DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
2404.04818
0
0

Abstract
Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
Create account to get full access
Factualized Entity Representation
Overview
- The paper proposes a novel framework called DWE+ (Dual-Way Matching Enhanced) for multimodal entity linking.
- DWE+ aims to effectively leverage both textual and visual information to improve the performance of entity linking.
- The framework introduces a factualized entity representation that captures the semantic consistency between multimodal information and knowledge base entities.
Plain English Explanation Entity linking is the process of associating mentions of named entities in text with their corresponding entries in a knowledge base, such as Wikipedia. Traditionally, this task has relied primarily on textual information. DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking introduces a new approach that also incorporates visual information to enhance the entity linking process.
The key idea is to create a "factualized" representation of entities, which captures the semantic relationship between the textual and visual information associated with an entity and its knowledge base entry. This helps to ensure that the linked entity is consistent with both the text and the accompanying images or other visual cues.
Technical Explanation The DWE+ framework consists of three main components:
- Multimodal Entity Representation: This module learns a joint embedding of the textual and visual information related to an entity, capturing their semantic consistency.
- Dual-Way Matching: DWE+ performs a dual-way matching process, aligning the input multimodal information with the factualized entity representations to identify the most relevant entity.
- Semantic Consistency Optimization: The framework optimizes the semantic consistency between the multimodal input and the selected knowledge base entity, ensuring a coherent and accurate entity linking.
The authors demonstrate the effectiveness of DWE+ through experiments on various multimodal entity linking benchmarks, showing significant improvements over state-of-the-art methods that rely solely on textual information.
Critical Analysis The DWE+ framework provides a promising approach to multimodal entity linking, leveraging both textual and visual information to improve the accuracy and robustness of the task. By emphasizing the semantic consistency between the input and the knowledge base entities, the method aims to address some of the limitations of traditional text-based entity linking approaches.
However, the paper does not extensively discuss the potential limitations or challenges of the DWE+ framework. For instance, it would be valuable to understand how the method performs in scenarios with noisy or ambiguous visual information, or how it scales to large-scale knowledge bases with millions of entities.
Additionally, the paper could benefit from a more thorough analysis of the trade-offs between the increased computational complexity introduced by the multimodal modeling and the gains in entity linking accuracy. This would help researchers and practitioners better understand the practical implications and applicability of the DWE+ approach.
Conclusion The DWE+ framework represents a significant advancement in multimodal entity linking, demonstrating the value of incorporating both textual and visual information to improve the performance of this task. By emphasizing the semantic consistency between the input and the knowledge base entities, the method offers a more comprehensive and accurate approach to entity linking.
