Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model

0
Sign in to get full access
Overview
- The paper proposes a new method called "Dude" for learning context prompts for large vision-language models.
- Dude aims to improve model performance by capturing the dual distributions of prompts and target outputs.
- The paper presents experiments on various datasets and compares Dude to other prompt-based learning approaches.
Plain English Explanation
Dude is a technique for training large vision-language models more effectively. These models are powerful but can be difficult to fine-tune for specific tasks.
The key idea behind Dude is to focus on the "prompts" - the text inputs that are used to guide the model's predictions. Typically, these prompts are manually designed. Dude instead learns the prompts automatically, aiming to capture the natural distribution of prompts and their corresponding outputs.
By modeling both the prompt distribution and the output distribution, Dude can find prompts that lead to better model performance. This is like learning the right "questions to ask" to get the best answers from the model.
The paper shows that Dude outperforms other prompt-based learning approaches on a variety of datasets and tasks, including image captioning and multi-modal reasoning. This suggests Dude is a promising technique for getting the most out of large, powerful vision-language models.
Technical Explanation
Dude works by jointly learning two distributions: the distribution of prompts and the distribution of target outputs. This "dual distribution-aware" approach is the key innovation.
Specifically, Dude learns a context prompt encoder that maps input prompts to a latent representation. It also learns a prompt generator that can produce new prompts from this latent space. These two components are trained together to match the distributions of real prompts and their corresponding outputs.
The paper evaluates Dude on several benchmarks, including image captioning, visual reasoning, and out-of-distribution detection. Dude is shown to outperform other prompt-based learning methods, demonstrating the value of its dual distribution-aware approach.
Critical Analysis
The paper provides a thorough evaluation of Dude, exploring its performance on a range of tasks and comparing it to relevant baselines. However, the authors note that Dude relies on access to a dataset of prompts and their corresponding outputs, which may not always be available in practice.
Additionally, the paper does not delve deeply into the interpretability or explainability of the learned prompts. Understanding why certain prompts are more effective could provide further insights and help guide prompt engineering for other models and tasks.
Further research could explore ways to make Dude more generalizable, such as by learning prompts in a more unsupervised fashion or exploring ways to leverage additional data sources beyond just prompt-output pairs.
Conclusion
The Dude method represents an innovative approach to prompt-based learning for large vision-language models. By jointly modeling the distributions of prompts and outputs, Dude can find prompts that lead to improved performance on a variety of tasks.
The strong empirical results suggest Dude is a promising technique for getting the most out of powerful but challenging-to-fine-tune models. As these large models continue to advance, methods like Dude will be increasingly important for effectively deploying them in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Duy M. H. Nguyen, An T. Le, Trung Q. Nguyen, Nghiem T. Diep, Tai Nguyen, Duy Duong-Tran, Jan Peters, Li Shen, Mathias Niepert, Daniel Sonntag
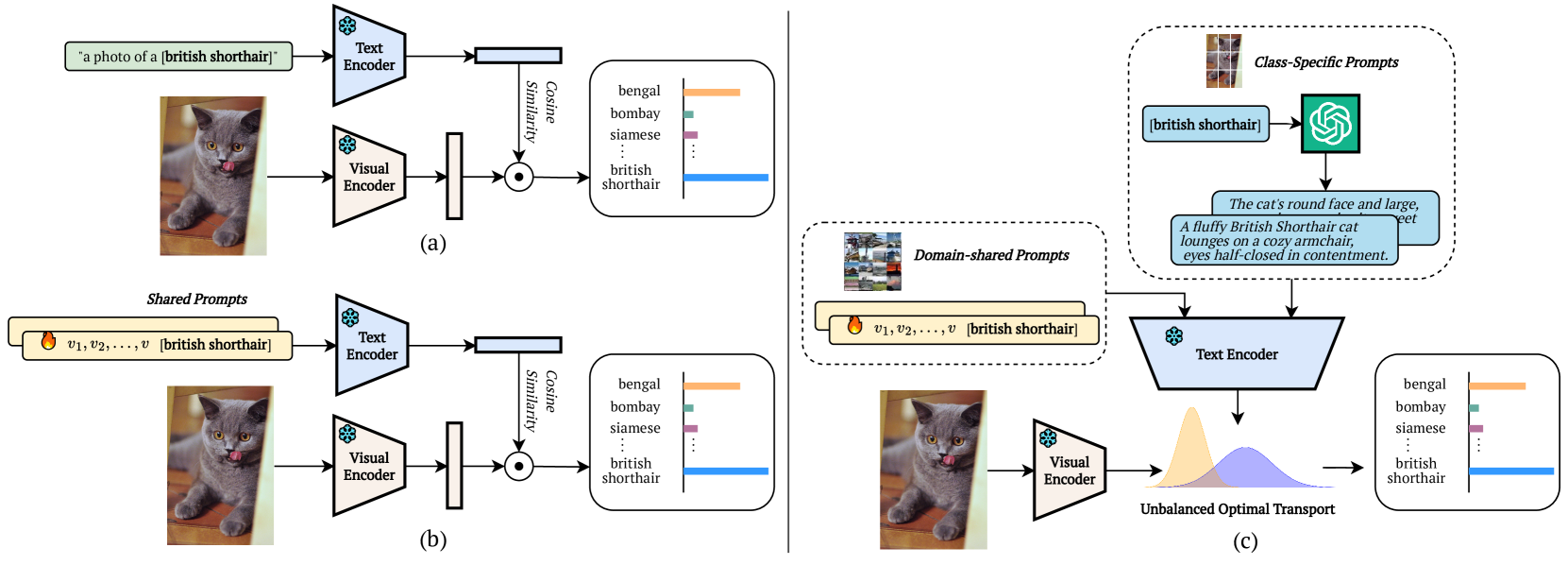
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.
Read more7/8/2024

