Dusk Till Dawn: Self-supervised Nighttime Stereo Depth Estimation using Visual Foundation Models
2405.11158
0
0

Abstract
Self-supervised depth estimation algorithms rely heavily on frame-warping relationships, exhibiting substantial performance degradation when applied in challenging circumstances, such as low-visibility and nighttime scenarios with varying illumination conditions. Addressing this challenge, we introduce an algorithm designed to achieve accurate self-supervised stereo depth estimation focusing on nighttime conditions. Specifically, we use pretrained visual foundation models to extract generalised features across challenging scenes and present an efficient method for matching and integrating these features from stereo frames. Moreover, to prevent pixels violating photometric consistency assumption from negatively affecting the depth predictions, we propose a novel masking approach designed to filter out such pixels. Lastly, addressing weaknesses in the evaluation of current depth estimation algorithms, we present novel evaluation metrics. Our experiments, conducted on challenging datasets including Oxford RobotCar and Multi-Spectral Stereo, demonstrate the robust improvements realized by our approach. Code is available at: https://github.com/madhubabuv/dtd
Create account to get full access
Overview
- This paper introduces "Dusk Till Dawn", a self-supervised approach for estimating depth from stereo images captured in low-light conditions.
- The authors leverage visual foundation models, which are pre-trained on large datasets, to extract robust visual features that can handle challenging nighttime scenarios.
- The method does not require any labeled depth data, instead using self-supervision from the stereo image pairs to learn the depth estimation task.
Plain English Explanation
Estimating depth, or the distance of objects from a camera, is an important task in computer vision with many applications like 3D reconstruction and autonomous navigation. However, this task becomes much more challenging in low-light conditions, such as at night.
The researchers behind "Dusk Till Dawn" have developed a new technique to address this problem. Their method uses "visual foundation models" - powerful AI models that have been pre-trained on huge datasets to learn general visual features. By leveraging these foundation models, their system can extract robust visual information even from nighttime stereo image pairs, without requiring any labeled depth data.
The key insight is that the stereo image pairs themselves contain enough information to learn depth, through a process called "self-supervision." The system learns to predict depth by comparing the left and right images and finding the disparity, or difference, between them. Over many training examples, it learns to accurately estimate depth without any human-labeled data.
This self-supervised approach is advantageous because collecting large labeled depth datasets, especially for nighttime scenarios, is extremely difficult and expensive. "Dusk Till Dawn" sidesteps this issue by learning depth estimation in a more automated way, opening up new possibilities for 3D perception in low-light conditions.
Technical Explanation
The "Dusk Till Dawn" method leverages visual foundation models like CLIP and ViT, which have been pre-trained on large image datasets, to extract robust visual features from nighttime stereo image pairs. It then uses a self-supervised learning approach, similar to self-supervised monocular depth estimation and mining supervision from dynamic regions, to learn depth estimation without any labeled depth data.
The key technical components are:
-
Stereo Image Encoding: The left and right nighttime images are passed through the visual foundation model to extract visual features. This provides a robust representation that can handle low-light conditions.
-
Depth Estimation: A depth prediction head is trained to estimate the disparity, or difference, between the left and right features. This disparity is directly related to the depth of objects in the scene.
-
Self-Supervision: The model is trained end-to-end using a self-supervised loss that compares the predicted disparity to the true disparity observed in the stereo image pair. No ground truth depth labels are required.
-
Multi-View Consistency: Additional self-supervised losses are used to enforce consistency between predicted depths from different viewpoints, similar to M-Dollar2-Dollar Depth.
The authors demonstrate that this self-supervised, foundation model-based approach outperforms prior work on nighttime stereo depth estimation benchmarks, paving the way for robust 3D perception in low-light scenarios.
Critical Analysis
The main strength of the "Dusk Till Dawn" approach is its ability to leverage powerful visual foundation models to handle the challenges of nighttime depth estimation without requiring any labeled data. This is a significant advantage over prior work that relied on expensive data collection and annotation efforts.
