Rapid Deployment of DNNs for Edge Computing via Structured Pruning at Initialization
2404.16877
0
0
🎲
Abstract
Edge machine learning (ML) enables localized processing of data on devices and is underpinned by deep neural networks (DNNs). However, DNNs cannot be easily run on devices due to their substantial computing, memory and energy requirements for delivering performance that is comparable to cloud-based ML. Therefore, model compression techniques, such as pruning, have been considered. Existing pruning methods are problematic for edge ML since they: (1) Create compressed models that have limited runtime performance benefits (using unstructured pruning) or compromise the final model accuracy (using structured pruning), and (2) Require substantial compute resources and time for identifying a suitable compressed DNN model (using neural architecture search). In this paper, we explore a new avenue, referred to as Pruning-at-Initialization (PaI), using structured pruning to mitigate the above problems. We develop Reconvene, a system for rapidly generating pruned models suited for edge deployments using structured PaI. Reconvene systematically identifies and prunes DNN convolution layers that are least sensitive to structured pruning. Reconvene rapidly creates pruned DNNs within seconds that are up to 16.21x smaller and 2x faster while maintaining the same accuracy as an unstructured PaI counterpart.
Create account to get full access
Overview
- Edge machine learning (ML) enables processing data on devices instead of in the cloud
- This is powered by deep neural networks (DNNs), which are complex and resource-intensive
- Existing methods for compressing DNNs to run on edge devices have limitations:
- Unstructured pruning provides limited performance benefits
- Structured pruning can compromise model accuracy
- Finding the right compressed model requires extensive computation and time
Plain English Explanation
Edge machine learning allows devices like smartphones and sensors to process data locally, rather than sending it to the cloud. This is made possible by advanced deep neural networks. However, these neural networks require a lot of computing power, memory, and energy, making them difficult to run on edge devices.
To address this, researchers have explored model compression techniques like pruning, which remove parts of the neural network. But existing pruning methods have issues - some don't provide enough performance gains, while others reduce the model's accuracy. Plus, finding the right compressed model can be very time-consuming.
This paper introduces a new approach called Pruning-at-Initialization (PaI), which uses a specific type of pruning called structured pruning to create models suited for edge devices. The researchers developed a system called Reconvene that can rapidly generate these pruned models, making them up to 16 times smaller and 2 times faster than unpruned models, without losing accuracy.
Technical Explanation
The paper proposes a new system called Reconvene that leverages structured pruning to efficiently compress deep neural networks for edge device deployment. Reconvene systematically identifies and prunes the DNN convolution layers that are least sensitive to structured pruning, allowing it to create pruned models within seconds that are up to 16.21x smaller and 2x faster than their unpruned counterparts, while maintaining the same accuracy.
This is an improvement over existing model compression techniques, which either provide limited runtime performance benefits (using unstructured pruning) or compromise final model accuracy (using structured pruning). Reconvene's rapid structured pruning approach addresses these limitations, making it well-suited for edge ML deployments.
Critical Analysis
The paper presents a promising approach for enabling efficient edge ML by rapidly generating compressed deep neural network models through structured pruning. However, the authors do acknowledge some limitations. For example, the effectiveness of the pruning approach may depend on the specific DNN architecture and task, and further research is needed to generalize the findings.
Additionally, the paper does not explore the potential impact of the compressed models on model robustness, interpretability, or other important factors beyond raw accuracy and inference speed. These are important considerations for real-world edge ML deployments that should be investigated in future work.
Overall, the Reconvene system represents an interesting advance in the field of efficient edge ML, but there is still room for further research and refinement to fully address the challenges of deploying complex deep learning models on resource-constrained devices.
Conclusion
This paper introduces a new approach called Pruning-at-Initialization (PaI) that uses structured pruning to rapidly generate deep neural network models optimized for edge device deployments. The Reconvene system developed by the researchers can create pruned models that are up to 16 times smaller and 2 times faster than unpruned models, without sacrificing accuracy.
