PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification

0
Sign in to get full access
Overview
- PartFormer is a novel object re-identification model that leverages diverse representations from Vision Transformers.
- It aims to address the limitations of previous methods by awakening latent part-level representations, enabling more effective object identification.
- The key contributions include a part-aware transformer module and a part-to-part alignment loss, which together enhance the model's ability to capture fine-grained object features.
Plain English Explanation
The paper introduces PartFormer, a new approach to object re-identification that builds upon the strengths of Vision Transformers. Object re-identification is the task of accurately matching objects across different images, which is crucial for applications like surveillance and robotics.
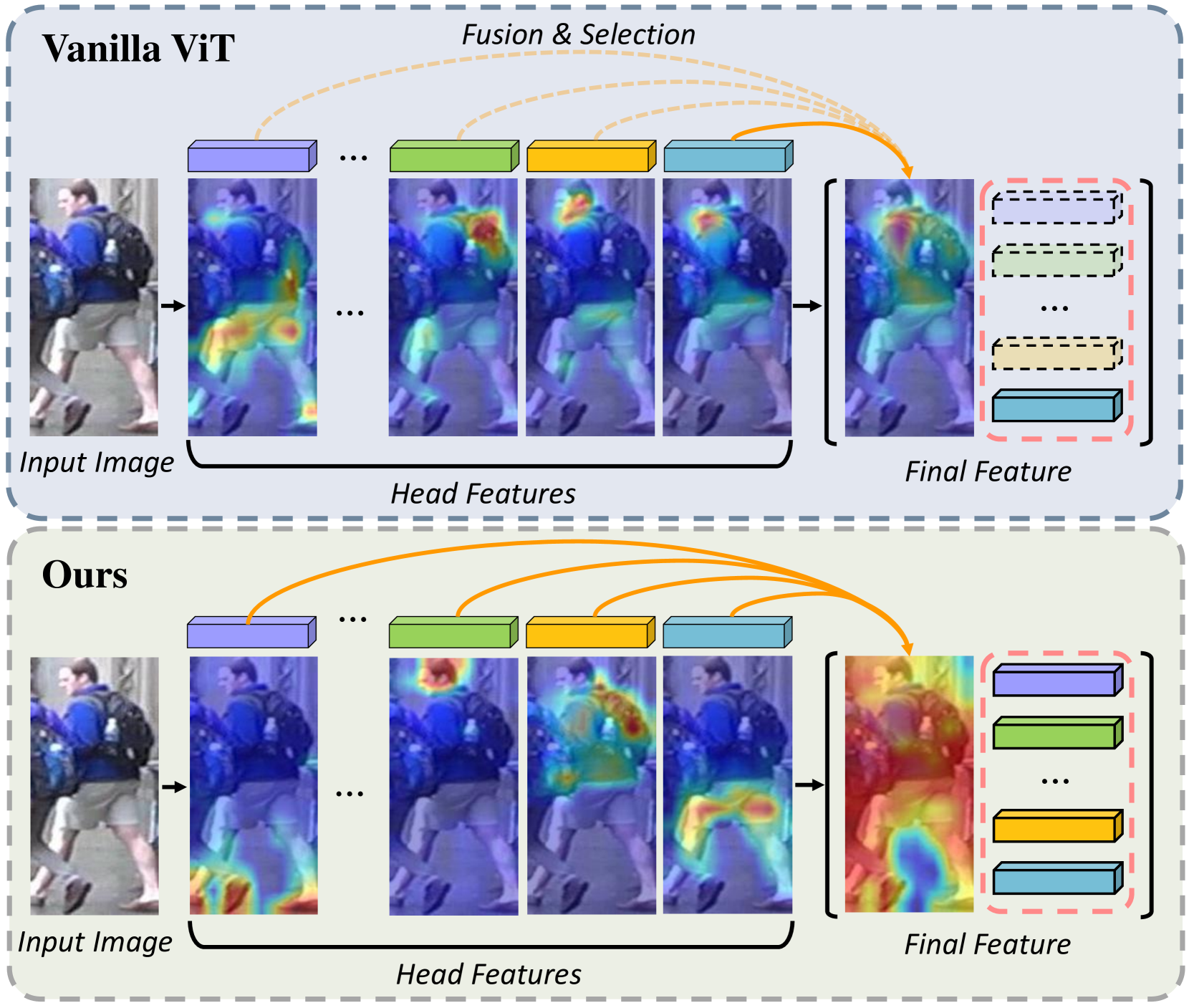
Previous methods have struggled to fully capture the diverse visual features of objects, limiting their performance. PartFormer addresses this by Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification. It does this through a part-aware transformer module that learns to extract fine-grained, part-level representations of objects. Additionally, the model uses a part-to-part alignment loss to ensure these part-level features are well-aligned across different images of the same object.
By leveraging these innovations, PartFormer is able to better recognize objects, even in challenging scenarios where they may appear from different angles or be partially occluded. This could lead to significant improvements in applications like security cameras, self-driving cars, and robotic assistants, where reliable object identification is crucial.
Technical Explanation
The key technical contributions of PartFormer are:
-
Part-Aware Transformer Module: This module is designed to capture part-level representations within the Vision Transformer architecture. It applies a series of part-aware attention mechanisms to extract diverse, fine-grained features from the transformer's intermediate layers.
-
Part-to-Part Alignment Loss: To ensure the part-level representations learned by the model are well-aligned across different images of the same object, the authors introduce a part-to-part alignment loss. This loss function encourages the model to minimize the distance between corresponding part features across images.
-
Part-Aware Projection Head: The final component of PartFormer is a part-aware projection head that aggregates the part-level features into a compact object-level representation, which is used for the final object re-identification task.
The authors evaluate PartFormer on several standard object re-identification benchmarks, demonstrating significant performance improvements over previous state-of-the-art methods. The results highlight the effectiveness of the part-aware transformer module and the part-to-part alignment loss in enhancing the model's ability to capture and align fine-grained object features.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to object re-identification, with several notable strengths:
- The part-aware transformer module is a clever adaptation of the Vision Transformer architecture that allows the model to focus on extracting diverse, part-level representations of objects.
- The part-to-part alignment loss is a novel contribution that directly addresses a key challenge in object re-identification, namely, ensuring that the model's part-level features are well-aligned across different images.
- The experimental results demonstrate significant performance gains over previous methods, underscoring the practical value of the proposed approach.
However, the paper also raises a few potential areas for further exploration:
- The authors do not provide a detailed analysis of the types of objects or scenarios where PartFormer excels the most. Understanding the model's strengths and limitations could guide future research and real-world applications.
- While the part-aware transformer module and part-to-part alignment loss are well-justified, the paper could benefit from a more thorough exploration of alternative part-level feature extraction and alignment techniques.
- The computational efficiency and deployment feasibility of PartFormer are not explicitly addressed, which could be important considerations for certain real-world applications.
Overall, PartFormer represents a meaningful advance in the field of object re-identification, and the ideas presented in this paper could inspire further research into leveraging part-level representations for various computer vision tasks.
Conclusion
The PartFormer model demonstrates the potential of awakening latent, diverse representations from Vision Transformers to tackle the object re-identification challenge. By introducing a part-aware transformer module and a part-to-part alignment loss, the authors have shown how fine-grained, part-level features can be effectively captured and aligned, leading to significant performance improvements.
These innovations could have far-reaching implications for a wide range of applications, from security and surveillance to autonomous navigation and robotic manipulation, where reliable object identification is crucial. As the field of computer vision continues to evolve, research like this that pushes the boundaries of what's possible with transformer-based models is sure to play an important role in driving the next generation of intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification
Lei Tan, Pingyang Dai, Jie Chen, Liujuan Cao, Yongjian Wu, Rongrong Ji
Extracting robust feature representation is critical for object re-identification to accurately identify objects across non-overlapping cameras. Although having a strong representation ability, the Vision Transformer (ViT) tends to overfit on most distinct regions of training data, limiting its generalizability and attention to holistic object features. Meanwhile, due to the structural difference between CNN and ViT, fine-grained strategies that effectively address this issue in CNN do not continue to be successful in ViT. To address this issue, by observing the latent diverse representation hidden behind the multi-head attention, we present PartFormer, an innovative adaptation of ViT designed to overcome the granularity limitations in object Re-ID tasks. The PartFormer integrates a Head Disentangling Block (HDB) that awakens the diverse representation of multi-head self-attention without the typical loss of feature richness induced by concatenation and FFN layers post-attention. To avoid the homogenization of attention heads and promote robust part-based feature learning, two head diversity constraints are imposed: attention diversity constraint and correlation diversity constraint. These constraints enable the model to exploit diverse and discriminative feature representations from different attention heads. Comprehensive experiments on various object Re-ID benchmarks demonstrate the superiority of the PartFormer. Specifically, our framework significantly outperforms state-of-the-art by 2.4% mAP scores on the most challenging MSMT17 dataset.
Read more8/30/2024

