Vision Transformers: From Semantic Segmentation to Dense Prediction

0
👀
Sign in to get full access
Overview
- Vision transformers (ViTs) have emerged as a new approach to image classification, shifting away from traditional convolutional neural networks (CNNs).
- ViTs learn visual representations by processing an image as a sequence of patches, capturing the full receptive field at each layer.
- This work explores the potential of ViTs for dense visual prediction tasks, such as semantic segmentation, object detection, and instance segmentation.
Plain English Explanation
The paper investigates how the global context learning capabilities of ViTs can be leveraged for dense visual prediction tasks. The key idea is that by learning global context at each layer, ViTs may be able to capture stronger long-range dependencies, which are crucial for tasks like semantic segmentation.
The authors first demonstrate that a vanilla ViT architecture, without local convolution or resolution reduction, can outperform CNNs on semantic segmentation tasks. They introduce a model called SETR, which achieves state-of-the-art performance on the ADE20K dataset.
However, the basic ViT architecture falls short for broader dense prediction tasks, such as object detection and instance segmentation, due to its lack of a pyramidal structure, high computational demand, and insufficient local context.
To address these limitations, the authors propose a family of Hierarchical Local-Global (HLG) Transformers, which combine local attention within windows and global attention across windows in a pyramidal architecture. This design allows for more efficient and effective dense visual prediction.
Technical Explanation
The key contributions of this work are:
-
Exploring Global Context Learning with ViTs: The authors demonstrate that a vanilla ViT architecture, without local convolution or resolution reduction, can outperform CNNs on semantic segmentation tasks. They introduce the SETR model, which achieves state-of-the-art performance on the ADE20K dataset.
-
Hierarchical Local-Global (HLG) Transformers: To address the limitations of basic ViTs for broader dense prediction tasks, the authors propose a family of HLG Transformers. These models combine local attention within windows and global attention across windows in a pyramidal architecture, allowing for more efficient and effective dense visual prediction.
The HLG Transformer architecture consists of a series of transformer blocks, each with a local attention module and a global attention module. The local attention module operates on local windows within the feature maps, while the global attention module captures long-range dependencies across the entire feature map.
The authors conduct extensive experiments, evaluating their methods on a variety of dense prediction tasks, including object detection, [instance segmentation], and semantic segmentation. The results demonstrate that the HLG Transformer models achieve appealing performance across these tasks, outperforming state-of-the-art CNN-based approaches.
Critical Analysis
The paper presents a compelling approach to leveraging the global context learning capabilities of ViTs for dense visual prediction tasks. The authors' exploration of the basic ViT architecture for semantic segmentation and the subsequent development of the HLG Transformer models are well-designed and thorough.
One potential limitation is the computational complexity of the HLG Transformer models, which may limit their practical deployment in resource-constrained environments. The authors acknowledge this and suggest that further research into efficient ViT architectures could be beneficial.
Additionally, the paper focuses primarily on a select set of dense prediction tasks, and it would be interesting to see how the HLG Transformer models perform on a broader range of visual understanding tasks, such as image-to-text generation or visual reasoning.
Conclusion
This work presents a significant contribution to the field of visual representation learning by exploring the potential of ViTs for dense visual prediction tasks. The authors' introduction of the SETR model and the HLG Transformer family demonstrates the effectiveness of leveraging global context learning in ViTs for tasks like semantic segmentation, object detection, and instance segmentation.
The findings of this research have important implications for the development of efficient and powerful visual understanding systems, paving the way for further advancements in the field of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Vision Transformers: From Semantic Segmentation to Dense Prediction
Li Zhang, Jiachen Lu, Sixiao Zheng, Xinxuan Zhao, Xiatian Zhu, Yanwei Fu, Tao Xiang, Jianfeng Feng, Philip H. S. Torr
The emergence of vision transformers (ViTs) in image classification has shifted the methodologies for visual representation learning. In particular, ViTs learn visual representation at full receptive field per layer across all the image patches, in comparison to the increasing receptive fields of CNNs across layers and other alternatives (e.g., large kernels and atrous convolution). In this work, for the first time we explore the global context learning potentials of ViTs for dense visual prediction (e.g., semantic segmentation). Our motivation is that through learning global context at full receptive field layer by layer, ViTs may capture stronger long-range dependency information, critical for dense prediction tasks. We first demonstrate that encoding an image as a sequence of patches, a vanilla ViT without local convolution and resolution reduction can yield stronger visual representation for semantic segmentation. For example, our model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission) and performs competitively on Cityscapes. However, the basic ViT architecture falls short in broader dense prediction applications, such as object detection and instance segmentation, due to its lack of a pyramidal structure, high computational demand, and insufficient local context. For tackling general dense visual prediction tasks in a cost-effective manner, we further formulate a family of Hierarchical Local-Global (HLG) Transformers, characterized by local attention within windows and global-attention across windows in a pyramidal architecture. Extensive experiments show that our methods achieve appealing performance on a variety of dense prediction tasks (e.g., object detection and instance segmentation and semantic segmentation) as well as image classification.
Read more8/6/2024