This work addresses key limitations of existing model compression techniques, making it a promising step towards enabling powerful machine learning capabilities on the edge. As edge computing becomes more prevalent, innovations like Reconvene will be crucial for unlocking the full potential of deep learning in real-world, resource-constrained applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
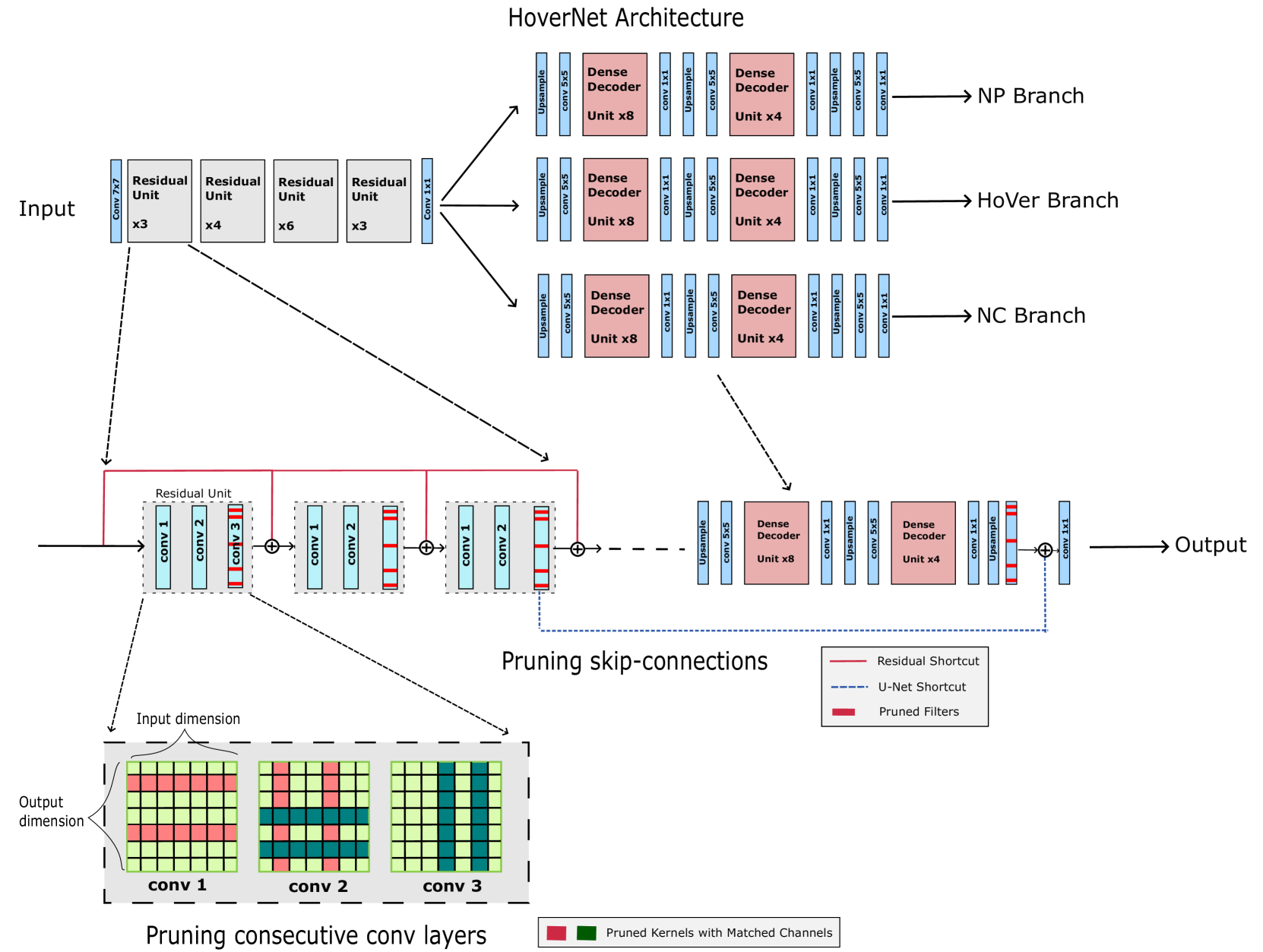
Structured Model Pruning for Efficient Inference in Computational Pathology
Mohammed Adnan, Qinle Ba, Nazim Shaikh, Shivam Kalra, Satarupa Mukherjee, Auranuch Lorsakul
0
0
Recent years have seen significant efforts to adopt Artificial Intelligence (AI) in healthcare for various use cases, from computer-aided diagnosis to ICU triage. However, the size of AI models has been rapidly growing due to scaling laws and the success of foundational models, which poses an increasing challenge to leverage advanced models in practical applications. It is thus imperative to develop efficient models, especially for deploying AI solutions under resource-constrains or with time sensitivity. One potential solution is to perform model compression, a set of techniques that remove less important model components or reduce parameter precision, to reduce model computation demand. In this work, we demonstrate that model pruning, as a model compression technique, can effectively reduce inference cost for computational and digital pathology based analysis with a negligible loss of analysis performance. To this end, we develop a methodology for pruning the widely used U-Net-style architectures in biomedical imaging, with which we evaluate multiple pruning heuristics on nuclei instance segmentation and classification, and empirically demonstrate that pruning can compress models by at least 70% with a negligible drop in performance.