0
DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention
Xiaoya Tang, Bodong Zhang, Beatrice S. Knudsen, Tolga Tasdizen
We here propose a novel hierarchical transformer model that adeptly integrates the feature extraction capabilities of Convolutional Neural Networks (CNNs) with the advanced representational potential of Vision Transformers (ViTs). Addressing the lack of inductive biases and dependence on extensive training datasets in ViTs, our model employs a CNN backbone to generate hierarchical visual representations. These representations are then adapted for transformer input through an innovative patch tokenization. We also introduce a 'scale attention' mechanism that captures cross-scale dependencies, complementing patch attention to enhance spatial understanding and preserve global perception. Our approach significantly outperforms baseline models on small and medium-sized medical datasets, demonstrating its efficiency and generalizability. The components are designed as plug-and-play for different CNN architectures and can be adapted for multiple applications. The code is available at https://github.com/xiaoyatang/DuoFormer.git.
Read more7/22/2024

0
Unsupervised Part Discovery via Dual Representation Alignment
Jiahao Xia, Wenjian Huang, Min Xu, Jianguo Zhang, Haimin Zhang, Ziyu Sheng, Dong Xu
Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Read more8/16/2024
0
PAFormer: Part Aware Transformer for Person Re-identification
Hyeono Jung, Jangwon Lee, Jiwon Yoo, Dami Ko, Gyeonghwan Kim
Within the domain of person re-identification (ReID), partial ReID methods are considered mainstream, aiming to measure feature distances through comparisons of body parts between samples. However, in practice, previous methods often lack sufficient awareness of anatomical aspect of body parts, resulting in the failure to capture features of the same body parts across different samples. To address this issue, we introduce textbf{Part Aware Transformer (PAFormer)}, a pose estimation based ReID model which can perform precise part-to-part comparison. In order to inject part awareness to pose tokens, we introduce learnable parameters called `pose token' which estimate the correlation between each body part and partial regions of the image. Notably, at inference phase, PAFormer operates without additional modules related to body part localization, which is commonly used in previous ReID methodologies leveraging pose estimation models. Additionally, leveraging the enhanced awareness of body parts, PAFormer suggests the use of a learning-based visibility predictor to estimate the degree of occlusion for each body part. Also, we introduce a teacher forcing technique using ground truth visibility scores which enables PAFormer to be trained only with visible parts. A set of extensive experiments show that our method outperforms existing approaches on well-known ReID benchmark datasets.
Read more8/13/2024