However, the paper does not fully address the limitations of self-supervised learning. While the method can achieve strong performance on existing benchmarks, it may struggle to generalize to real-world deployment scenarios with diverse lighting conditions and scene types. Additional work may be needed to refine the depth edges and handle sparsely supervised scenarios.
Furthermore, the paper does not provide a detailed analysis of the computational and memory requirements of the approach, which could be a concern for deploying the system on resource-constrained platforms like mobile devices or embedded systems.
Overall, "Dusk Till Dawn" represents an important step forward in self-supervised depth estimation for nighttime scenarios, but further research is needed to address its practical limitations and ensure robust performance in diverse real-world settings.
Conclusion
The "Dusk Till Dawn" paper presents a novel self-supervised approach for estimating depth from stereo images captured in low-light conditions. By leveraging powerful visual foundation models and a self-supervised learning framework, the method can accurately predict depth without any labeled data, addressing a key challenge in 3D perception for nighttime scenarios.
This work has significant implications for applications like autonomous navigation, 3D reconstruction, and computational photography, where robust depth estimation is crucial but can be difficult to achieve in challenging lighting conditions. The authors have demonstrated the potential of self-supervised learning and foundation models to unlock new capabilities in computer vision, paving the way for further advancements in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Haolin Yang, Chaoqiang Zhao, Lu Sheng, Yang Tang
0
0
Nighttime self-supervised monocular depth estimation has received increasing attention in recent years. However, using night images for self-supervision is unreliable because the photometric consistency assumption is usually violated in the videos taken under complex lighting conditions. Even with domain adaptation or photometric loss repair, performance is still limited by the poor supervision of night images on trainable networks. In this paper, we propose a self-supervised nighttime monocular depth estimation method that does not use any night images during training. Our framework utilizes day images as a stable source for self-supervision and applies physical priors (e.g., wave optics, reflection model and read-shot noise model) to compensate for some key day-night differences. With day-to-night data distribution compensation, our framework can be trained in an efficient one-stage self-supervised manner. Though no nighttime images are considered during training, qualitative and quantitative results demonstrate that our method achieves SoTA depth estimating results on the challenging nuScenes-Night and RobotCar-Night compared with existing methods.
4/23/2024
📈
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
0
0
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
4/24/2024

All-day Depth Completion
Vadim Ezhov, Hyoungseob Park, Zhaoyang Zhang, Rishi Upadhyay, Howard Zhang, Chethan Chinder Chandrappa, Achuta Kadambi, Yunhao Ba, Julie Dorsey, Alex Wong
0
0
We propose a method for depth estimation under different illumination conditions, i.e., day and night time. As photometry is uninformative in regions under low-illumination, we tackle the problem through a multi-sensor fusion approach, where we take as input an additional synchronized sparse point cloud (i.e., from a LiDAR) projected onto the image plane as a sparse depth map, along with a camera image. The crux of our method lies in the use of the abundantly available synthetic data to first approximate the 3D scene structure by learning a mapping from sparse to (coarse) dense depth maps along with their predictive uncertainty - we term this, SpaDe. In poorly illuminated regions where photometric intensities do not afford the inference of local shape, the coarse approximation of scene depth serves as a prior; the uncertainty map is then used with the image to guide refinement through an uncertainty-driven residual learning (URL) scheme. The resulting depth completion network leverages complementary strengths from both modalities - depth is sparse but insensitive to illumination and in metric scale, and image is dense but sensitive with scale ambiguity. SpaDe can be used in a plug-and-play fashion, which allows for 25% improvement when augmented onto existing methods to preprocess sparse depth. We demonstrate URL on the nuScenes dataset where we improve over all baselines by an average 11.65% in all-day scenarios, 11.23% when tested specifically for daytime, and 13.12% for nighttime scenes.
