Concurrent Training and Layer Pruning of Deep Neural Networks
2406.04549
0
0
Abstract
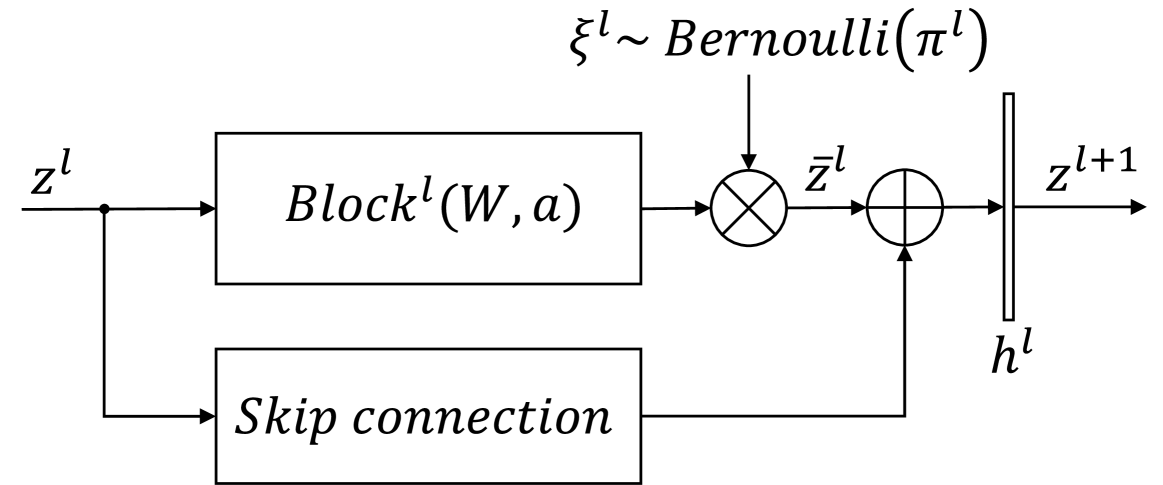
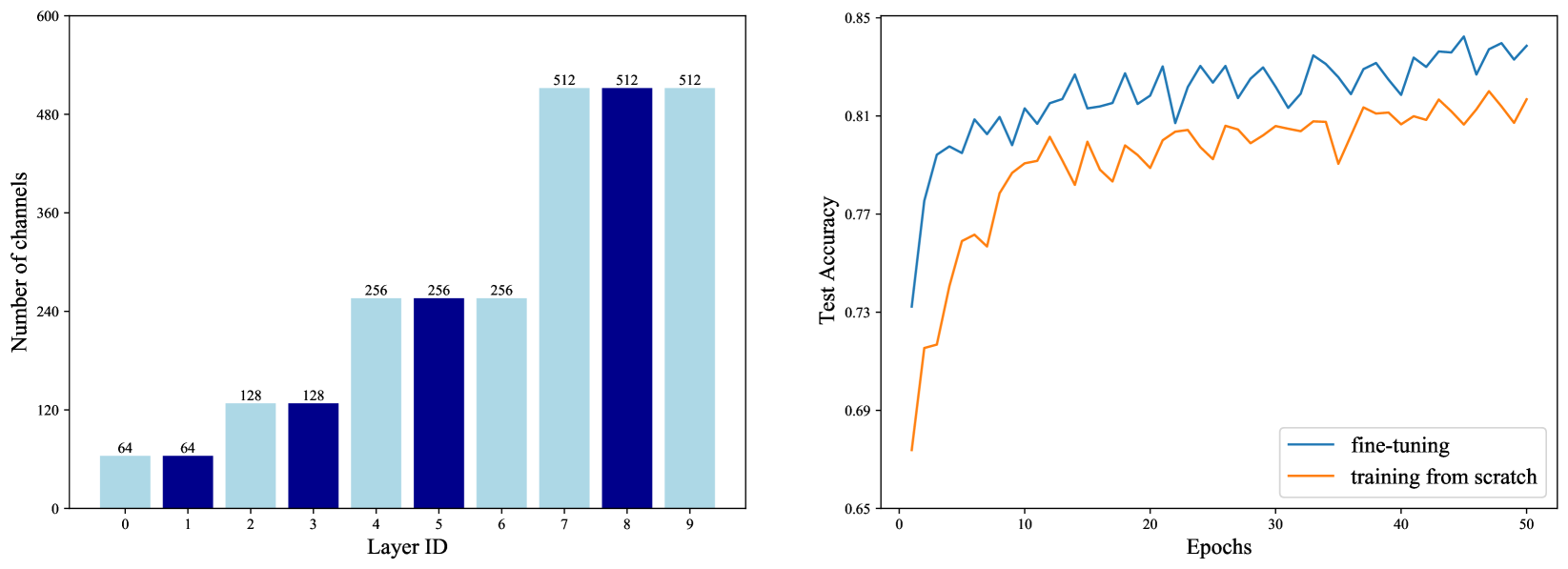
We propose an algorithm capable of identifying and eliminating irrelevant layers of a neural network during the early stages of training. In contrast to weight or filter-level pruning, layer pruning reduces the harder to parallelize sequential computation of a neural network. We employ a structure using residual connections around nonlinear network sections that allow the flow of information through the network once a nonlinear section is pruned. Our approach is based on variational inference principles using Gaussian scale mixture priors on the neural network weights and allows for substantial cost savings during both training and inference. More specifically, the variational posterior distribution of scalar Bernoulli random variables multiplying a layer weight matrix of its nonlinear sections is learned, similarly to adaptive layer-wise dropout. To overcome challenges of concurrent learning and pruning such as premature pruning and lack of robustness with respect to weight initialization or the size of the starting network, we adopt the flattening hyper-prior on the prior parameters. We prove that, as a result of its usage, the solutions of the resulting optimization problem describe deterministic networks with parameters of the posterior distribution at either 0 or 1. We formulate a projected SGD algorithm and prove its convergence to such a solution using stochastic approximation results. In particular, we prove conditions that lead to a layer's weights converging to zero and derive practical pruning conditions from the theoretical results. The proposed algorithm is evaluated on the MNIST, CIFAR-10 and ImageNet datasets and common LeNet, VGG16 and ResNet architectures. The simulations demonstrate that our method achieves state-of the-art performance for layer pruning at reduced computational cost in distinction to competing methods due to the concurrent training and pruning.
Create account to get full access
Overview
- This paper proposes a concurrent training and layer pruning method for deep neural networks.
- The method involves training the network and pruning layers simultaneously, rather than performing pruning as a separate step after training.
- The authors claim this approach can lead to better performance and efficiency compared to traditional training and pruning approaches.
Plain English Explanation
The researchers in this paper are looking at a technique for making deep neural networks more efficient. Deep neural networks are a type of AI system that can be very powerful, but they also tend to be quite large and complex, which can make them slow and energy-intensive to run, especially on smaller devices.
