides a compelling solution for improving the efficiency of deep neural networks.
Conclusion
The paper introduces a new pruning method called Dual Gradient-Based Rapid Iterative Pruning (DRIVE) that aims to address the limitations of existing pruning approaches. DRIVE leverages dense training and a unique dual gradient-based metric to achieve superior performance in terms of accuracy compared to other training-agnostic early pruning methods, while being significantly faster than the iterative magnitude-based pruning (IMP) approach.
The experimental results demonstrate the effectiveness of DRIVE on various deep learning architectures and datasets, showcasing its ability to achieve high levels of model sparsity without sacrificing accuracy. This work represents an important step forward in model compression and acceleration, potentially enabling the deployment of deep neural networks on resource-constrained devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
Rapid Deployment of DNNs for Edge Computing via Structured Pruning at Initialization
Bailey J. Eccles, Leon Wong, Blesson Varghese
0
0
Edge machine learning (ML) enables localized processing of data on devices and is underpinned by deep neural networks (DNNs). However, DNNs cannot be easily run on devices due to their substantial computing, memory and energy requirements for delivering performance that is comparable to cloud-based ML. Therefore, model compression techniques, such as pruning, have been considered. Existing pruning methods are problematic for edge ML since they: (1) Create compressed models that have limited runtime performance benefits (using unstructured pruning) or compromise the final model accuracy (using structured pruning), and (2) Require substantial compute resources and time for identifying a suitable compressed DNN model (using neural architecture search). In this paper, we explore a new avenue, referred to as Pruning-at-Initialization (PaI), using structured pruning to mitigate the above problems. We develop Reconvene, a system for rapidly generating pruned models suited for edge deployments using structured PaI. Reconvene systematically identifies and prunes DNN convolution layers that are least sensitive to structured pruning. Reconvene rapidly creates pruned DNNs within seconds that are up to 16.21x smaller and 2x faster while maintaining the same accuracy as an unstructured PaI counterpart.
4/29/2024

Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Xinglong Sun, Barath Lakshmanan, Maying Shen, Shiyi Lan, Jingde Chen, Jose Alvarez
0
0
As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
6/19/2024
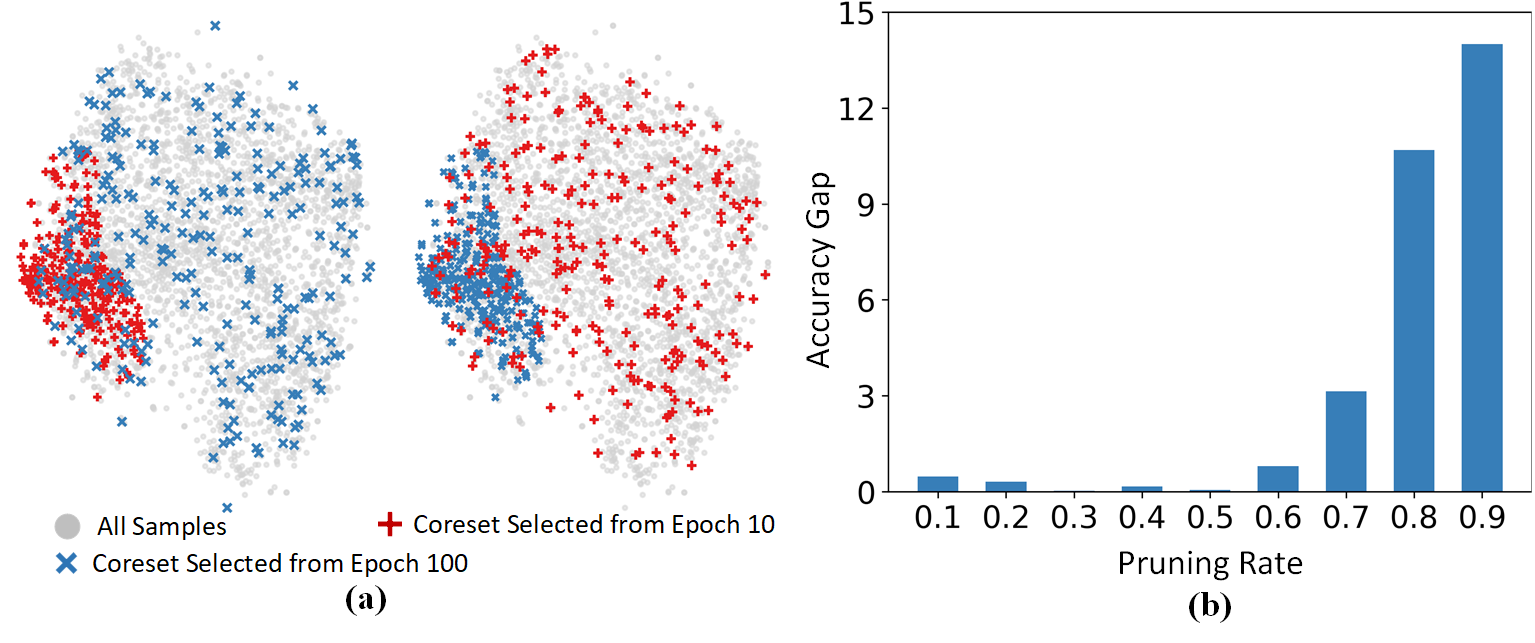
Spanning Training Progress: Temporal Dual-Depth Scoring (TDDS) for Enhanced Dataset Pruning
Xin Zhang, Jiawei Du, Yunsong Li, Weiying Xie, Joey Tianyi Zhou
0
0
