EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
2402.19404
0
0
Abstract
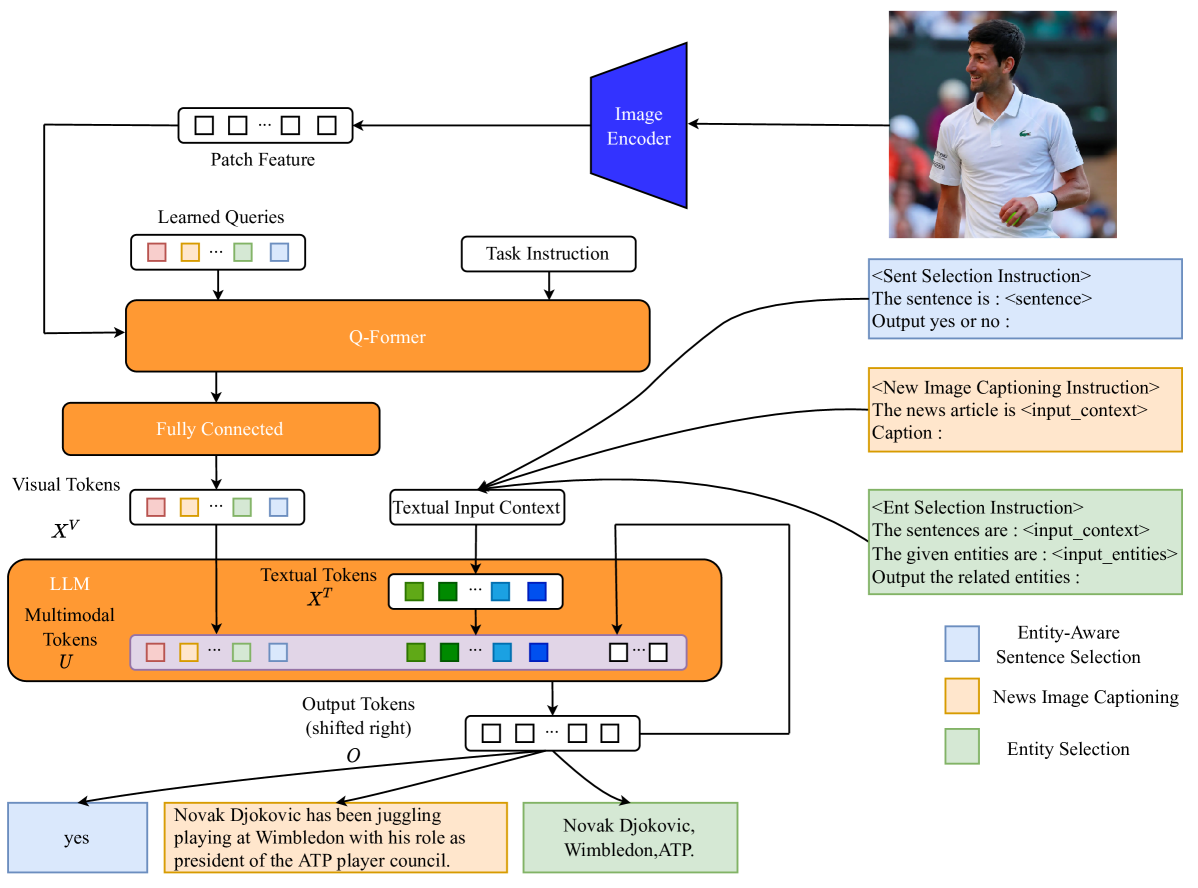
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
Create account to get full access
Overview
- This paper presents an Entity-Aware Multimodal Alignment Framework for news image captioning, which aims to improve the quality and relevance of captions generated for news images.
- The key idea is to leverage entity information extracted from news articles to better align the image and text data, enabling the model to generate more accurate and informative captions.
- The framework incorporates an entity-aware attention mechanism and a cross-modal alignment module to capture the relationships between visual elements, text, and entities.
- Experiments on the COCO-CN dataset demonstrate the effectiveness of the proposed approach in generating more coherent and informative captions compared to state-of-the-art models.
Plain English Explanation
The paper introduces a new framework for automatically generating captions for news images. The key innovation is the use of entity information extracted from the news articles associated with the images. By understanding the entities (people, places, events, etc.) mentioned in the text, the model can better align the image and text data, leading to more accurate and relevant captions.