The key idea the researchers are exploring is doing the network "training" (the process of teaching the network to perform a task) and the "pruning" (the process of removing unnecessary parts of the network to make it smaller) at the same time, rather than as separate steps. The thinking is that by tightly integrating these two processes, the network can be made more efficient without losing too much performance.
Imagine you're building a house and you have a bunch of extra materials left over. Normally, you'd finish building the house first, then go back and remove the extra materials. But the researchers are suggesting that as you're building the house, you should also be identifying and removing any extra materials you don't need. This could save you time and resources in the long run.
The researchers ran experiments to test their concurrent training and pruning approach, and they found that it can indeed lead to more efficient networks compared to the traditional approach of training first and pruning later. This could be really useful for deploying AI systems on things like smartphones or other devices with limited computing power.
Technical Explanation
The paper proposes a concurrent training and layer pruning method for deep neural networks. Rather than training the network first and then pruning layers as a separate step, the method trains the network and prunes layers simultaneously.
The authors argue that this integrated approach can lead to better performance and efficiency compared to the traditional training-then-pruning pipeline. The intuition is that by tightly coupling the training and pruning processes, the network can be made more compact and streamlined from the start, without losing too much accuracy.
The authors evaluate their method on several benchmark deep learning tasks and compare it to state-of-the-art pruning techniques. They find that their concurrent approach can achieve comparable or better performance while resulting in more efficient network architectures.
Critical Analysis
The paper provides a compelling approach to network pruning that aims to address some of the limitations of existing methods. By concurrently training and pruning the network, the authors claim they can achieve better efficiency without sacrificing too much accuracy.
However, the paper does not fully address the potential downsides or caveats of this approach. For example, the impact on training stability and convergence is not thoroughly explored. Additionally, the computational overhead of the concurrent pruning process is not quantified, which could be an important practical consideration.
