Spanning Training Progress: Temporal Dual-Depth Scoring (TDDS) for Enhanced Dataset Pruning
2311.13613
0
0
Abstract
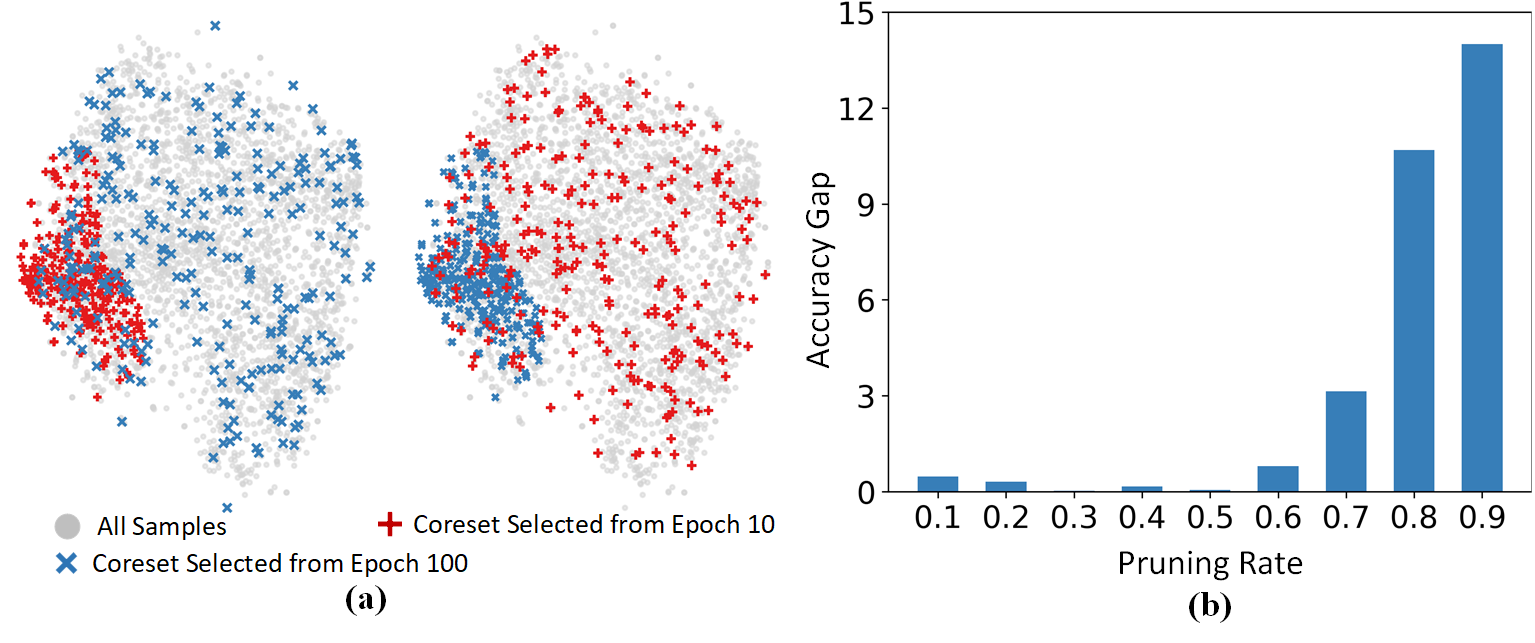
Dataset pruning aims to construct a coreset capable of achieving performance comparable to the original, full dataset. Most existing dataset pruning methods rely on snapshot-based criteria to identify representative samples, often resulting in poor generalization across various pruning and cross-architecture scenarios. Recent studies have addressed this issue by expanding the scope of training dynamics considered, including factors such as forgetting event and probability change, typically using an averaging approach. However, these works struggle to integrate a broader range of training dynamics without overlooking well-generalized samples, which may not be sufficiently highlighted in an averaging manner. In this study, we propose a novel dataset pruning method termed as Temporal Dual-Depth Scoring (TDDS), to tackle this problem. TDDS utilizes a dual-depth strategy to achieve a balance between incorporating extensive training dynamics and identifying representative samples for dataset pruning. In the first depth, we estimate the series of each sample's individual contributions spanning the training progress, ensuring comprehensive integration of training dynamics. In the second depth, we focus on the variability of the sample-wise contributions identified in the first depth to highlight well-generalized samples. Extensive experiments conducted on CIFAR and ImageNet datasets verify the superiority of TDDS over previous SOTA methods. Specifically on CIFAR-100, our method achieves 54.51% accuracy with only 10% training data, surpassing random selection by 7.83% and other comparison methods by at least 12.69%.