0
Depth-Wise Convolutions in Vision Transformers for Efficient Training on Small Datasets
Tianxiao Zhang, Wenju Xu, Bo Luo, Guanghui Wang
The Vision Transformer (ViT) leverages the Transformer's encoder to capture global information by dividing images into patches and achieves superior performance across various computer vision tasks. However, the self-attention mechanism of ViT captures the global context from the outset, overlooking the inherent relationships between neighboring pixels in images or videos. Transformers mainly focus on global information while ignoring the fine-grained local details. Consequently, ViT lacks inductive bias during image or video dataset training. In contrast, convolutional neural networks (CNNs), with their reliance on local filters, possess an inherent inductive bias, making them more efficient and quicker to converge than ViT with less data. In this paper, we present a lightweight Depth-Wise Convolution module as a shortcut in ViT models, bypassing entire Transformer blocks to ensure the models capture both local and global information with minimal overhead. Additionally, we introduce two architecture variants, allowing the Depth-Wise Convolution modules to be applied to multiple Transformer blocks for parameter savings, and incorporating independent parallel Depth-Wise Convolution modules with different kernels to enhance the acquisition of local information. The proposed approach significantly boosts the performance of ViT models on image classification, object detection and instance segmentation by a large margin, especially on small datasets, as evaluated on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet for image classification, and COCO for object detection and instance segmentation. The source code can be accessed at https://github.com/ZTX-100/Efficient_ViT_with_DW.
Read more8/6/2024

0
DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention
Xiaoya Tang, Bodong Zhang, Beatrice S. Knudsen, Tolga Tasdizen
We here propose a novel hierarchical transformer model that adeptly integrates the feature extraction capabilities of Convolutional Neural Networks (CNNs) with the advanced representational potential of Vision Transformers (ViTs). Addressing the lack of inductive biases and dependence on extensive training datasets in ViTs, our model employs a CNN backbone to generate hierarchical visual representations. These representations are then adapted for transformer input through an innovative patch tokenization. We also introduce a 'scale attention' mechanism that captures cross-scale dependencies, complementing patch attention to enhance spatial understanding and preserve global perception. Our approach significantly outperforms baseline models on small and medium-sized medical datasets, demonstrating its efficiency and generalizability. The components are designed as plug-and-play for different CNN architectures and can be adapted for multiple applications. The code is available at https://github.com/xiaoyatang/DuoFormer.git.
Read more7/22/2024
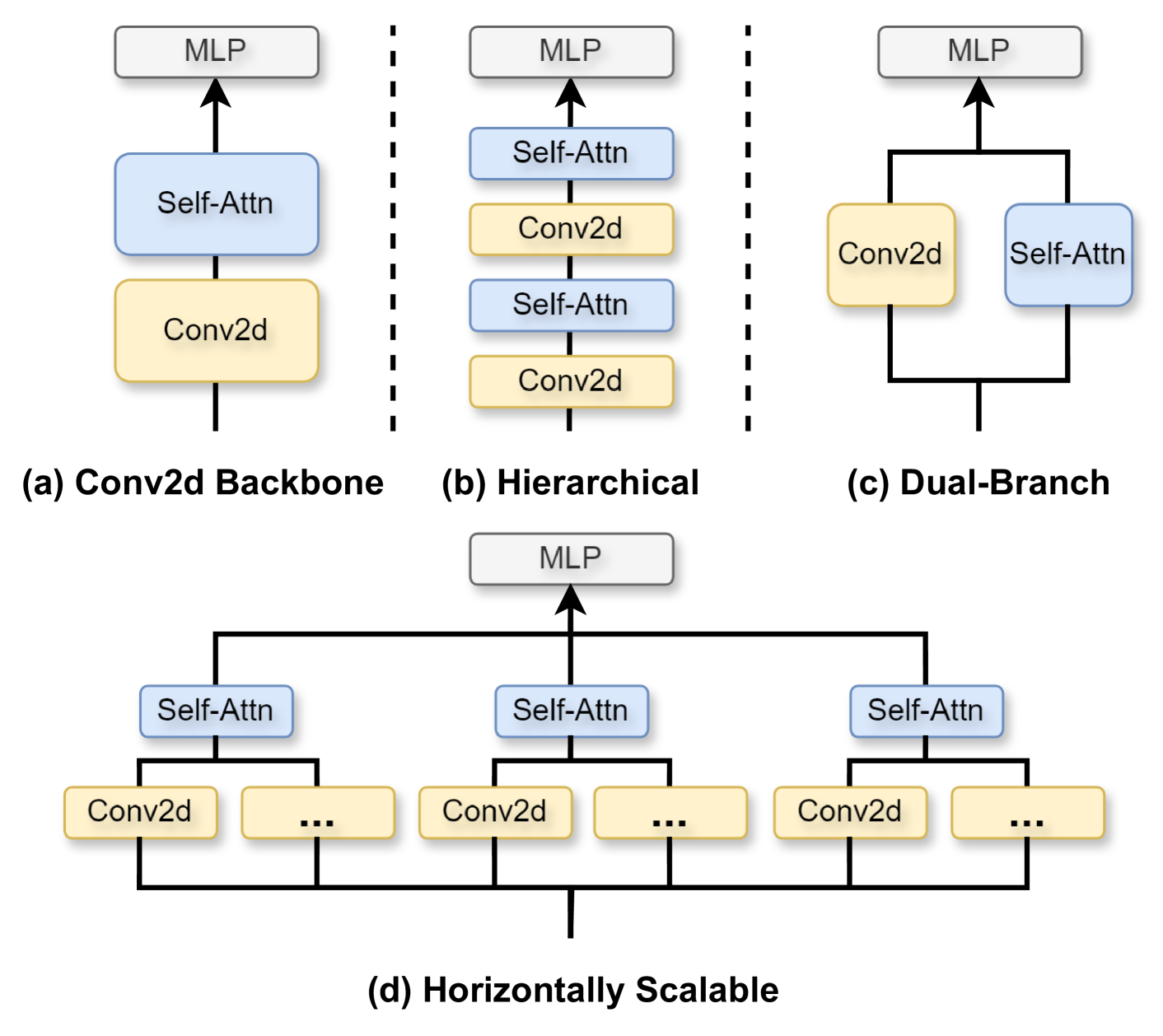
0
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024