4/16/2024
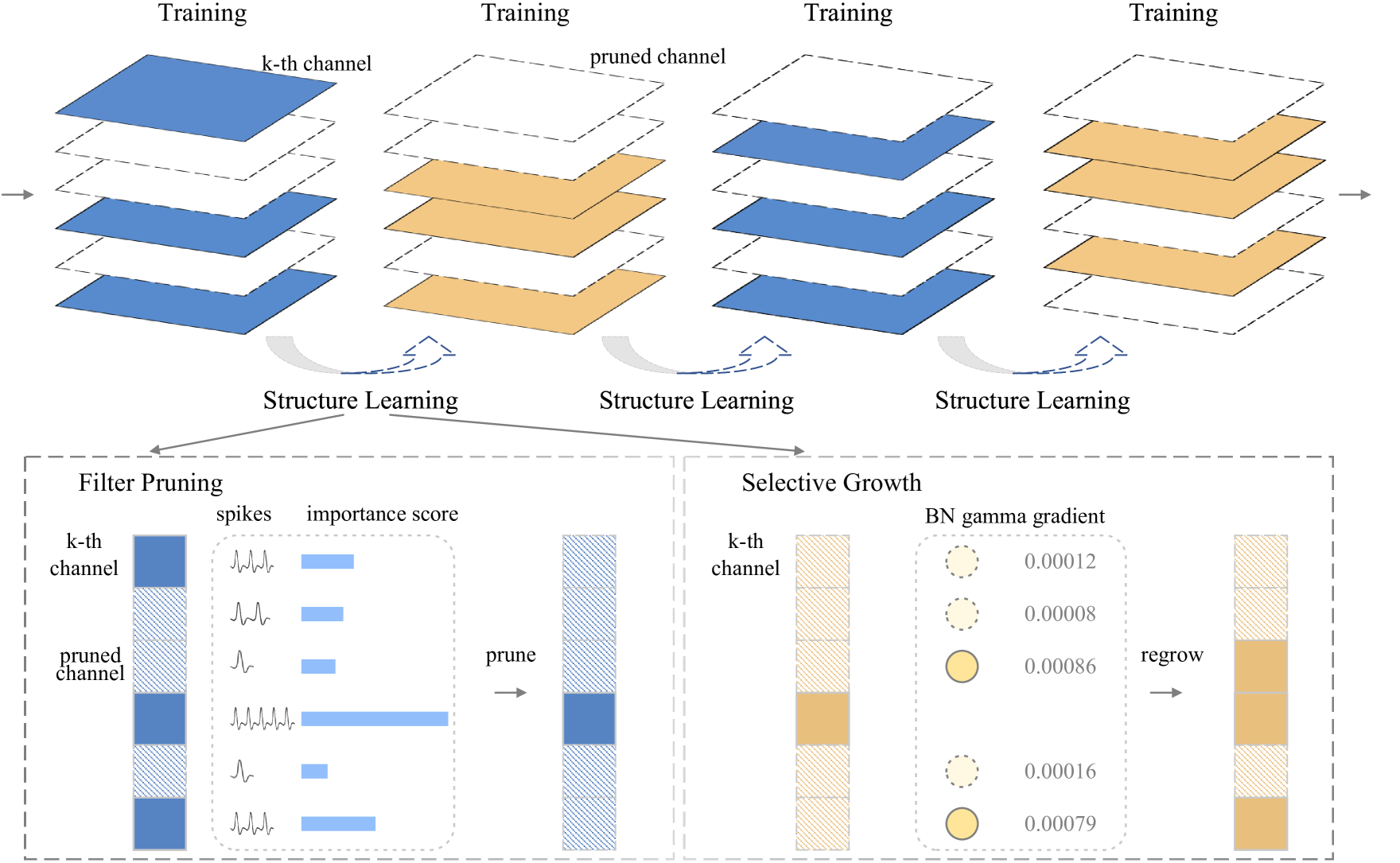
Towards Efficient Deep Spiking Neural Networks Construction with Spiking Activity based Pruning
Yaxin Li, Qi Xu, Jiangrong Shen, Hongming Xu, Long Chen, Gang Pan
0
0
The emergence of deep and large-scale spiking neural networks (SNNs) exhibiting high performance across diverse complex datasets has led to a need for compressing network models due to the presence of a significant number of redundant structural units, aiming to more effectively leverage their low-power consumption and biological interpretability advantages. Currently, most model compression techniques for SNNs are based on unstructured pruning of individual connections, which requires specific hardware support. Hence, we propose a structured pruning approach based on the activity levels of convolutional kernels named Spiking Channel Activity-based (SCA) network pruning framework. Inspired by synaptic plasticity mechanisms, our method dynamically adjusts the network's structure by pruning and regenerating convolutional kernels during training, enhancing the model's adaptation to the current target task. While maintaining model performance, this approach refines the network architecture, ultimately reducing computational load and accelerating the inference process. This indicates that structured dynamic sparse learning methods can better facilitate the application of deep SNNs in low-power and high-efficiency scenarios.
6/4/2024

New!Joint Pruning and Channel-wise Mixed-Precision Quantization for Efficient Deep Neural Networks