Create account to get full access
Overview
- This paper introduces a novel dataset pruning technique called Temporal Dual-Depth Scoring (TDDS) to enhance the efficiency of machine learning model training.
- TDDS leverages both the temporal and depth information of a model's training progress to identify and remove low-quality samples from the dataset, leading to faster convergence and better performance.
- The authors demonstrate the effectiveness of TDDS on several benchmarks, showing significant improvements in training speed and final model accuracy compared to existing dataset pruning methods.
Plain English Explanation
Dataset pruning is the process of selectively removing low-quality or redundant data samples from a training dataset to improve the efficiency and performance of machine learning models. This paper introduces a new approach called Temporal Dual-Depth Scoring (TDDS) that aims to enhance dataset pruning by considering both the temporal and depth information of a model's training progress.
The key idea behind TDDS is that samples that are difficult for a model to learn, or that provide little additional information beyond what the model has already learned, can be identified and removed from the dataset. By doing so, the model can focus on the more valuable samples, leading to faster convergence and better final performance.
To achieve this, TDDS tracks two metrics during training: the temporal score, which measures how quickly a sample is learned, and the depth score, which reflects the sample's position within the model's internal representations. Samples with low temporal and depth scores are considered low-quality and are removed from the dataset.
The authors demonstrate the effectiveness of TDDS on several machine learning benchmarks, including depth completion and pruning of latent diffusion models. They show that TDDS can significantly improve training speed and final model accuracy compared to existing dataset pruning techniques, such as dynamic uncertainty-based pruning and gradient-based pruning.
Technical Explanation
The key technical innovation in this paper is the Temporal Dual-Depth Scoring (TDDS) algorithm for dataset pruning. TDDS leverages two complementary metrics to identify low-quality samples during training:
-
Temporal Score: This score measures how quickly a sample is learned by the model, with samples that are learned faster receiving higher scores.
-
Depth Score: This score reflects the position of a sample within the model's internal representations, with samples that are more central to the model's learned features receiving higher scores.
By combining these temporal and depth scores, TDDS can effectively identify samples that are both easy to learn and provide valuable information to the model. Samples with low scores in both dimensions are then removed from the dataset, allowing the model to focus on the more informative samples and converge faster.
The authors evaluate TDDS on several benchmark tasks, including depth completion and pruning of latent diffusion models. They show that TDDS outperforms existing dataset pruning techniques, such as dynamic uncertainty-based pruning and gradient-based pruning, in terms of both training speed and final model accuracy.
Critical Analysis
The TDDS approach presented in this paper is a promising advancement in dataset pruning, as it leverages both temporal and depth information to identify low-quality samples more effectively than previous methods. However, there are a few potential limitations and areas for further research:
-
Generalization to Other Domains: The experiments in this paper focus on depth completion and latent diffusion models. It would be valuable to test the TDDS approach on a wider range of machine learning tasks and datasets to assess its broader applicability.
-
Computational Overhead: Tracking the temporal and depth scores during training may introduce additional computational overhead, which could offset the benefits of faster convergence. The authors should provide more details on the practical computational cost of TDDS.
-
Interpretability of Scores: While the temporal and depth scores provide a principled way to identify low-quality samples, it may be useful to better understand the underlying factors that contribute to these scores. This could lead to further insights and potential improvements to the pruning algorithm.
-
Interaction with Other Techniques: TDDS could potentially be combined with other dataset pruning or model compression techniques, such as continual temporal domain generalization, to achieve even greater efficiency gains. Exploring these synergies could be a fruitful area for future research.
Overall, the TDDS approach presented in this paper represents an important step forward in dataset pruning and efficient model training. With further research and refinement, it could become a valuable tool in the machine learning practitioner's toolkit.
Conclusion
This paper introduces Temporal Dual-Depth Scoring (TDDS), a novel dataset pruning technique that leverages both the temporal and depth information of a model's training progress to identify and remove low-quality samples from the dataset. The authors demonstrate the effectiveness of TDDS on several benchmark tasks, showing significant improvements in training speed and final model accuracy compared to existing dataset pruning methods.