Furthermore, the experiments are conducted on a limited set of benchmark tasks, and it's unclear how well the method would generalize to a wider range of deep learning applications. Lastly, the paper does not discuss potential negative societal impacts of deploying more efficient AI models, such as increased surveillance or displacement of human jobs.
Overall, the paper presents a promising direction for network pruning, but further research is needed to fully understand the strengths, weaknesses, and broader implications of the concurrent training and pruning approach.
Conclusion
This paper introduces a novel method for training and pruning deep neural networks concurrently, rather than as separate steps. The authors claim this integrated approach can lead to more efficient network architectures without significant loss of performance.
The experimental results are encouraging and suggest the concurrent training and pruning technique could be a valuable tool for deploying AI systems, especially on resource-constrained devices like smartphones. However, the paper also highlights the need for further research to fully understand the method's limitations and potential pitfalls.
As AI systems become more widely adopted, it will be crucial to develop techniques that can balance model performance, efficiency, and responsible deployment. The ideas presented in this paper represent an important step in that direction, but there is still much work to be done.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Iterative Filter Pruning for Concatenation-based CNN Architectures
Svetlana Pavlitska, Oliver Bagge, Federico Peccia, Toghrul Mammadov, J. Marius Zollner
0
0
Model compression and hardware acceleration are essential for the resource-efficient deployment of deep neural networks. Modern object detectors have highly interconnected convolutional layers with concatenations. In this work, we study how pruning can be applied to such architectures, exemplary for YOLOv7. We propose a method to handle concatenation layers, based on the connectivity graph of convolutional layers. By automating iterative sensitivity analysis, pruning, and subsequent model fine-tuning, we can significantly reduce model size both in terms of the number of parameters and FLOPs, while keeping comparable model accuracy. Finally, we deploy pruned models to FPGA and NVIDIA Jetson Xavier AGX. Pruned models demonstrate a 2x speedup for the convolutional layers in comparison to the unpruned counterparts and reach real-time capability with 14 FPS on FPGA. Our code is available at https://github.com/fzi-forschungszentrum-informatik/iterative-yolo-pruning.
5/8/2024
A Generic Layer Pruning Method for Signal Modulation Recognition Deep Learning Models
Yao Lu, Yutao Zhu, Yuqi Li, Dongwei Xu, Yun Lin, Qi Xuan, Xiaoniu Yang
0
0
With the successful application of deep learning in communications systems, deep neural networks are becoming the preferred method for signal classification. Although these models yield impressive results, they often come with high computational complexity and large model sizes, which hinders their practical deployment in communication systems. To address this challenge, we propose a novel layer pruning method. Specifically, we decompose the model into several consecutive blocks, each containing consecutive layers with similar semantics. Then, we identify layers that need to be preserved within each block based on their contribution. Finally, we reassemble the pruned blocks and fine-tune the compact model. Extensive experiments on five datasets demonstrate the efficiency and effectiveness of our method over a variety of state-of-the-art baselines, including layer pruning and channel pruning methods.
6/13/2024
🧠
LayerMerge: Neural Network Depth Compression through Layer Pruning and Merging
Jinuk Kim, Marwa El Halabi, Mingi Ji, Hyun Oh Song
0
0
Recent works show that reducing the number of layers in a convolutional neural network can enhance efficiency while maintaining the performance of the network. Existing depth compression methods remove redundant non-linear activation functions and merge the consecutive convolution layers into a single layer. However, these methods suffer from a critical drawback; the kernel size of the merged layers becomes larger, significantly undermining the latency reduction gained from reducing the depth of the network. We show that this problem can be addressed by jointly pruning convolution layers and activation functions. To this end, we propose LayerMerge, a novel depth compression method that selects which activation layers and convolution layers to remove, to achieve a desired inference speed-up while minimizing performance loss. Since the corresponding selection problem involves an exponential search space, we formulate a novel surrogate optimization problem and efficiently solve it via dynamic programming. Empirical results demonstrate that our method consistently outperforms existing depth compression and layer pruning methods on various network architectures, both on image classification and generation tasks. We release the code at https://github.com/snu-mllab/LayerMerge.
6/27/2024

Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Xinglong Sun, Barath Lakshmanan, Maying Shen, Shiyi Lan, Jingde Chen, Jose Alvarez
0
0
As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
6/19/2024