Beatrice Alessandra Motetti, Matteo Risso, Alessio Burrello, Enrico Macii, Massimo Poncino, Daniele Jahier Pagliari
0
0
The resource requirements of deep neural networks (DNNs) pose significant challenges to their deployment on edge devices. Common approaches to address this issue are pruning and mixed-precision quantization, which lead to latency and memory occupation improvements. These optimization techniques are usually applied independently. We propose a novel methodology to apply them jointly via a lightweight gradient-based search, and in a hardware-aware manner, greatly reducing the time required to generate Pareto-optimal DNNs in terms of accuracy versus cost (i.e., latency or memory). We test our approach on three edge-relevant benchmarks, namely CIFAR-10, Google Speech Commands, and Tiny ImageNet. When targeting the optimization of the memory footprint, we are able to achieve a size reduction of 47.50% and 69.54% at iso-accuracy with the baseline networks with all weights quantized at 8 and 2-bit, respectively. Our method surpasses a previous state-of-the-art approach with up to 56.17% size reduction at iso-accuracy. With respect to the sequential application of state-of-the-art pruning and mixed-precision optimizations, we obtain comparable or superior results, but with a significantly lowered training time. In addition, we show how well-tailored cost models can improve the cost versus accuracy trade-offs when targeting specific hardware for deployment.
7/2/2024

From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
Xue Geng, Zhe Wang, Chunyun Chen, Qing Xu, Kaixin Xu, Chao Jin, Manas Gupta, Xulei Yang, Zhenghua Chen, Mohamed M. Sabry Aly, Jie Lin, Min Wu, Xiaoli Li
0
0
Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
5/13/2024