5/28/2024
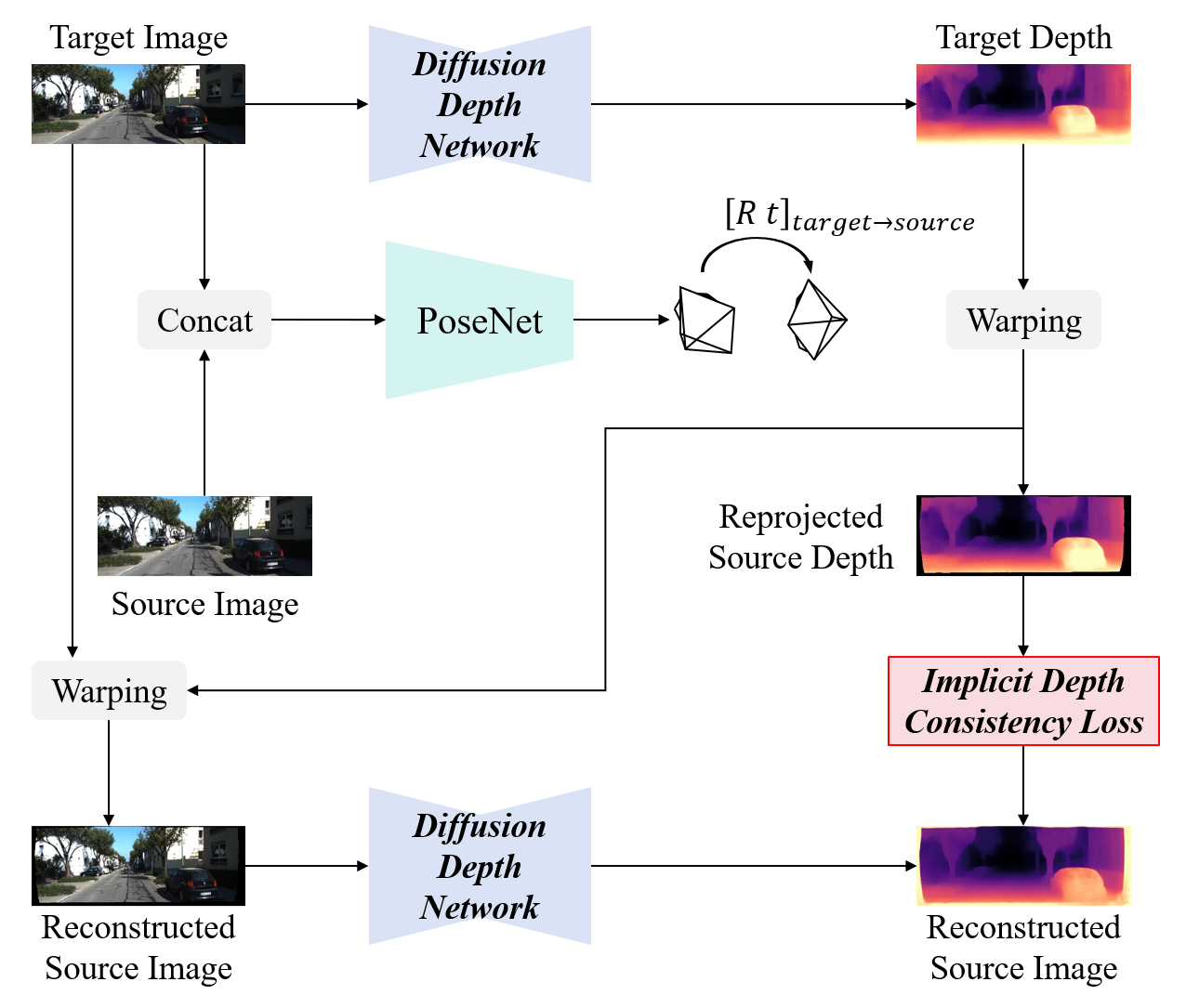
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
0
0
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
6/17/2024