Make a Strong Teacher with Label Assistance: A Novel Knowledge Distillation Approach for Semantic Segmentation

0

Sign in to get full access
Overview
- Introduces a novel knowledge distillation approach called "Label Assistance" for improving the performance of semantic segmentation models
- Leverages the strong label information from a pre-trained "teacher" model to guide the training of a smaller "student" model
- Aims to address the challenge of training effective yet lightweight semantic segmentation models for real-world applications
Plain English Explanation
This research paper presents a new way to train more powerful and efficient models for the task of semantic segmentation. Semantic segmentation is the process of identifying and labeling different objects, people, or other elements in an image. The researchers developed a "Label Assistance" approach that uses the detailed label information from a larger, pre-trained "teacher" model to help train a smaller "student" model.
The key idea is that the student model can learn more effectively by taking advantage of the rich label data provided by the teacher. This "knowledge distillation" process allows the student to mimic the teacher's performance, but with a much more compact and efficient architecture. This could be very useful for deploying high-quality semantic segmentation on resource-constrained devices like mobile phones or embedded systems.
By incorporating the teacher's label guidance, the student model is able to learn more accurate and detailed segmentation, outperforming other knowledge distillation methods. This approach provides a novel way to create strong yet lightweight semantic segmentation models, which can have important applications in areas like self-driving cars, image analysis, and augmented reality.
Technical Explanation
The researchers propose a Label Assistance knowledge distillation framework for semantic segmentation. They start with a pre-trained "teacher" model that provides high-quality segmentation outputs. They then train a smaller "student" model to mimic the teacher's performance, but with a more compact architecture.
The key innovation is that the student model not only learns from the teacher's output predictions, but also receives direct supervision from the teacher's detailed label information. This label-guided knowledge distillation approach allows the student to better capture the fine-grained details and spatial relationships in the segmentation masks.
The researchers also incorporate a language-guided pre-training step, where the student model is first trained on relevant text data to better understand semantic concepts. This multi-task, multi-scale distillation further boosts the student's performance.
Experiments on popular semantic segmentation benchmarks show that the Label Assistance approach outperforms other knowledge distillation methods, allowing the creation of high-accuracy student models that are much smaller and more efficient than the teacher.
Critical Analysis
The paper presents a well-designed and effective knowledge distillation approach for semantic segmentation. The key strength is the use of the teacher's label information to directly guide the student's learning, which appears to be a novel and valuable contribution.
One potential limitation is that the method relies on having access to a strong pre-trained teacher model. In some real-world scenarios, such a teacher model may not be available. The researchers could explore semi-supervised knowledge distillation techniques to address this issue.