While the paper provides a solid technical foundation, further research could explore the limitations and practical considerations of the DWE+ framework, as well as its potential applications in real-world scenarios involving diverse multimodal data sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024
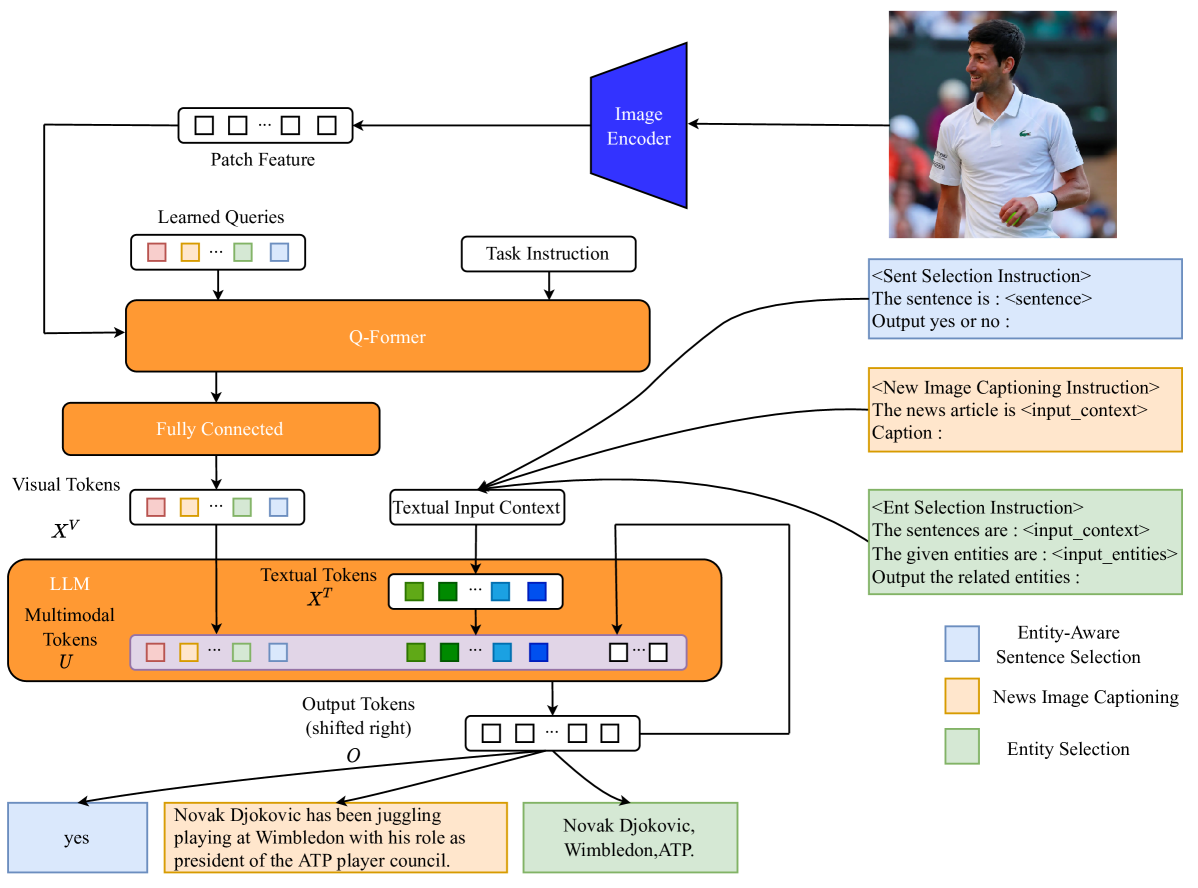
EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Xiaojun Wan
0
0
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
5/7/2024
🌀
Linking Representations with Multimodal Contrastive Learning
Abhishek Arora, Xinmei Yang, Shao-Yu Jheng, Melissa Dell
0
0
Many applications require linking individuals, firms, or locations across datasets. Most widely used methods, especially in social science, do not employ deep learning, with record linkage commonly approached using string matching techniques. Moreover, existing methods do not exploit the inherently multimodal nature of documents. In historical record linkage applications, documents are typically noisily transcribed by optical character recognition (OCR). Linkage with just OCR'ed texts may fail due to noise, whereas linkage with just image crops may also fail because vision models lack language understanding (e.g., of abbreviations or other different ways of writing firm names). To leverage multimodal learning, this study develops CLIPPINGS (Contrastively LInking Pooled Pre-trained Embeddings). CLIPPINGS aligns symmetric vision and language bi-encoders, through contrastive language-image pre-training on document images and their corresponding OCR'ed texts. It then contrastively learns a metric space where the pooled image-text embedding for a given instance is close to embeddings in the same class (e.g., the same firm or location) and distant from embeddings of a different class. Data are linked by treating linkage as a nearest neighbor retrieval problem with the multimodal embeddings. CLIPPINGS outperforms widely used string matching methods by a wide margin in linking mid-20th century Japanese firms across financial documents. A purely self-supervised model - trained only by aligning the embeddings for the image crop of a firm name and its corresponding OCR'ed text - also outperforms popular string matching methods. Fascinatingly, a multimodally pre-trained vision-only encoder outperforms a unimodally pre-trained vision-only encoder, illustrating the power of multimodal pre-training even if only one modality is available for linking at inference time.
6/26/2024
🛠️
Research on Optimization of Natural Language Processing Model Based on Multimodal Deep Learning
Dan Sun, Yaxin Liang, Yining Yang, Yuhan Ma, Qishi Zhan, Erdi Gao
0
0
This project intends to study the image representation based on attention mechanism and multimodal data. By adding multiple pattern layers to the attribute model, the semantic and hidden layers of image content are integrated. The word vector is quantified by the Word2Vec method and then evaluated by a word embedding convolutional neural network. The published experimental results of the two groups were tested. The experimental results show that this method can convert discrete features into continuous characters, thus reducing the complexity of feature preprocessing. Word2Vec and natural language processing technology are integrated to achieve the goal of direct evaluation of missing image features. The robustness of the image feature evaluation model is improved by using the excellent feature analysis characteristics of a convolutional neural network. This project intends to improve the existing image feature identification methods and eliminate the subjective influence in the evaluation process. The findings from the simulation indicate that the novel approach has developed is viable, effectively augmenting the features within the produced representations.
6/14/2024