0
OT-VP: Optimal Transport-guided Visual Prompting for Test-Time Adaptation
Yunbei Zhang, Akshay Mehra, Jihun Hamm
Vision Transformers (ViTs) have demonstrated remarkable capabilities in learning representations, but their performance is compromised when applied to unseen domains. Previous methods either engage in prompt learning during the training phase or modify model parameters at test time through entropy minimization. The former often overlooks unlabeled target data, while the latter doesn't fully address domain shifts. In this work, our approach, Optimal Transport-guided Test-Time Visual Prompting (OT-VP), handles these problems by leveraging prompt learning at test time to align the target and source domains without accessing the training process or altering pre-trained model parameters. This method involves learning a universal visual prompt for the target domain by optimizing the Optimal Transport distance.OT-VP, with only four learned prompt tokens, exceeds state-of-the-art performance across three stylistic datasets-PACS, VLCS, OfficeHome, and one corrupted dataset ImageNet-C. Additionally, OT-VP operates efficiently, both in terms of memory and computation, and is adaptable for extension to online settings.
Read more9/11/2024
0
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
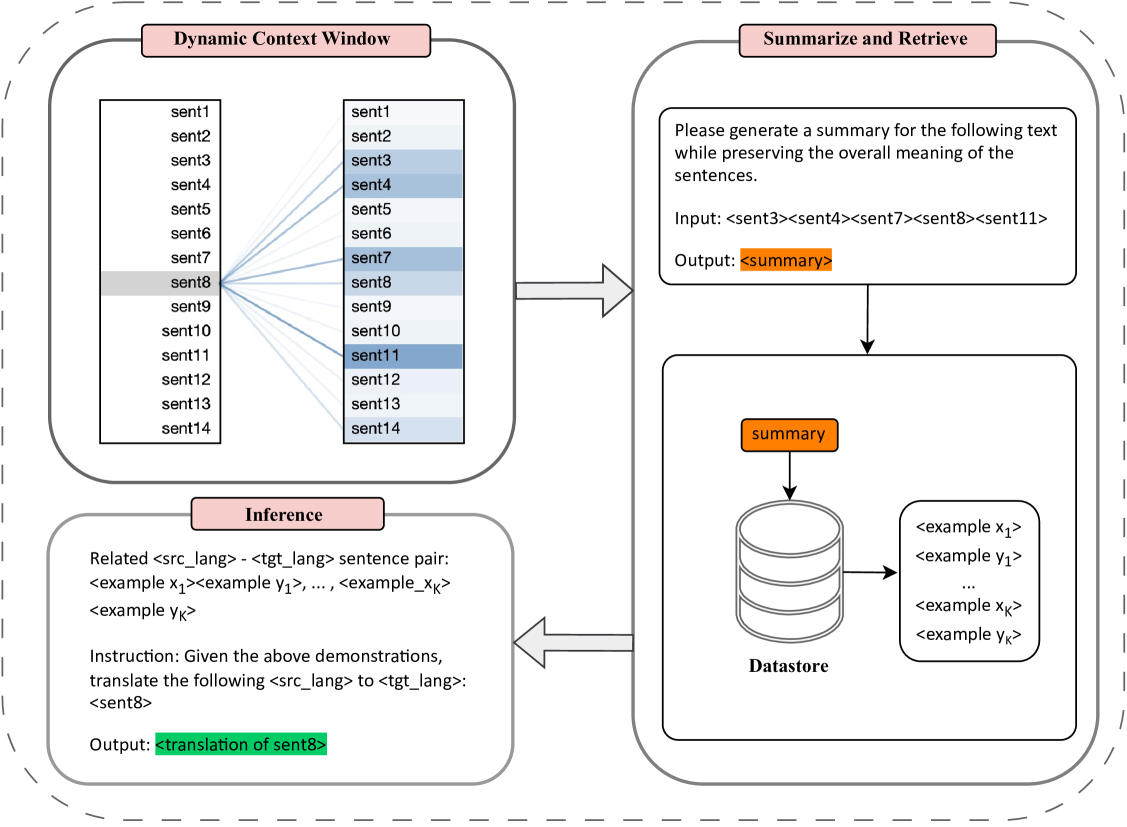
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
Read more6/12/2024

0
New!Mixture of Prompt Learning for Vision Language Models
Yu Du, Tong Niu, Rong Zhao
As powerful pre-trained vision-language models (VLMs) like CLIP gain prominence, numerous studies have attempted to combine VLMs for downstream tasks. Among these, prompt learning has been validated as an effective method for adapting to new tasks, which only requiring a small number of parameters. However, current prompt learning methods face two challenges: first, a single soft prompt struggles to capture the diverse styles and patterns within a dataset; second, fine-tuning soft prompts is prone to overfitting. To address these challenges, we propose a mixture of soft prompt learning method incorporating a routing module. This module is able to capture a dataset's varied styles and dynamically selects the most suitable prompts for each instance. Additionally, we introduce a novel gating mechanism to ensure the router selects prompts based on their similarity to hard prompt templates, which both retaining knowledge from hard prompts and improving selection accuracy. We also implement semantically grouped text-level supervision, initializing each soft prompt with the token embeddings of manually designed templates from its group and applied a contrastive loss between the resulted text feature and hard prompt encoded text feature. This supervision ensures that the text features derived from soft prompts remain close to those from their corresponding hard prompts, preserving initial knowledge and mitigating overfitting. Our method has been validated on 11 datasets, demonstrating evident improvements in few-shot learning, domain generalization, and base-to-new generalization scenarios compared to existing baselines. The code will be available at url{https://anonymous.4open.science/r/mocoop-6387}
Read more9/19/2024