Dual-Delayed Asynchronous SGD for Arbitrarily Heterogeneous Data

0
Sign in to get full access
Overview
- This paper proposes a new algorithm called "Dual-Delayed Asynchronous SGD" (DD-ASGD) for training machine learning models on arbitrarily heterogeneous data across distributed devices.
- The key idea is to use two separate delays - one for the model updates and one for the gradient computations - to handle the challenges posed by device heterogeneity.
- The authors demonstrate that DD-ASGD achieves superior performance compared to existing approaches on both synthetic and real-world datasets.
Plain English Explanation
In machine learning, training models on data across many different devices (e.g. phones, laptops, servers) can be challenging due to the inherent variability in the devices' computing power, network speeds, and data distributions. This paper proposes a new algorithm called "Dual-Delayed Asynchronous SGD" (DD-ASGD) that is designed to handle these challenges.
The key idea behind DD-ASGD is to use two separate "delays" - one for applying the model updates, and one for computing the gradients on each device. This allows the algorithm to adapt to the varying speeds and capabilities of the different devices, without getting bogged down by the slowest ones. Similar approaches have been proposed, but DD-ASGD is designed to be more flexible and effective.
Imagine a group of people trying to build a wall together, where some people are much faster at laying bricks than others. The "dual delay" approach in DD-ASGD is like having one person hold off on adding their bricks until enough bricks have been laid, and another person take their time carefully measuring and cutting the bricks before handing them off. This coordination helps the team as a whole make steady progress, rather than being held back by the slowest workers.
Through extensive experiments on both synthetic and real-world datasets, the authors show that DD-ASGD outperforms other state-of-the-art approaches for training models on heterogeneous data. This suggests that the dual-delay mechanism is an effective way to handle the challenges of distributed and decentralized machine learning. Other related work has explored similar ideas, but DD-ASGD appears to be a promising new contribution to this growing field.
Technical Explanation
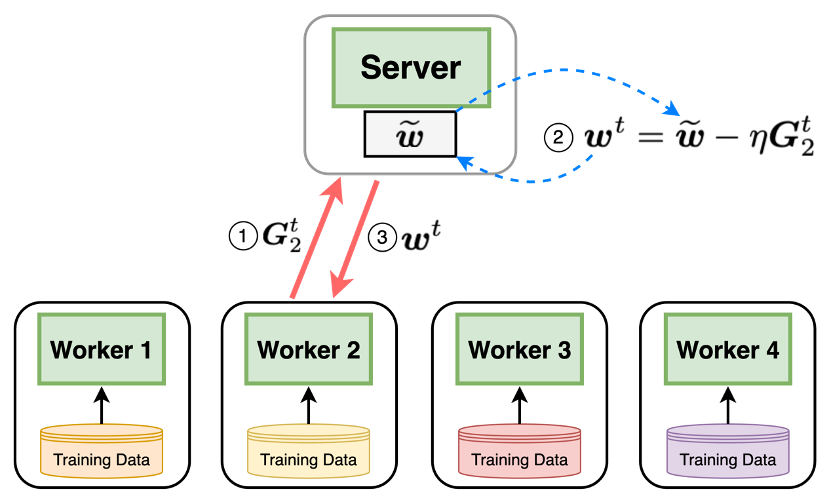
The DD-ASGD algorithm proposed in this paper aims to address the challenges of training machine learning models on arbitrarily heterogeneous data distributed across multiple devices. The key innovation is the use of two separate delays:
-
Model Update Delay: The algorithm maintains a global model, which is updated by aggregating the local model updates from the devices. However, instead of immediately applying these updates, there is a delay before they are incorporated into the global model.
-
Gradient Computation Delay: Similarly, the local gradients computed by each device are not immediately used to update the global model. Instead, there is a separate delay before the gradients are aggregated and applied.
This dual-delay mechanism allows the algorithm to adapt to the varying computation and communication capabilities of the different devices. Slow devices can take their time computing gradients without holding back the overall training process, while fast devices can contribute their updates at a pace that the global model can handle.
The authors provide a thorough theoretical analysis of the convergence properties of DD-ASGD, showing that it can achieve the same order of convergence rates as centralized SGD under certain assumptions. They also demonstrate the empirical effectiveness of DD-ASGD through experiments on both synthetic and real-world datasets, comparing it to state-of-the-art approaches like FedAvg and DASA.
The results indicate that DD-ASGD can outperform these baselines, particularly in scenarios with high levels of device heterogeneity. This suggests that the dual-delay mechanism is an effective way to handle the challenges of distributed and decentralized machine learning.
Critical Analysis
The paper presents a well-designed and rigorously analyzed algorithm for distributed training of machine learning models on heterogeneous data. The key contribution of the dual-delay mechanism is a promising approach to addressing the challenges of device heterogeneity, which is a significant problem in many real-world applications of distributed learning.
However, the paper does not address several important practical considerations:
-
Communication Overhead: While the dual-delay mechanism aims to improve overall training efficiency, it may introduce additional communication overhead between the devices and the central server. The authors do not provide a thorough analysis of the communication costs or strategies to mitigate them.
-
Fault Tolerance: The paper assumes a reliable central server and does not discuss how the algorithm would handle device failures or disconnections during training. Developing fault-tolerant distributed learning algorithms is an important area for further research.
-
Privacy and Security: The paper does not consider the privacy and security implications of the proposed approach, which is crucial for many real-world applications of distributed learning, such as federated learning.
-
Scalability: The theoretical analysis and experiments in the paper focus on a relatively small number of devices. It would be valuable to understand how the algorithm would perform at scale, with hundreds or thousands of devices.
Despite these limitations, the DD-ASGD algorithm presented in this paper is a promising contribution to the field of distributed and decentralized machine learning. Further research addressing the practical concerns mentioned above could help unlock the full potential of this approach.
Conclusion
The "Dual-Delayed Asynchronous SGD for Arbitrarily Heterogeneous Data" paper introduces a novel algorithm that effectively handles the challenges of training machine learning models on distributed, heterogeneous data. By using separate delays for model updates and gradient computations, DD-ASGD can adapt to the varying capabilities of different devices, leading to improved training performance compared to existing approaches.
The theoretical analysis and empirical results presented in the paper demonstrate the potential of this dual-delay mechanism for distributed learning. While there are still practical considerations to address, such as communication overhead, fault tolerance, and scalability, DD-ASGD represents an important step forward in the field of decentralized machine learning. As distributed and edge computing continue to grow in importance, algorithms like DD-ASGD will become increasingly valuable for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual-Delayed Asynchronous SGD for Arbitrarily Heterogeneous Data
Xiaolu Wang, Yuchang Sun, Hoi-To Wai, Jun Zhang
We consider the distributed learning problem with data dispersed across multiple workers under the orchestration of a central server. Asynchronous Stochastic Gradient Descent (SGD) has been widely explored in such a setting to reduce the synchronization overhead associated with parallelization. However, the performance of asynchronous SGD algorithms often depends on a bounded dissimilarity condition among the workers' local data, a condition that can drastically affect their efficiency when the workers' data are highly heterogeneous. To overcome this limitation, we introduce the textit{dual-delayed asynchronous SGD (DuDe-ASGD)} algorithm designed to neutralize the adverse effects of data heterogeneity. DuDe-ASGD makes full use of stale stochastic gradients from all workers during asynchronous training, leading to two distinct time lags in the model parameters and data samples utilized in the server's iterations. Furthermore, by adopting an incremental aggregation strategy, DuDe-ASGD maintains a per-iteration computational cost that is on par with traditional asynchronous SGD algorithms. Our analysis demonstrates that DuDe-ASGD achieves a near-minimax-optimal convergence rate for smooth nonconvex problems, even when the data across workers are extremely heterogeneous. Numerical experiments indicate that DuDe-ASGD compares favorably with existing asynchronous and synchronous SGD-based algorithms.
Read more5/28/2024