Dataset pruning aims to construct a coreset capable of achieving performance comparable to the original, full dataset. Most existing dataset pruning methods rely on snapshot-based criteria to identify representative samples, often resulting in poor generalization across various pruning and cross-architecture scenarios. Recent studies have addressed this issue by expanding the scope of training dynamics considered, including factors such as forgetting event and probability change, typically using an averaging approach. However, these works struggle to integrate a broader range of training dynamics without overlooking well-generalized samples, which may not be sufficiently highlighted in an averaging manner. In this study, we propose a novel dataset pruning method termed as Temporal Dual-Depth Scoring (TDDS), to tackle this problem. TDDS utilizes a dual-depth strategy to achieve a balance between incorporating extensive training dynamics and identifying representative samples for dataset pruning. In the first depth, we estimate the series of each sample's individual contributions spanning the training progress, ensuring comprehensive integration of training dynamics. In the second depth, we focus on the variability of the sample-wise contributions identified in the first depth to highlight well-generalized samples. Extensive experiments conducted on CIFAR and ImageNet datasets verify the superiority of TDDS over previous SOTA methods. Specifically on CIFAR-100, our method achieves 54.51% accuracy with only 10% training data, surpassing random selection by 7.83% and other comparison methods by at least 12.69%.
5/29/2024
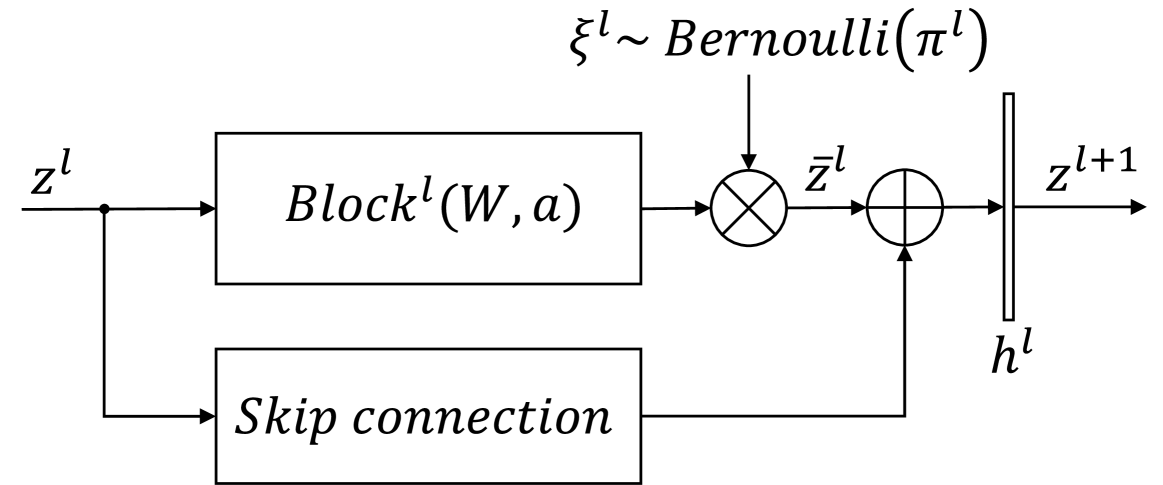
Concurrent Training and Layer Pruning of Deep Neural Networks
Valentin Frank Ingmar Guenter, Athanasios Sideris
0
0
We propose an algorithm capable of identifying and eliminating irrelevant layers of a neural network during the early stages of training. In contrast to weight or filter-level pruning, layer pruning reduces the harder to parallelize sequential computation of a neural network. We employ a structure using residual connections around nonlinear network sections that allow the flow of information through the network once a nonlinear section is pruned. Our approach is based on variational inference principles using Gaussian scale mixture priors on the neural network weights and allows for substantial cost savings during both training and inference. More specifically, the variational posterior distribution of scalar Bernoulli random variables multiplying a layer weight matrix of its nonlinear sections is learned, similarly to adaptive layer-wise dropout. To overcome challenges of concurrent learning and pruning such as premature pruning and lack of robustness with respect to weight initialization or the size of the starting network, we adopt the flattening hyper-prior on the prior parameters. We prove that, as a result of its usage, the solutions of the resulting optimization problem describe deterministic networks with parameters of the posterior distribution at either 0 or 1. We formulate a projected SGD algorithm and prove its convergence to such a solution using stochastic approximation results. In particular, we prove conditions that lead to a layer's weights converging to zero and derive practical pruning conditions from the theoretical results. The proposed algorithm is evaluated on the MNIST, CIFAR-10 and ImageNet datasets and common LeNet, VGG16 and ResNet architectures. The simulations demonstrate that our method achieves state-of the-art performance for layer pruning at reduced computational cost in distinction to competing methods due to the concurrent training and pruning.
6/10/2024