For example, if an image shows the President giving a speech, the model can leverage the entity "President" extracted from the article text to generate a more informative caption like "The President delivers a speech at the podium" rather than a more generic caption like "A person standing at a podium."
The framework includes two main components: an entity-aware attention mechanism that focuses on the relevant visual elements based on the extracted entities, and a cross-modal alignment module that explicitly models the relationships between the image, text, and entities. By incorporating these entity-aware capabilities, the model can generate more coherent and informative captions for news images.
Technical Explanation
The proposed Entity-Aware Multimodal Alignment Framework consists of several key components:
- Visual Encoder: A convolutional neural network (CNN) that encodes the input image into a set of visual features.
- Text Encoder: A transformer-based language model that encodes the news article text into a sequence of text features.
- Entity Extractor: A module that identifies the entities (people, places, organizations, etc.) mentioned in the news article text.
- Entity-Aware Attention: An attention mechanism that aligns the visual features with the relevant entities, allowing the model to focus on the most salient visual elements when generating the caption.
- Cross-Modal Alignment: A module that explicitly models the relationships between the image, text, and entities, ensuring that the generated captions are coherent and aligned with the multimodal input.
The model is trained end-to-end on the COCO-CN dataset, which consists of news images paired with their corresponding articles and captions. The entity-aware attention and cross-modal alignment components help the model generate more accurate and informative captions compared to previous state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed framework, including comparisons to several baseline models and ablation studies to understand the contributions of the key components. The results demonstrate the effectiveness of the entity-aware approach, particularly for news images where the entities mentioned in the text play a crucial role in the image content.
One potential limitation of the framework is that it relies on the accuracy of the entity extraction module, which could be a source of error if the entity recognition is not reliable. Additionally, the framework may not be as effective for news images where the entities are not well-aligned with the visual content or where the captions require more complex reasoning beyond just entity-based alignment.
Further research could explore ways to make the entity extraction more robust or to incorporate additional multimodal features beyond just entities to enhance the caption generation capabilities. Integrating language models with grounded visual reasoning could also be a promising direction for improving the multimodal alignment and caption quality.
Conclusion
The proposed Entity-Aware Multimodal Alignment Framework for news image captioning represents a significant advancement in the field by leveraging entity information to better align the visual and textual modalities. The framework's ability to generate more accurate and informative captions has important implications for a wide range of applications, such as news summarization, image retrieval, and content understanding.
The demonstrated success of the entity-aware approach highlights the importance of incorporating structured knowledge and semantic understanding into multimodal models, which is an active area of research in the broader field of large language and vision models. As the complexity and diversity of multimodal data continue to grow, frameworks like the one presented in this paper will play a crucial role in bridging the gap between visual and textual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
0
0
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
7/2/2024

Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Xin Wang, Fangfang Liu, Zheng Li, Caili Guo
0
0
Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
6/7/2024

ANCHOR: LLM-driven News Subject Conditioning for Text-to-Image Synthesis
Aashish Anantha Ramakrishnan, Sharon X. Huang, Dongwon Lee
0
0
Text-to-Image (T2I) Synthesis has made tremendous strides in enhancing synthesized image quality, but current datasets evaluate model performance only on descriptive, instruction-based prompts. Real-world news image captions take a more pragmatic approach, providing high-level situational and Named-Entity (NE) information and limited physical object descriptions, making them abstractive. To evaluate the ability of T2I models to capture intended subjects from news captions, we introduce the Abstractive News Captions with High-level cOntext Representation (ANCHOR) dataset, containing 70K+ samples sourced from 5 different news media organizations. With Large Language Models (LLM) achieving success in language and commonsense reasoning tasks, we explore the ability of different LLMs to identify and understand key subjects from abstractive captions. Our proposed method Subject-Aware Finetuning (SAFE), selects and enhances the representation of key subjects in synthesized images by leveraging LLM-generated subject weights. It also adapts to the domain distribution of news images and captions through custom Domain Fine-tuning, outperforming current T2I baselines on ANCHOR. By launching the ANCHOR dataset, we hope to motivate research in furthering the Natural Language Understanding (NLU) capabilities of T2I models.
4/17/2024
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024