0
Distributed Stochastic Gradient Descent with Staleness: A Stochastic Delay Differential Equation Based Framework
Siyuan Yu, Wei Chen, H. Vincent Poor
Distributed stochastic gradient descent (SGD) has attracted considerable recent attention due to its potential for scaling computational resources, reducing training time, and helping protect user privacy in machine learning. However, the staggers and limited bandwidth may induce random computational/communication delays, thereby severely hindering the learning process. Therefore, how to accelerate asynchronous SGD by efficiently scheduling multiple workers is an important issue. In this paper, a unified framework is presented to analyze and optimize the convergence of asynchronous SGD based on stochastic delay differential equations (SDDEs) and the Poisson approximation of aggregated gradient arrivals. In particular, we present the run time and staleness of distributed SGD without a memorylessness assumption on the computation times. Given the learning rate, we reveal the relevant SDDE's damping coefficient and its delay statistics, as functions of the number of activated clients, staleness threshold, the eigenvalues of the Hessian matrix of the objective function, and the overall computational/communication delay. The formulated SDDE allows us to present both the distributed SGD's convergence condition and speed by calculating its characteristic roots, thereby optimizing the scheduling policies for asynchronous/event-triggered SGD. It is interestingly shown that increasing the number of activated workers does not necessarily accelerate distributed SGD due to staleness. Moreover, a small degree of staleness does not necessarily slow down the convergence, while a large degree of staleness will result in the divergence of distributed SGD. Numerical results demonstrate the potential of our SDDE framework, even in complex learning tasks with non-convex objective functions.
Read more6/18/2024

0
Straggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Guojun Xiong, Gang Yan, Shiqiang Wang, Jian Li
With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence and demonstrate its effectiveness via extensive experiments.
Read more7/10/2024
🔍
0
Accelerating Distributed Optimization: A Primal-Dual Perspective on Local Steps
Junchi Yang, Murat Yildirim, Qiu Feng
In distributed machine learning, efficient training across multiple agents with different data distributions poses significant challenges. Even with a centralized coordinator, current algorithms that achieve optimal communication complexity typically require either large minibatches or compromise on gradient complexity. In this work, we tackle both centralized and decentralized settings across strongly convex, convex, and nonconvex objectives. We first demonstrate that a basic primal-dual method, (Accelerated) Gradient Ascent Multiple Stochastic Gradient Descent (GA-MSGD), applied to the Lagrangian of distributed optimization inherently incorporates local updates, because the inner loops of running Stochastic Gradient Descent on the primal variable require no inter-agent communication. Notably, for strongly convex objectives, (Accelerated) GA-MSGD achieves linear convergence in communication rounds despite the Lagrangian being only linear in the dual variables. This is due to a structural property where the dual variable is confined to the span of the coupling matrix, rendering the dual problem strongly concave. When integrated with the Catalyst framework, our approach achieves nearly optimal communication complexity across various settings without the need for minibatches.
Read more8/13/2024