TDDS is a promising advancement in the field of efficient machine learning, as it allows models to focus on the most informative samples during training, leading to faster convergence and better performance. While there are some potential limitations and areas for further research, the core principles and insights presented in this paper have the potential to have a meaningful impact on the development of more efficient and effective machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Large-scale Dataset Pruning with Dynamic Uncertainty
Muyang He, Shuo Yang, Tiejun Huang, Bo Zhao
0
0
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing computational cost is becoming unaffordable. In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We propose a simple yet effective dataset pruning method by exploring both the prediction uncertainty and training dynamics. We study dataset pruning by measuring the variation of predictions during the whole training process on large-scale datasets, i.e., ImageNet-1K and ImageNet-21K, and advanced models, i.e., Swin Transformer and ConvNeXt. Extensive experimental results indicate that our method outperforms the state of the art and achieves 25% lossless pruning ratio on both ImageNet-1K and ImageNet-21K. The code and pruned datasets are available at https://github.com/BAAI-DCAI/Dataset-Pruning.
6/17/2024
A Study in Dataset Pruning for Image Super-Resolution
Brian B. Moser, Federico Raue, Andreas Dengel
0
0
In image Super-Resolution (SR), relying on large datasets for training is a double-edged sword. While offering rich training material, they also demand substantial computational and storage resources. In this work, we analyze dataset pruning to solve these challenges. We introduce a novel approach that reduces a dataset to a core-set of training samples, selected based on their loss values as determined by a simple pre-trained SR model. By focusing the training on just 50% of the original dataset, specifically on the samples characterized by the highest loss values, we achieve results comparable to or surpassing those obtained from training on the entire dataset. Interestingly, our analysis reveals that the top 5% of samples with the highest loss values negatively affect the training process. Excluding these samples and adjusting the selection to favor easier samples further enhances training outcomes. Our work opens new perspectives to the untapped potential of dataset pruning in image SR. It suggests that careful selection of training data based on loss-value metrics can lead to better SR models, challenging the conventional wisdom that more data inevitably leads to better performance.
6/11/2024
Critical Learning Periods: Leveraging Early Training Dynamics for Efficient Data Pruning
Everlyn Asiko Chimoto, Jay Gala, Orevaoghene Ahia, Julia Kreutzer, Bruce A. Bassett, Sara Hooker
0
0
Neural Machine Translation models are extremely data and compute-hungry. However, not all data points contribute equally to model training and generalization. Data pruning to remove the low-value data points has the benefit of drastically reducing the compute budget without significant drop in model performance. In this paper, we propose a new data pruning technique: Checkpoints Across Time (CAT), that leverages early model training dynamics to identify the most relevant data points for model performance. We benchmark CAT against several data pruning techniques including COMET-QE, LASER and LaBSE. We find that CAT outperforms the benchmarks on Indo-European languages on multiple test sets. When applied to English-German, English-French and English-Swahili translation tasks, CAT achieves comparable performance to using the full dataset, while pruning up to 50% of training data. We inspect the data points that CAT selects and find that it tends to favour longer sentences and sentences with unique or rare words.
6/24/2024
🛸
Test-Time Adaptation for Depth Completion
Hyoungseob Park, Anjali Gupta, Alex Wong
0
0
It is common to observe performance degradation when transferring models trained on some (source) datasets to target testing data due to a domain gap between them. Existing methods for bridging this gap, such as domain adaptation (DA), may require the source data on which the model was trained (often not available), while others, i.e., source-free DA, require many passes through the testing data. We propose an online test-time adaptation method for depth completion, the task of inferring a dense depth map from a single image and associated sparse depth map, that closes the performance gap in a single pass. We first present a study on how the domain shift in each data modality affects model performance. Based on our observations that the sparse depth modality exhibits a much smaller covariate shift than the image, we design an embedding module trained in the source domain that preserves a mapping from features encoding only sparse depth to those encoding image and sparse depth. During test time, sparse depth features are projected using this map as a proxy for source domain features and are used as guidance to train a set of auxiliary parameters (i.e., adaptation layer) to align image and sparse depth features from the target test domain to that of the source domain. We evaluate our method on indoor and outdoor scenarios and show that it improves over baselines by an average of 21.1%.
5/28/2024