Additionally, the paper focuses on semantic segmentation, but the Label Assistance approach could potentially be extended to other dense prediction tasks, such as object detection or instance segmentation. Exploring these applications could further demonstrate the generalizability of the proposed method.
Overall, this research represents an interesting and promising step forward in developing efficient yet high-performing models for real-world computer vision tasks. The Label Assistance approach provides a novel way to leverage the knowledge of a strong teacher model to train more compact student models.
Conclusion
This paper introduces a new knowledge distillation method called "Label Assistance" that leverages a pre-trained teacher model's detailed label information to guide the training of a more efficient student model for semantic segmentation. The key innovation is the direct supervision of the student using the teacher's segmentation labels, which allows the student to better capture the fine-grained spatial details.
Experiments show that this Label Assistance approach outperforms other knowledge distillation techniques, enabling the creation of high-accuracy student models that are substantially smaller and more efficient than the teacher. This work represents an important advancement in developing powerful yet lightweight semantic segmentation models, with potential applications in real-world computer vision systems like self-driving cars, augmented reality, and image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Make a Strong Teacher with Label Assistance: A Novel Knowledge Distillation Approach for Semantic Segmentation
Shoumeng Qiu, Jie Chen, Xinrun Li, Ru Wan, Xiangyang Xue, Jian Pu
In this paper, we introduce a novel knowledge distillation approach for the semantic segmentation task. Unlike previous methods that rely on power-trained teachers or other modalities to provide additional knowledge, our approach does not require complex teacher models or information from extra sensors. Specifically, for the teacher model training, we propose to noise the label and then incorporate it into input to effectively boost the lightweight teacher performance. To ensure the robustness of the teacher model against the introduced noise, we propose a dual-path consistency training strategy featuring a distance loss between the outputs of two paths. For the student model training, we keep it consistent with the standard distillation for simplicity. Our approach not only boosts the efficacy of knowledge distillation but also increases the flexibility in selecting teacher and student models. To demonstrate the advantages of our Label Assisted Distillation (LAD) method, we conduct extensive experiments on five challenging datasets including Cityscapes, ADE20K, PASCAL-VOC, COCO-Stuff 10K, and COCO-Stuff 164K, five popular models: FCN, PSPNet, DeepLabV3, STDC, and OCRNet, and results show the effectiveness and generalization of our approach. We posit that incorporating labels into the input, as demonstrated in our work, will provide valuable insights into related fields. Code is available at https://github.com/skyshoumeng/Label_Assisted_Distillation.
Read more7/19/2024
0
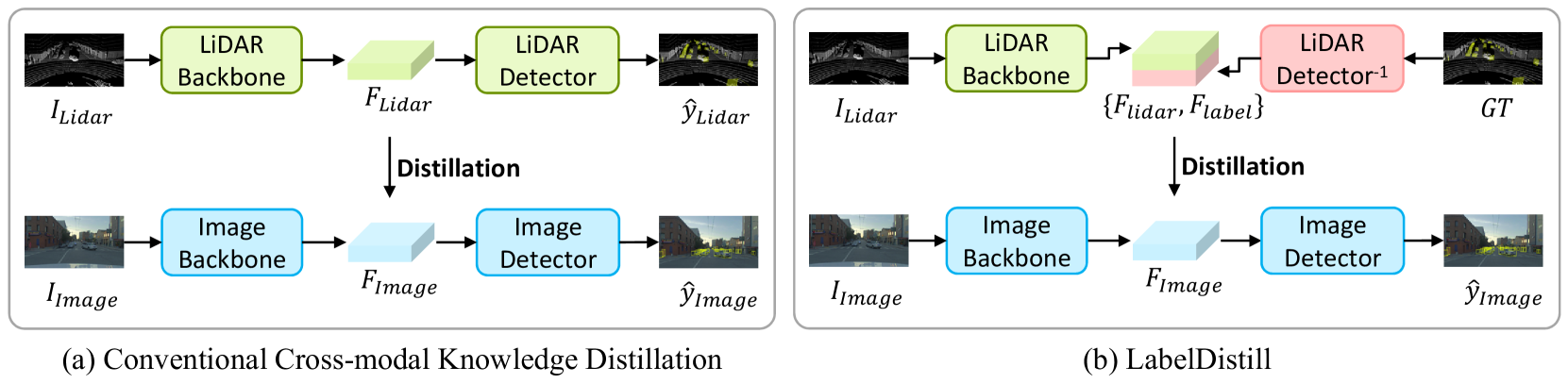
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Sanmin Kim, Youngseok Kim, Sihwan Hwang, Hyeonjun Jeong, Dongsuk Kum
Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Read more7/16/2024
0
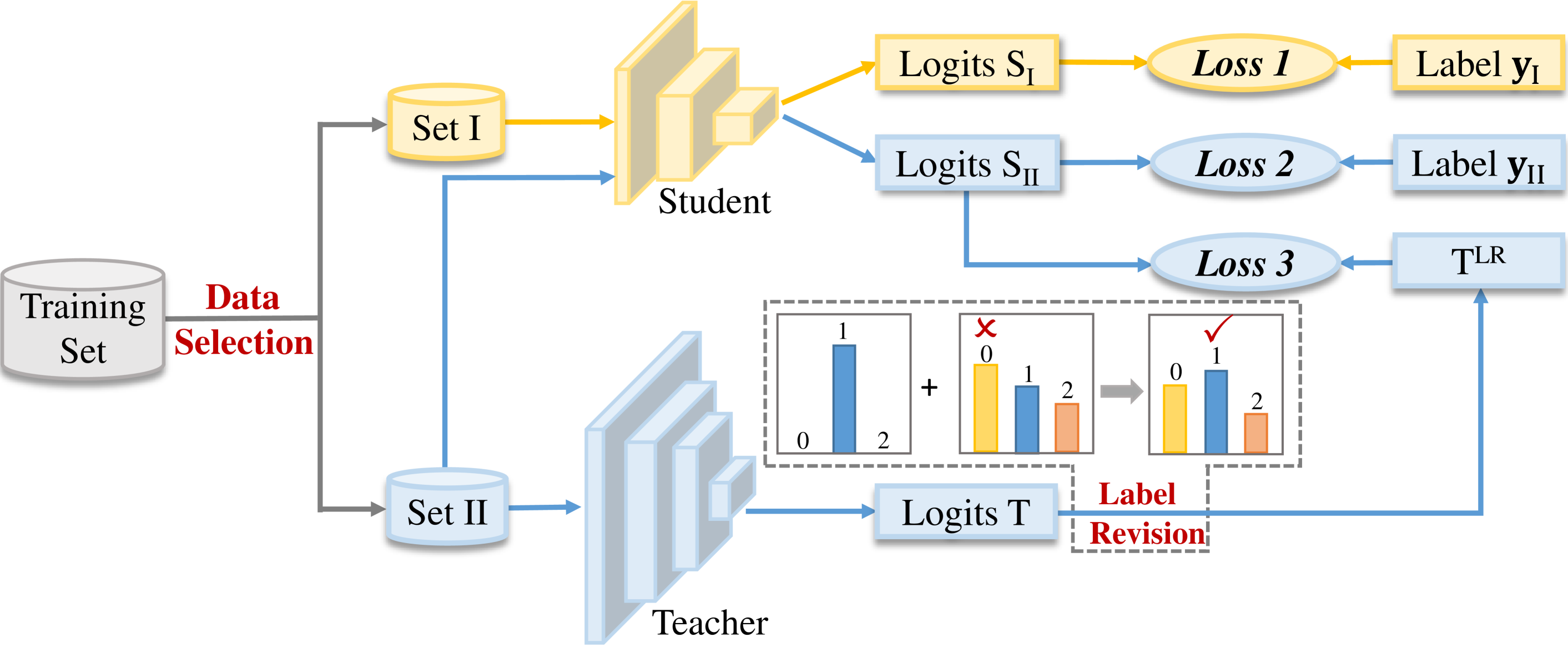
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Read more4/8/2024

0
Lightweight Model Pre-training via Language Guided Knowledge Distillation
Mingsheng Li, Lin Zhang, Mingzhen Zhu, Zilong Huang, Gang Yu, Jiayuan Fan, Tao Chen
This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
Read more6/18/2024